标签:
Apache HBase是一个分布式的、面向列的开源数据库,它可以让我们随机的、实时的访问大数据。但是怎样有效的将数据导入到HBase呢?HBase有多种导入数据的方法,最直接的方法就是在MapReduce作业中使用TableOutputFormat作为输出,或者使用标准的客户端API,但是这些都不是非常有效的方法。
Bulkload利用MapReduce作业输出HBase内部数据格式的表数据,然后将生成的StoreFiles直接导入到集群中。与使用HBase API相比,使用Bulkload导入数据占用更少的CPU和网络资源。
Bulkload过程主要包括三部分:
1.从数据源(通常是文本文件或其他的数据库)提取数据并上传到HDFS
这一步不在HBase的考虑范围内,不管数据源是什么,只要在进行下一步之前将数据上传到HDFS即可。
2.利用一个MapReduce作业准备数据
这一步需要一个MapReduce作业,并且大多数情况下还需要我们自己编写Map函数,而Reduce函数不需要我们考虑,由HBase提供。该作业需要使用rowkey(行键)作为输出Key,KeyValue、Put或者Delete作为输出Value。MapReduce作业需要使用HFileOutputFormat2来生成HBase数据文件。为了有效的导入数据,需要配置HFileOutputFormat2使得每一个输出文件都在一个合适的区域中。为了达到这个目的,MapReduce作业会使用Hadoop的TotalOrderPartitioner类根据表的key值将输出分割开来。HFileOutputFormat2的方法configureIncrementalLoad()会自动的完成上面的工作。
3.告诉RegionServers数据的位置并导入数据
这一步是最简单的,通常需要使用LoadIncrementalHFiles(更为人所熟知是completebulkload工具),将文件在HDFS上的位置传递给它,它就会利用RegionServer将数据导入到相应的区域。
下图简单明确的说明了整个过程
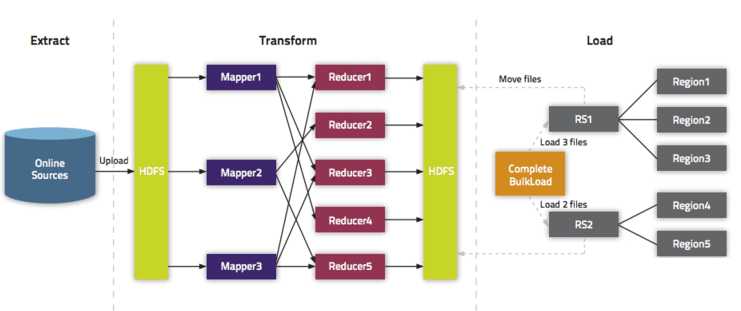
注意:在进行BulkLoad之前,要在HBase中创建与程序中同名且结构相同的空表
Java实现如下:
1 BulkLoadDriver.java
2
3 import org.apache.hadoop.conf.Configuration;
4 import org.apache.hadoop.conf.Configured;
5 import org.apache.hadoop.fs.FileSystem;
6 import org.apache.hadoop.fs.Path;
7 import org.apache.hadoop.hbase.HBaseConfiguration;
8 import org.apache.hadoop.hbase.TableName;
9 import org.apache.hadoop.hbase.client.Connection;
10 import org.apache.hadoop.hbase.client.ConnectionFactory;
11 import org.apache.hadoop.hbase.client.Put;
12 import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
13 import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2;
14 import org.apache.hadoop.mapreduce.Job;
15 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
16 import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
17 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
18 import org.apache.hadoop.util.Tool;
19 import org.apache.hadoop.util.ToolRunner;
20 /**
21 * Created by shaobo on 15-6-9.
22 */
23 public class BulkLoadDriver extends Configured implements Tool {
24 private static final String DATA_SEPERATOR = "\\s+";
25 private static final String TABLE_NAME = "temperature";//表名
26 private static final String COLUMN_FAMILY_1="date";//列组1
27 private static final String COLUMN_FAMILY_2="tempPerHour";//列组2
28 public static void main(String[] args) {
29 try {
30 int response = ToolRunner.run(HBaseConfiguration.create(), new BulkLoadDriver(), args);
31 if(response == 0) {
32 System.out.println("Job is successfully completed...");
33 } else {
34 System.out.println("Job failed...");
35 }
36 } catch(Exception exception) {
37 exception.printStackTrace();
38 }
39 }
40 public int run(String[] args) throws Exception {
41 String outputPath = args[1];
42 /**
43 * 设置作业参数
44 */
45 Configuration configuration = getConf();
46 configuration.set("data.seperator", DATA_SEPERATOR);
47 configuration.set("hbase.table.name", TABLE_NAME);
48 configuration.set("COLUMN_FAMILY_1", COLUMN_FAMILY_1);
49 configuration.set("COLUMN_FAMILY_2", COLUMN_FAMILY_2);
50 Job job = Job.getInstance(configuration, "Bulk Loading HBase Table::" + TABLE_NAME);
51 job.setJarByClass(BulkLoadDriver.class);
52 job.setInputFormatClass(TextInputFormat.class);
53 job.setMapOutputKeyClass(ImmutableBytesWritable.class);//指定输出键类
54 job.setMapOutputValueClass(Put.class);//指定输出值类
55 job.setMapperClass(BulkLoadMapper.class);//指定Map函数
56 FileInputFormat.addInputPaths(job, args[0]);//输入路径
57 FileSystem fs = FileSystem.get(configuration);
58 Path output = new Path(outputPath);
59 if (fs.exists(output)) {
60 fs.delete(output, true);//如果输出路径存在,就将其删除
61 }
62 FileOutputFormat.setOutputPath(job, output);//输出路径
63 Connection connection = ConnectionFactory.createConnection(configuration);
64 TableName tableName = TableName.valueOf(TABLE_NAME);
65 HFileOutputFormat2.configureIncrementalLoad(job, connection.getTable(tableName), connection.getRegionLocator(tableName));
66 job.waitForCompletion(true);
67 if (job.isSuccessful()){
68 HFileLoader.doBulkLoad(outputPath, TABLE_NAME);//导入数据
69 return 0;
70 } else {
71 return 1;
72 }
73 }
74 }
1 BulkLoadMapper.java
2
3 import org.apache.hadoop.conf.Configuration;
4 import org.apache.hadoop.hbase.client.Put;
5 import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
6 import org.apache.hadoop.hbase.util.Bytes;
7 import org.apache.hadoop.io.LongWritable;
8 import org.apache.hadoop.io.Text;
9 import org.apache.hadoop.mapreduce.Mapper;
10 /**
11 * Created by shaobo on 15-6-9.
12 */
13 public class BulkLoadMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put> {
14 private String hbaseTable;
15 private String dataSeperator;
16 private String columnFamily1;
17 private String columnFamily2;
18 public void setup(Context context) {
19 Configuration configuration = context.getConfiguration();//获取作业参数
20 hbaseTable = configuration.get("hbase.table.name");
21 dataSeperator = configuration.get("data.seperator");
22 columnFamily1 = configuration.get("COLUMN_FAMILY_1");
23 columnFamily2 = configuration.get("COLUMN_FAMILY_2");
24 }
25 public void map(LongWritable key, Text value, Context context){
26 try {
27 String[] values = value.toString().split(dataSeperator);
28 ImmutableBytesWritable rowKey = new ImmutableBytesWritable(values[0].getBytes());
29 Put put = new Put(Bytes.toBytes(values[0]));
30 put.addColumn(Bytes.toBytes(columnFamily1), Bytes.toBytes("month"), Bytes.toBytes(values[1]));
31 put.addColumn(Bytes.toBytes(columnFamily1), Bytes.toBytes("day"), Bytes.toBytes(values[2]));
32 for (int i = 3; i < values.length; ++i){
33 put.addColumn(Bytes.toBytes(columnFamily2), Bytes.toBytes("hour : " + i), Bytes.toBytes(values[i]));
34 }
35 context.write(rowKey, put);
36 } catch(Exception exception) {
37 exception.printStackTrace();
38 }
39 }
40
41 }
1 HFileLoader.java
2
3 import org.apache.hadoop.conf.Configuration;
4 import org.apache.hadoop.fs.Path;
5 import org.apache.hadoop.hbase.HBaseConfiguration;
6 import org.apache.hadoop.hbase.client.HTable;
7 import org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles;
8 /**
9 * Created by shaobo on 15-6-9.
10 */
11 public class HFileLoader {
12 public static void doBulkLoad(String pathToHFile, String tableName){
13 try {
14 Configuration configuration = new Configuration();
15 HBaseConfiguration.addHbaseResources(configuration);
16 LoadIncrementalHFiles loadFfiles = new LoadIncrementalHFiles(configuration);
17 HTable hTable = new HTable(configuration, tableName);//指定表名
18 loadFfiles.doBulkLoad(new Path(pathToHFile), hTable);//导入数据
19 System.out.println("Bulk Load Completed..");
20 } catch(Exception exception) {
21 exception.printStackTrace();
22 }
23 }
24
25 }
程序编译打包,提交到Hadoop运行
HADOOP_CLASSPATH=$(hbase mapredcp):/path/to/hbase/conf hadoop jar BulkLoad.jar inputpath outputpath1
上述命令用法可参考 44. HBase, MapReduce, and the CLASSPATH
作业运行情况:
12/10/16 14:31:07 INFO mapreduce.HFileOutputFormat2: Looking up current regions for table temperature(表名)
12/10/16 14:31:07 INFO mapreduce.HFileOutputFormat2: Configuring 1 reduce partitions to match current region count
12/10/16 14:31:07 INFO mapreduce.HFileOutputFormat2: Writing partition information to /home/shaobo/hadoop/tmp/partitions_5d464f1e-d412-4dbe-bb98-367f8431bdc9
12/10/16 14:31:07 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library
12/10/16 14:31:07 INFO compress.CodecPool: Got brand-new compressor [.deflate]
12/10/16 14:31:08 INFO mapreduce.HFileOutputFormat2: Incremental table temperature(表名) output configured.
12/10/16 14:31:08 INFO client.RMProxy: Connecting to ResourceManager at localhost/127.0.0.1:8032
12/10/16 14:31:15 INFO input.FileInputFormat: Total input paths to process : 2
12/10/16 14:31:15 INFO mapreduce.JobSubmitter: number of splits:2
12/10/16 14:31:16 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1434262360688_0002
12/10/16 14:31:17 INFO impl.YarnClientImpl: Submitted application application_1434262360688_0002
12/10/16 14:31:17 INFO mapreduce.Job: The url to track the job: http://shaobo-ThinkPad-E420:8088/proxy/application_1434262360688_0002/
12/10/16 14:31:17 INFO mapreduce.Job: Running job: job_1434262360688_0002
12/10/16 14:31:28 INFO mapreduce.Job: Job job_1434262360688_0002 running in uber mode : false
12/10/16 14:31:28 INFO mapreduce.Job: map 0% reduce 0%
12/10/16 14:32:24 INFO mapreduce.Job: map 49% reduce 0%
12/10/16 14:32:37 INFO mapreduce.Job: map 67% reduce 0%
12/10/16 14:32:43 INFO mapreduce.Job: map 100% reduce 0%
12/10/16 14:33:39 INFO mapreduce.Job: map 100% reduce 67%
12/10/16 14:33:42 INFO mapreduce.Job: map 100% reduce 70%
12/10/16 14:33:45 INFO mapreduce.Job: map 100% reduce 88%
12/10/16 14:33:48 INFO mapreduce.Job: map 100% reduce 100%
12/10/16 14:33:52 INFO mapreduce.Job: Job job_1434262360688_0002 completed successfully
...
...
...
12/10/16 14:34:02 WARN mapreduce.LoadIncrementalHFiles: Skipping non-directory hdfs://localhost:9000/user/output/_SUCCESS
12/10/16 14:34:03 INFO hfile.CacheConfig: CacheConfig:disabled
12/10/16 14:34:03 INFO hfile.CacheConfig: CacheConfig:disabled
12/10/16 14:34:07 INFO mapreduce.LoadIncrementalHFiles: Trying to load hfile=hdfs://localhost:9000/user/output/date/c64cd2524fba48738bab26630d550b61 first=AQW00061705 last=USW00094910
12/10/16 14:34:07 INFO mapreduce.LoadIncrementalHFiles: Trying to load hfile=hdfs://localhost:9000/user/output/tempPerHour/43af29456913444795a820544691eb3d first=AQW00061705 last=USW00094910
Bulk Load Completed..
Job is successfully completed...
BulLoad过程的第三步也可以在用MapReduce作业生成HBase数据文件后在命令行中进行,不一定要与MapReduce过程写在一起。
$ hadoop jar hbase-server-VERSION.jar completebulkload [-c /path/to/hbase/config/hbase-site.xml] outputpath tablename1
若在提交作业是产生如下异常:
12/10/16 11:41:06 INFO mapreduce.Job: Job job_1434420992867_0003 failed with state FAILED due to: Application application_1434420992867_0003 failed 2 times due to AM Container for appattempt_1434420992867_0003_000002 exited with exitCode: -1000
For more detailed output, check application tracking page:http://cdh1:8088/proxy/application_1434420992867_0003/Then, click on links to logs of each attempt.
Diagnostics: Rename cannot overwrite non empty destination directory /data/yarn/nm/usercache/hdfs/filecache/16
java.io.IOException: Rename cannot overwrite non empty destination directory /data/yarn/nm/usercache/hdfs/filecache/16
at org.apache.hadoop.fs.AbstractFileSystem.renameInternal(AbstractFileSystem.java:716)
at org.apache.hadoop.fs.FilterFs.renameInternal(FilterFs.java:228)
at org.apache.hadoop.fs.AbstractFileSystem.rename(AbstractFileSystem.java:659)
at org.apache.hadoop.fs.FileContext.rename(FileContext.java:909)
at org.apache.hadoop.yarn.util.FSDownload.call(FSDownload.java:364)
at org.apache.hadoop.yarn.util.FSDownload.call(FSDownload.java:60)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Failing this attempt. Failing the application.
12/10/16 11:41:06 INFO mapreduce.Job: Counters: 0
标签:
原文地址:http://www.cnblogs.com/muzili-ykt/p/5962633.html