标签:
判断分类器的工作效率需要使用召回率和准确率两个变量。
召回率:Recall,又称"查全率",
准确率:Precision,又称"精度"、"正确率"。
以判断病人是否死亡的分类器为例,可以把分类情况用下表表示:
实际死亡 | 实际未死亡 | |
分类为死亡 | A | B |
分类为未死亡 | C | D |
表5-2
A:正确分类,命中死亡
B:错误分类,判断为死亡实际未死亡
C:错误分类,判断为未亡实际死亡
D:正确分类,判断未死亡,实际也未死亡
如果我们希望这个分类器对于死亡的判断能力非常高,也就是追求判断为死亡的命中率越高越好。更一般的说法,对于特定临床结局的判断能力越强越好,评价这个分类器能力的指标被称为召回率,也被称为"查全率",即Recall = A/(A+C),召回率当然越大越好。
如果我们希望分类器对于死亡的预测能力更高,也就是分类为死亡的人死亡的概率最大。或者更一般的说法,对于特定临床结局的预测能力越强越好,这是追求"准确率",即Precise = A/(A+B),越大越好。
在上面那个表格当中,由于样本总数一定,因此A+B和C+D的总数也是一定的,我们把改变分类规则,让A+B逐渐增大叫做判断标准放宽。将C+D数量增大叫做判断标准收严。
很容易可以看出,召回率反映的是在实际死亡的样本当中,分类为死亡的人所占的比例。如果我们把分类标准放宽,A+B变得很大,c会减小,甚至c=0直到"宁可错杀一千,也不放过一个",有点危险的人统统算成死亡的人,则很可能获得较高的召回率。但是此时,准确率会逐渐降低。
准确率则是在判断为死亡的样本中,真实死亡的人所占的比例,如果我们把分类标准定得很严,仅把哪些生命体征极为微弱,伤情特别严重的人纳入判断为可能死亡的组,在这种情况下,准确率会变得很高,分类器判断为死亡的人大多活不了,但是此时分类器的召回率就会小得不可接受。因此,要对分类器的工作效能进行判断,需要同时考察准确率和召回率。两者均高,则分类器更好。
在不改变分类器基本性能的情况下,仅仅改变纳入参数的标准,就可以在同一数据集里面多次检查统计率和召回率,最后获得准确率(P)和召回率(R)之间的曲线。这条曲线上的每一个点和坐标(1,1)之间的距离可以用来判断出分类器的性能,如果这条曲线当中某一个点通过了坐标(1,1)也就是准确率和召回率都达到100%,那么此时分类标准就被称为"完美分类标准"
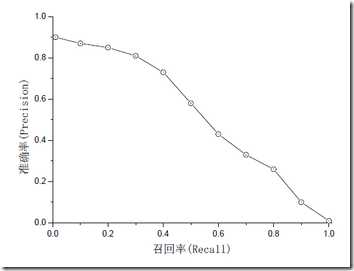
一般来说,如果分类器的目的是进行死亡筛查,找出那些有可能死亡的患者重点关注,那么此时应当重视召回率(查全率),这样可以避免忽视那些有可能死亡的患者。而如果分类器的目的是为了做疾病诊断,那么则应该注意准确率,把太多的没有病死风险的患者判断为有风险则有可能影响用户对分类器的信心。
如果同时对召回率和准确率都有所要求,可以用经验测度值F来表示系统的工作效能。
F=2*P*R/(P+R)
F值越接近1,则系统的工作效能越高。
回到ROC上来,ROC的全名叫做接收器工作特性曲线(Receiver Operating Characteristic)。
它由两个指标构成:
(一)真阳性率True Positive Rate ( TPR ) = A / A+C ,TPR代表能将正例分对的概率,也就是上面提到的查全率。
(二)假阳性率False Positive Rate( FPR ) = B /(B+D) ,FPR代表将负例错分为正例的概率。
在ROC 空间中,每个点的横坐标是假阳性率,纵坐标是真阳性率,这也就描绘了分类器在真阳性率和假阳性率之间的一个连续的权衡过程。ROC的主要分析工具是一个画在ROC空间的曲线——ROC curve。根据分类结果计算得到ROC空间中相应的点,连接这些点就形成ROC curve。ROC 曲线起点是(0,0),意味着某种异常严格的标准,使得没有任何样本被判断为阳性。终点是(1,1)意味着某种异常宽松的标准,使得任何样本不管真假,都被判断为阳性。实际上(0, 0)和(1, 1)连线形成的ROC curve就是一个随机分类器。一般情况下,这个曲线都应该处于(0, 0)和(1, 1)连线的上方。
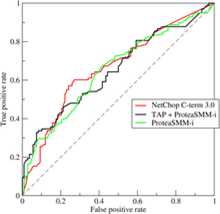
用ROC curve来表示分类器性能很直观好用。可是,人们总是希望能有一个数值来标志分类器的好坏。
于是Area Under roc Curve(AUC)就出现了。顾名思义,AUC的值就是处于ROC curve下方的那部分面积的大小。通常,AUC的值介于0.5到1.0之间,较大的AUC代表了较好的性能。如果AUC的值仅仅只有0.5,那么则意味着这个分类器的性能和随机抛硬币类似。
建立好上述预测分类器之后,需要评估它的预测工作效率,也就是对于给定的入院患者数据,我们建立起来的分类器在多大程度上能够正确预测临床结局。
对于分类器或者预测器进行功能评估由一个很重要的一个因素是要防止"过度分类"。没有任何两个病人的入院数据是完全相同的。如果在已知临床结局的情况下去建立起一个区别病人生存和死亡的模型,如果纳入足够多的入院数据,很可能建立起一套非常"完美"的分类器,把已有的数据代入这个分类器可以准确的判断是临床结局。但是如果一旦有新数据进入这套分类器,那么判断结果往往就有可能出错。造成这种现象的原因是因为分类器构建出来的目的不是对已经发生的事情进行分类,而是对未发生的事情进行预测。纳入过多的变量,通过"事后诸葛亮"似的过程来对样本进行分类很有可能把一些在统计学上和样本结局相关,但实际上只是巧合的变量计算入数据建模当中,从而使得分类器的判断准确率变得很高。
有两类方法可以防止过度分类,一类是将数据训练集和测试集彻底分开,用新获得的数据来进行区分模型的准确性检验。而另外一种方法则是在构建训练集的时候进行交叉验证。所谓交叉验证就是,用所有数据的一部分用作训练集。另外一小部分作为验证集。计算出分类器准确度。然后把原来作为验证集的数据纳入训练集,从训练集当中新画出一部分样本作为验证集。最后直到所有的样本都有机会纳入训练集和验证集当中。这样的一个过程就称为交叉验证(cross validation),交叉验证可以在样本有限的情况下获得尽可能稳定的分类结果。
利用统计分类器。所谓分类,本质上就是利用统计学方法将按照预后分为可能死亡的和尚安全的两类,或者将患者划分为可能产生不良结局(如多器官功能不全,MODS)和不会产生MODS的两类。如果我们在统计学上建立起一套判别规则,使之能够把入院数据和临床结局在统计学上联系起来。那么上述分析过程则有可能为判定病人死亡或者发生MODS的风险奠定基础。必须指出,把入院数据和临床结局在统计学上联系起来说明的是两者之间的关系是相关关系,而不是因果关系。但是如果考虑到时间发生的先后关系。这种相关关系对于进一步探究临床结局产生的原因依然是重要的。
如果要建立单独的某一些变量与临床结局有很多种方法,来构建多元的统计学分类器。。一种方法是利用模式识别的思路对病人进行划分。模式识别的核心思想是将患者的病情(就创伤而言,包括受伤时情况、特定时点的生理生化指标)视为不同的、可区分的模式,随着治疗干预措施的实施,伤情模式随之发展变化,最终导致患者出现生或者死的最终结局。在这个意义上,由各种指标共同组成的伤情模式较之单一指标更能提供多维度、立体的预后预测信息。
另外一种对于疾病患者入院之后的结局进行提前预判的方法就是回归。回归的本质是假设入院数据与临床结局之间存在潜在的关系,这种关系能够通过线性或者非线性的函数表示出来。找出这些关系与临床结局之间的关系具有两重重要意义:a)可以找出哪些入院数据与临床结局之间的关系更为密切,从而为进一步研究打下基础;b)可以通过入院数据对临床结局进行预测,在概率意义上给出特定临床结局发生的可能性。不管是模式识别,还是回归分析,他们的输入的参数都是一系列表征输入样本特征的数据。这样的一串数据往往被称为向量。而输出的如果是分类信息则被称为模式识别。如果输出的也是一个连续数据,则被称为回归。实际上,如果是分类信息,只要给分类信息的每一个种类加上一个概率参数,离散的分类信息也就可以转化为连续的属于某一类的概率信息。
常见的分类方法包括有监督分类和无监督分类。所谓有监督分类,是指在知道结果的情况下,对样本进行分类。有监督分类由于同时指导样本的各种参数信息和数字化的结局,本质上就是对样本和结局之间进行矩阵的相关性分析。
插图:有监督分类和无监督分类:
无监督分类
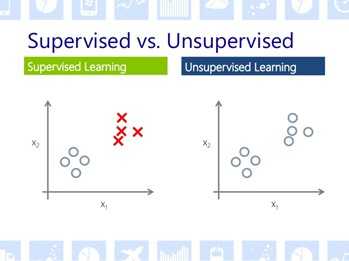
而对于无监督分类来说,由于不知道数据的结果,因此必须依据矩阵数据本身的分布特性进行区分。各种无监督分类分出来的都是样本与样本之间区别最明显的(但不一定是最重要的)特征。而有监督分类最需要注意的是防止"过度分类"的问题。
监督分类 (supervised classification)又称训练场地法,是以建立统计识别函数为理论基础,依据典型样本训练方法进行分类的技术。所谓典型样本就是已经知道了最终归属的样本。比如已经获得了200个轻伤病人和200个重伤病人的各种资料,想通过统计识别函数判断轻伤和重伤在入院病情上的区别。这种分类就叫做有监督分类。因为此时400人的判定结局是已知的。可以通过各种泛函尽量把样本的数据向结局进行映射,有时候还可以利用计算机的高速计算能力对于函数结果进行不断校正。而无监督分类则是意味着在结局还没有出来的情况下,利用计算机的计算能力自动找出各样本之间的区别和联系,看看通过纳入的各种变量在哪些成都上能够分出种类。无监督分类包括主成份分析,分级聚类,Kmean聚类以及,基于SOM元胞自组装机的分类系统。
标签:
原文地址:http://www.cnblogs.com/SCUJIN/p/5965942.html