标签:
主成份分析是最经典的基于线性分类的分类系统。这个分类系统的最大特点就是利用线性拟合的思路把分布在多个维度的高维数据投射到几个轴上。如果每个样本只有两个数据变量,这种拟合就是
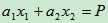 其中
其中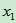 和
和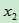 分别是样本的两个变量,而
分别是样本的两个变量,而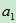 和
和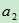 则被称为loading,计算出的P值就被称为主成份。实际上,当一个样本只有两个变量的时候,主成份分析本质上就是做一个线性回归。公式
则被称为loading,计算出的P值就被称为主成份。实际上,当一个样本只有两个变量的时候,主成份分析本质上就是做一个线性回归。公式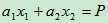 本质上就是一条直线。
本质上就是一条直线。
插入一幅图(主成份坐标旋转图,来自:PLS工具箱参考手册)
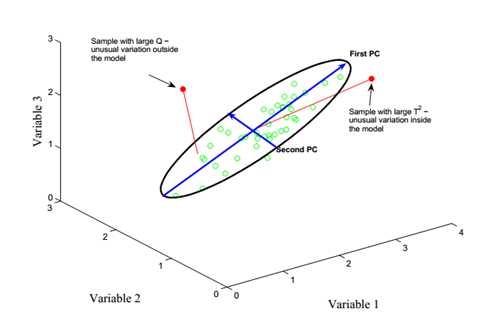
如果一个样本有n个变量,那主成份就变为:

其中PC1 称为第一主成份,而且,我们还可以获得一系列与PC这个直线正交的其它轴,如:
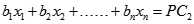
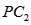 被称为第二主成份
被称为第二主成份
以此类推,若令 ,
,
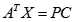
此时向量A称为主成份的载荷(loading),计算出的主成份的值PC称为得分(score)。
作为一个典型的降维方法,主成份分析在数据降维方面非常有用,而且也是所有线性降维方法的基础。很多时候,如果我们拿着一个非常复杂的数据不知所措的话,可以先考虑用主成份分析的方法对其进行分解,找出数据当中的种种趋势。在这里,我们利用数据挖掘研究当中非常常见的一个数据集对主成份分析的使用举例如下:
1996年,美国时代周刊(Times)发表了一篇关于酒类消费,心脏病发病率和平均预期寿命之间关系的科普文章,当中提到了10个国家的烈酒,葡萄酒和啤酒的人均消费量(升/年)与人均预期寿命(年)一级心脏病发病率(百万人/年)的数据,这些数据单位不一,而且数据与数据之间仅有间接关系。因此直接相关分析不能获得重要且有趣的结果。另外一方面,总共只有10个国家作为样本,各种常见的抽样和假设检验在这方面也没有用武之地,我们看看用何种方法能够从这个简单的数据表中获得重要知识
作为数据挖掘的第一步,首先应该观察数据的总体分布情况。无论是EXCEL软件,还是R语言,我们都能够很方便的从下表中获得表征数据分布的条形图。
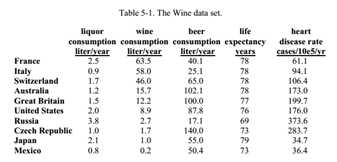
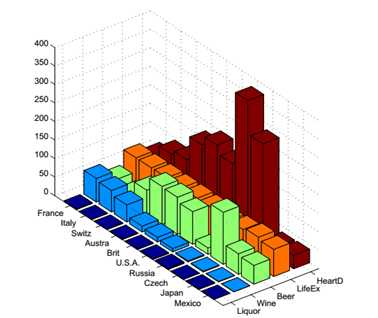
从图中可以看出,总共10个国家,有5类数据,由于各类数据性质各不相同,因此数值上大小也很不相同。各类数据看起来分布也没有明显规律。如果仔细观察,顶多能够获得俄国人心脏病发病率较高,捷克人啤酒消费量较高,法国人葡萄酒消费量较高这样的一般性结论。而且由于数据性质不同,但有一些已知的重要变量,如烈性酒消费量,在图中显示得并不明显。显然,如果不进行深入的分析,只是将这些数据"画"出来,直观固然是直观了(这种情况下,我们只能说数据的可视化做得很好),然而并不能帮助我们理解到数据之间的关系,并形成新的知识。
那么,我们就自己动手来对这组数据进行分析,看看会得到什么样的
有很多软件可以对数据进行主成份分析,从SAS,SPSS等经典统计学软件,到R语言,MATLAB等数学分析软件。因此,完成主成份分析并不困难,重要的是需要正确理解主成份分析的结果并且了解它对数据挖掘以及模式识别的影响。我们现在从数据本身的角度来分析主成份分析法能够获得的各种信息。
首先,在完成主成份分析之前,一般需要把数据进行中心化,所谓中心化,是指将所有分布的数据取消因为量纲不同,互相变异
如果完成主成份分析,我们可以得到如图所示的表格:
Eigenvalueof Cov(X) | % VarianceThis PC | % VarianceCumulative | RMSEC | RMSECV |
2.3014 | 46.0276 | 46.0276 | 0.69696 | 1.4511 |
1.6057 | 32.1148 | 78.1424 | 0.44353 | 1.7551 |
0.58424 | 11.6847 | 89.8271 | 0.30258 | 3.6918 |
0.42221 | 8.4443 | 98.2713 | 0.12473 | 21.6468 |
0.086433 | 1.7287 | 100 | 2.861e-15 | 21.6468 |
在这个表格中,很重要的的variance this PC这个变量,这个变量代表的就是我们生成的这根主成份轴能够代表整个数据分布多少的变化。而在上表中,第一主成份占据了46.02%的变异,第二主成份占据了32.11%的变异。这说明这些数据的分布是有规律的,在某一个方向上的投影比另外一些方向大。其中有46.02%的变异是落在第一个方向上。要理解variance this PC,我们可以看下图:
如下图所示:一个二维样本,那么主成份计算公式为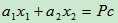 ,它所能够代表的数据就需要通过整理获得一个数据结果:如果x1和x2的分布如图所示,那么获得的第一个主成份会占据97%以上的变异。而与之正交的第二主成份,则只可能获得少于3%的变异,反之如图2,则第一主成份可以代表70.3%的变异,而第二主成份(与第一主成份正交)则代表29.6%的变异。
,它所能够代表的数据就需要通过整理获得一个数据结果:如果x1和x2的分布如图所示,那么获得的第一个主成份会占据97%以上的变异。而与之正交的第二主成份,则只可能获得少于3%的变异,反之如图2,则第一主成份可以代表70.3%的变异,而第二主成份(与第一主成份正交)则代表29.6%的变异。
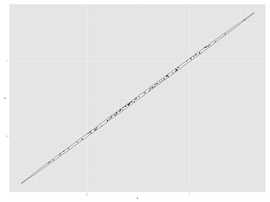
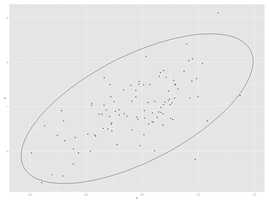
反之我们可以想象,如果上图的散点分布为类似随机打靶一样的球形,那么无论坐标轴如何旋转,两个主成份所占的变异依然是50%。此时进行主成份分析就没有太大的意义。因为两组随机分布的数据内无法找出重要的信息。
如上所述,由于主成份本质上是一种对于数据分布的拟合,这种拟合的结果刚好在某一方面可以对数据的分布特征(特别是变异程度)进行描述,我们自然就会很感兴趣主成份是如何计算出来的。在很多主成份分析里面可以导出载荷(loading)进行计算:计算结果一般可以用下表表示:
| PC 1 (46.03%) | PC 2 (32.11%) | PC 3 (11.68%) | Q Residuals (10.17%) | HotellingT^2(89.83%) |
烈酒 | -3.458964338207E-01 | -5.680919448155E-01 | 0.214391080836 | 1.616237328762 | 1.953345344946 |
红酒 | 4.450394524233E-01 | -3.783631226272E-01 | 0.617713498575 | 0.822477146498 | 2.891154932399 |
啤酒 | -7.396122081167E-02 | 7.244048393302E-01 | 0.424780191034 | 0.354252438668 | 2.842683376497 |
寿命预期 | 5.849799128031E-01 | 8.642298147150E-02 | 0.269427614166 | 1.422547209831 | 1.689046677538 |
心脏病 | -5.784667512397E-01 | 4.337726017205E-02 | 0.565187622091 | 0.362301486416 | 2.623769668620 |
从图中可以看出载荷的数量等于考察样本的参数数量,它意味着:
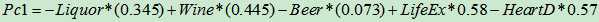
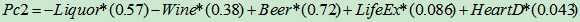

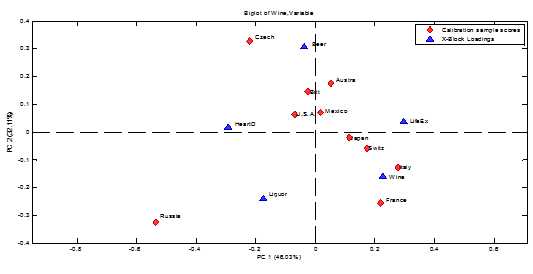
这三个主成份占据了所有数据变化的90%以上的变异。
其中第一个主成份的值同葡萄酒消费量成正相关,而同啤酒和酒精消费量呈负相关,与预期寿命呈正相关,与心脏病发病呈现负相关。它意味着至少从这个数据表上来看,某个国家的葡萄酒饮酒越高,那么这个国家的预期寿命越长,心脏病发病率越低。我们不妨将其命名为健康饮酒指数。
第二主成份与酒精和葡萄酒消费量呈负相关,与啤酒消费量呈正相关。同时与预期寿命和心脏病发病率都呈现微弱的正相关。这个主成份反应的主要是某种与啤酒消费的生活习惯。说明啤酒消费可以抑制红酒和葡萄酒消费。且啤酒消费对于健康在正面和负面的影响都不大。我们不妨将其命名为啤酒指数。
第三主成份和所有变量都呈现正相关,代表了矩阵10%所有的变异程度。实际上很可能代表的是居民的一般饮酒状况和热量摄入情况。可以设想,居民经济状况好,热量摄入高,就更容易获得各种酒精饮料,人均寿命也会较高,当然作为富贵病的心脏疾病发病率也会较高。我们不妨将这个成分命名为一般经济指数。
理论上还可以提取出第四、第五成份,但是这些主成份和整个系统的变异程度关系不大,也很难说明问题。
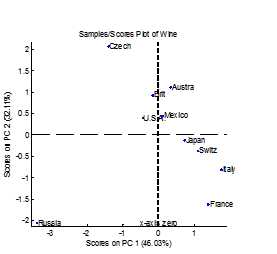
既然获得任何一个国家的Liquor /Wine /Beer /LifeEx /HeartD参数就可以使用上述系数做出主成份,那么我们不妨将上述每个国家的第一主成份,第二主成份计算出来,将第一主成份的值作为横坐标,第二主成份的值作为纵坐标。这样,10个样本(国家)就变成了分布在平面上的10个点。这样的根据主成份的值画出来的图被称为得分图(Score plot)。得分图可以反映出样本国家的区分情况。
从得分图上可以看出,在健康饮酒指数和啤酒指数这两个方面,各个国家还是有区别的。总体上说俄国是一个另类,在健康饮酒指数和啤酒指数上和其它国家都不太一样。
除开俄国,捷克到法国等9个国家在得分图上排列成一道从第二象限到第四象限的线状结构,捷克代表高啤酒指数低健康指数,反之法国意大利则代表低啤酒指数,高健康指数。最后,美国,墨西哥,日本等国处于原点附近,说明这几个国家的两项指标(健康指数和啤酒指数)绝对值不大,处于各项指标的均衡状态。
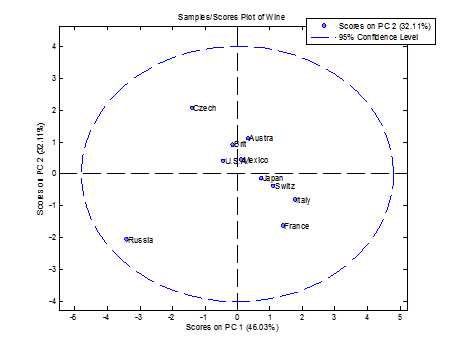
利用主成份分析的得分图可以获得样本之间的信息,我们知道每个样本都是由数个变量属性特征构成的,如果我们想知道这些属性特征之间的关系,则可以利用载荷图(loading)来对图像特征进行描述。
载荷图本质上描述的是构成第一主成份和第二主成份的线性方程的系数,如Wine的系数就是0.45和-0.38,从主成份的计算方法可以看出,载荷的绝对值越大,对于主成份的影响就越大。而这种影响则可以通过载荷所代表的点到原点之间的距离来进行衡量。如果某个点在进行主成份分析之后位置在原点附近,则说明这个该特征属性的波动对于样本之间的区别贡献不大。我们从上图中可以看出,载荷图上每个属性都分布在不同的方向,这就意味着这些属性相互之间并没有太大的相似性。但是根据这些属性的分布方向,我们也可以找出很多重要信息:
首先在第一主成份(横坐标)上,预期寿命和心脏病发病率刚好处于两级,这说明,对于健康饮酒指数来说,预期寿命和心脏病分别处于相反的两个方向。心脏病发病率越高,预期寿命也就越低,反之亦然。而在第一主成份上,烈酒(liquor)和葡萄酒(wine)也是处在两个相反方向。这在一定程度上说明,烈酒消费量很可能和健康负相关,而葡萄酒呈现正相关。啤酒则不太相关。当然,相关性并不等于因果性,对于这种分析,我们不能轻易的得出烈酒有可能造成预期寿命降低的结论。对于啤酒,烈性酒和葡萄酒三种酒类,它们的分布刚好在三个不同的方向上,且各自与原点的距离都非常相似,这说明这三种酒的消费量相互之间没有相关性。根据图上分析,我们可以得出如下结论:如果我们仅考虑这三种酒的话,三种酒的总消费量对于各个国家酒类消费总量的贡献是差不多的。总有一种酒类会占据消费的主导性地位,且与其他两种酒的消费无关。存在没有特别酒类偏好的国家(如美国,墨西哥),但不存在没有国家偏好的酒。如果某种酒没有特别的国家偏好,世界各国消费量都差不多,那么这种酒就会分布在原点附近。
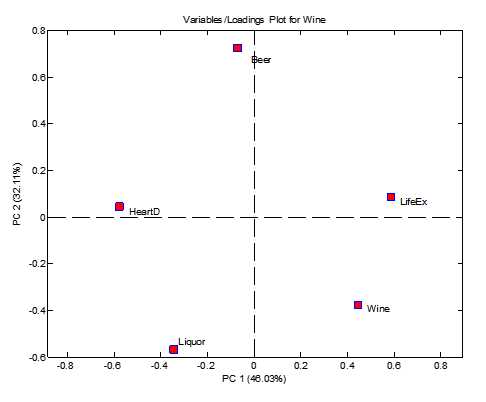
对于主成份分析的模式识别来说,当把载荷图和得分图结合起来的时候,我们有可能获得更多的信息。

对于国家来说,在主成份得分图上的分布方向代表了国家的特征,比如俄国的分布方向是左下,那么哪一类变量对于左下分布的贡献最大?很自然,我们可以发现心脏病发病率HeartD和烈性酒消费量Liquor这两个变量对于俄国的"离经叛道"最为重要。可以说,就是这两个方向上的变化把俄国推离了主要国家分布。实际上这个现象也和其它的研究以及我们的直观印象相符合,俄国人确实很喜欢喝烈性酒。利用类似的思路我们可以发现,如果一个国家的心脏病发病率较高,那么心脏病发病率就会推动该国向数轴左边移动。反之预期寿命越长,我们可以想象有一股力把国家推向右边。啤酒消费量则可以看成一股向上方的力量。在啤酒,葡萄酒,预期寿命三股力量的驱动下,捷克,奥地利,到法国意大利形成一个从左上到右下的趋势。这种趋势下寿命逐渐延长,葡萄酒消费量逐渐升高,啤酒消费量逐渐下降。当然,必须指出的是,上述趋势依然描绘的是针对数据本身的一种相关性而非因果性分布,不能轻易得出多喝葡萄酒有利于延长寿命的结论。
在上图中,我们还可以看到,美国,英国,奥地利以及墨西哥在得分图上较近。从饮酒习惯上说,英美生活习惯较为接近比较好理解,但是墨西哥实际上和英美在饮酒模式上还是有重要的差别的,此时我们有两个方法可以对墨西哥的情况进行考察,第一是加入第三主成份,将三个主成份的值放入到一个三维空间坐标中进行考察:
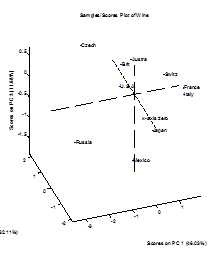
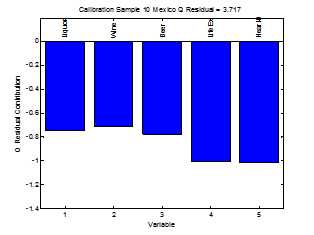
此时加入第三个主成份之后,我们可以发现墨西哥实际上在三维空间中与英美具有相当远的距离。这说明单看饮酒健康指数和啤酒指数,墨西哥人与美国相似,但是,如果开始计算国民的饮酒量以及与之相关的一般经济指数,墨西哥人就和英美具有较大的差异了。在进行主成份分析的过程中,还有一个指标可以显示样本距离第一主成份和第二主成份形成的平面的距离,这个指标被称为Q残差。
 对Q残差作图可以得到:
对Q残差作图可以得到:
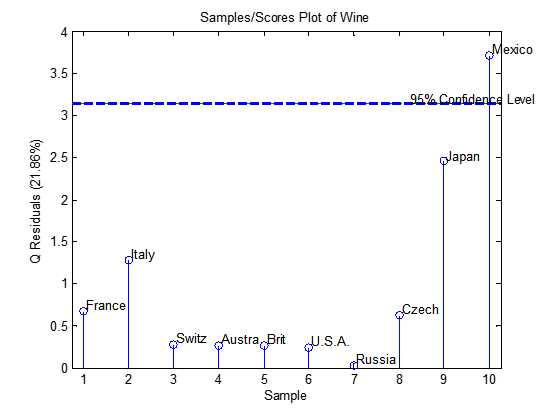
从图中可以看到,如果把第一、二主成份看成一个平面Q残差本质上就代表各个国家在一、二主成份形成平面的距离。墨西哥离开这个平面的距离相当远。这说明在所有考察国家当中,墨西哥由于其一般经济情况和其它国家不太一样,以至于第三主成份到了不得不被考察的地步了。那么让墨西哥偏离一、二主成份平面的最主要的原因是什么呢?一方面我们可以直接去看第三主成份的系数,第三主成份是所有的值都是正值。而墨西哥在第三主成份的轴上向负方向远离原点非常明显,我们可以直觉墨西哥的各种值都比较低,我们也可以直接通过矩阵变换的方式由计算机计算出墨西哥的Q残差,并发现对于墨西哥来说所有的Q残差都是负的,这就意味着墨西哥偏离主平面的原因是它所有的值都比其他国家要小。
从上述的分析我们可以看出,主成份分析是基于线性判别的复杂模式识别的基础。就最开始的数据表上来说,我们知道关于饮酒模式每个国家都是独一无二的。但是我们哪怕是通过直觉也能感受得到,从酒类的消费来说.俄国人、墨西哥人和英国人美国人确实有些不一样。熟知这些国家饮酒信息的人可以通过模糊的语言从很多方面描绘出来从而形成一种模式判别。而根据数据和基于恰当的数学分析重新理解这种模式判别则需要强有力的数学工具,主成份分析就是这样一种数学工具。如果有一个国家在饮酒数据分布上和俄国很相似,将这个国家的数据带入上述分析所获得的线性方程组,计算获得的第一、二、三主成份也会比较相似。因此我们就可以用客观的计算代替普通人对于复杂模式进行主观判断。
了解主成份分析的基本原理之后,研究者自然可以想到,可以通过提取的主成份来和一些重要的临床结局进行回归。此时这种回归的信息就有可能对复杂临床问题的处理带来新的知识。例如,在上面的例子中,传统的思路是利用还原的方法分别考察某种酒的饮酒量和我们感兴趣的某种临床结局之间的的相关性。但是,如果我们能够通过计算获得复杂指标与临床决策之间的关系。例如,在判断急诊病人应该接受哪一种治疗方案方面,我们就可以做出如下应用:
2008年的512地震给中国西部的急诊医疗途径带来了巨大的挑战。在短短的数天时间内,大量的急诊患者涌入成都市的各家医院急诊科。医生在尽力救治病人的同时也积累了海量的数据。当我们拿到这些宝贵的数据的时候,我们就希望通过对这些数据的学习和挖掘得到更多的新的知识,这些新的知识有可能意味着在未来遇到上述紧急情况的时候带来更多更好的救治措施。
标签:
原文地址:http://www.cnblogs.com/SCUJIN/p/5965946.html