标签:
在用机器学习的方法之前,我们应该先把数据转变为表格的形式,这个过程是最耗时、最复杂的。我们用下图来表示这一过程。
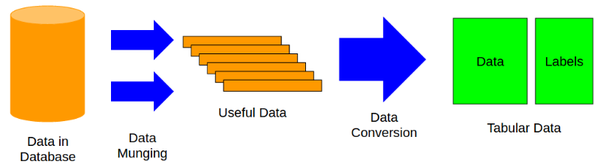
这一过程也就是将原始数据的所有的变量量化,进一步转变为含数据(Data)和标签(Labels)的数据框形式。这样处理过的数据就可以用来机器学习建模了。数据框形式的数据是机器学习和数据挖掘中最为通用的数据表现形式,它的行是数据抽样得到的样本,列代表数据的标签Y和特征X,其中标签根据我们要研究的问题不同,有可能是一列或多列。
根据我们要研究的问题,标签的类型也不一:
对于多个机器学习方法,我们必须找到一个评价指标来衡量它们的好坏。比如一个二元分类的问题我们一般选用AUC ROC或者仅仅用AUC曲线下面的面积来衡量。在多标签和多分类问题上,我们选择交叉熵或对数损失函数。在回归问题上我们选择常用的均方误差(MSE)。
在安装机器学习的几个库之前,应该安装两个基础库:numpy和scipy。
2015年我想出了一个自动式机器学习的框架,直到今天还在开发阶段但是不久就会发布,本文就是以这个框架作为基础的。下图展示了这个框架:
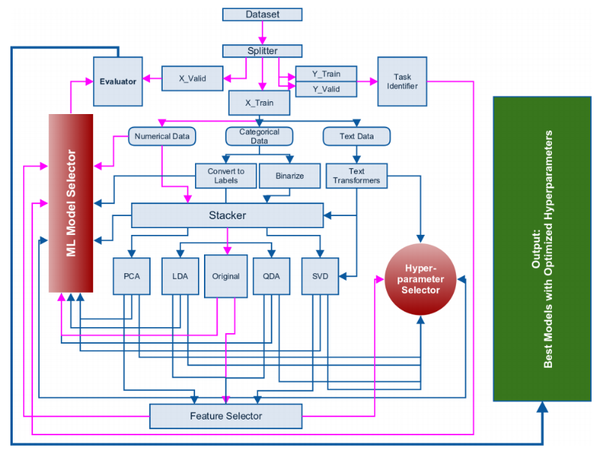
上面展示的这个框架里面,粉红色的线就是一些通用的步骤。在处理完数据并把数据转为数据框格式后,我们就可以进行机器学习过程了。
确定要研究的问题,也就是通过观察标签的类别确定究竟是分类还是回归问题。
第二步是将所有的样本划分为训练集(training data)和验证集(validation data)。过程如下:
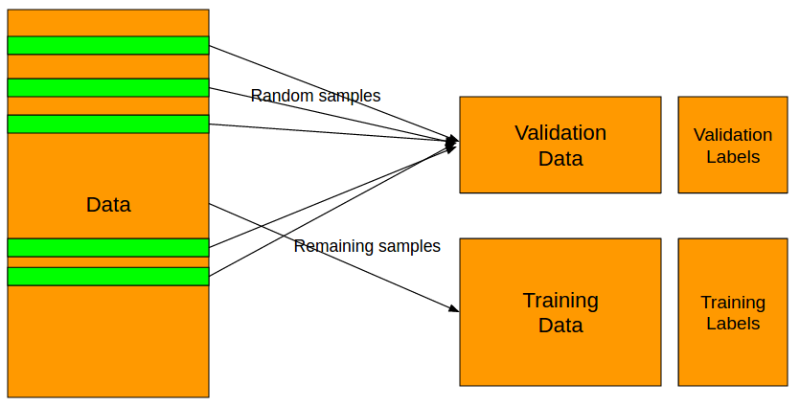 划分样本的这一过程必须要根据标签来做。比如对于一个类别不平衡的分类问题,必须要用分层抽样的方法,比如每种标签抽多少,这样才能保证抽出来的两个样本子集分布类似。在Python中,我们可以用scikit-learn轻松实现。
划分样本的这一过程必须要根据标签来做。比如对于一个类别不平衡的分类问题,必须要用分层抽样的方法,比如每种标签抽多少,这样才能保证抽出来的两个样本子集分布类似。在Python中,我们可以用scikit-learn轻松实现。
 对于回归问题,那么一个简单的K折划分就足够了。但是仍然有一些复杂的方法可以使得验证集和训练集标签的分布接近,这个问题留给读者作为练习。
对于回归问题,那么一个简单的K折划分就足够了。但是仍然有一些复杂的方法可以使得验证集和训练集标签的分布接近,这个问题留给读者作为练习。
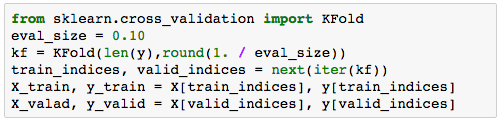
上面我用了样本全集中的10%作为验证集的规模,当然你可以根据你的样本量做相应的调整。
划分完样本以后,我们就把这些数据放在一边。接下来我们使用的任何一种机器学习的方法都要先在训练集上使用然后再用验证集检验效果。验证集和训练集永远都不能掺和在一起。这样才能得到有效的评价得分,否则将会导致过拟合的问题。
一个数据集总是带有很多的变量(variables),或者称之为特征(features),他们对应着数据框的维度。一般特征的值有三种类型:数值变量、属性变量和文字变量。我们用经典的泰坦尼克号数据集来示例。
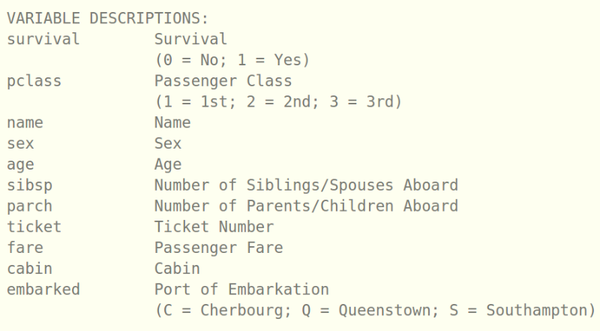
在这里生还(survival)就是标签,船舱等级(pclass)、性别(sex)和登船港口(embarked)是属性变量。而像年龄(age)、船上兄弟姐妹数量(sibsp)、船上父母孩子数量(parch)是数值变量。而姓名(name)这种文字变量我们认为这和生还与否没什么关系,所以我们决定不考虑。
首先处理数值型变量,这些变量几乎不需要任何的处理,常见的方式是正规化(normalization)。
处理属性变量通常有两步:
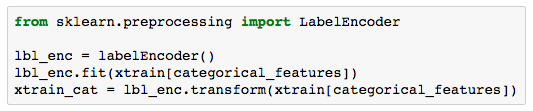
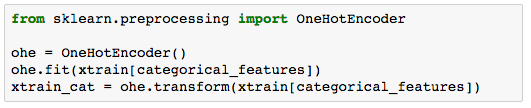 由于泰坦尼克号数据集没有很好的文字变量来示范,那么我们就制定一个通用的规则来处理文字变量。把所有的文字变量组合到一起,然后用某种算法来处理并转变为数字
由于泰坦尼克号数据集没有很好的文字变量来示范,那么我们就制定一个通用的规则来处理文字变量。把所有的文字变量组合到一起,然后用某种算法来处理并转变为数字
我们可以用CountVectorizer或者TfidfVectorizer来实现
 一般来说第二种方法往往比较优越,下面代码框中所展示的参数长期以来都取得了良好的效果。
一般来说第二种方法往往比较优越,下面代码框中所展示的参数长期以来都取得了良好的效果。 如果你对训练集数据采用了上述处理方式,那么也要保证对验证及数据做相同处理。
如果你对训练集数据采用了上述处理方式,那么也要保证对验证及数据做相同处理。

特征融合是指将不同的特征融合,要区别对待密集型变量和稀疏型变量。
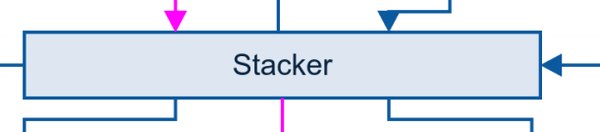

当我们把特征融合好以后,可以开始机器学习的建模过程了,在这里我们都是选择以决策树为基学习器的集成算法,主要有:
如果以上方式处理后的数据可以产生一个优秀的模型,那就可以直接进行参数调整了。如果不行则还要继续进行特征降维和特征选择。降维的方法有以下几种:
 简单起见,这里不考虑LDA和QDA。对于高维数据来说,PCA是常用的降维方式,对于图像数据一般我们选用10~15组主成分,当然如果模型效果会提升的话也可以选择更多的主成分。对于其他类型的数据我们一般选择50~60个主成分。
简单起见,这里不考虑LDA和QDA。对于高维数据来说,PCA是常用的降维方式,对于图像数据一般我们选用10~15组主成分,当然如果模型效果会提升的话也可以选择更多的主成分。对于其他类型的数据我们一般选择50~60个主成分。
 文字变量转变为稀疏矩阵后进行奇异值分解,奇异值分解对应scikit learn库中的TruncatedSVD语句。
文字变量转变为稀疏矩阵后进行奇异值分解,奇异值分解对应scikit learn库中的TruncatedSVD语句。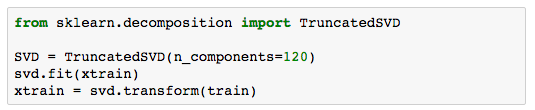 一般在TF-IDF中SVD主成分的数目大约在120~200之间,但是也可以采用更多的成分,但是相应的计算成本也会增加。
一般在TF-IDF中SVD主成分的数目大约在120~200之间,但是也可以采用更多的成分,但是相应的计算成本也会增加。
在特征降维之后我们可以进行建模的训练过程了,但是有的时候如果这样降维后的结果仍不理想,可以进行特征选择: 特征选择也有很多实用的方法,比如说常用的向前或向后搜索。那就是一个接一个地把特征加入模型训练,如果加入一个新的特征后模型效果不好,那就不加入这一特征。直到选出最好的特征子集。对于这种方法有一个提升的方式是用AUC作为评价指标,当然这个提升也不是尽善尽美的,还是需要实际应用进行改善和调整的。
特征选择也有很多实用的方法,比如说常用的向前或向后搜索。那就是一个接一个地把特征加入模型训练,如果加入一个新的特征后模型效果不好,那就不加入这一特征。直到选出最好的特征子集。对于这种方法有一个提升的方式是用AUC作为评价指标,当然这个提升也不是尽善尽美的,还是需要实际应用进行改善和调整的。
还有一种特征选择的方式是在建模的过程中就得到了最佳特征子集。比如我们可以观察logit模型的系数或者拟合一个随机森林模型从而直接把这些甄选后的特征用在其它模型中。
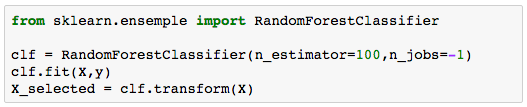 在上面的处理中应该选择一个小的estimator数目这样不会导致过拟合。还可以用梯度提升算法来进行特征选择,在这里我们建议用xgboost的库而不是sklearn库里面的梯度提升算法,因为前者速度快且有着更好的延展性。
在上面的处理中应该选择一个小的estimator数目这样不会导致过拟合。还可以用梯度提升算法来进行特征选择,在这里我们建议用xgboost的库而不是sklearn库里面的梯度提升算法,因为前者速度快且有着更好的延展性。
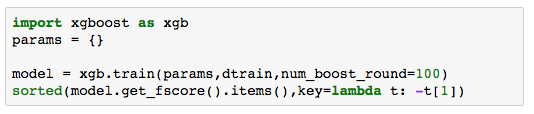 对于稀疏的数据集我们可以用随机森林、xgboost或卡方等方式来进行特征选择。下面的例子中我们用了卡方的方法选择了20个特征出来。当然这个参数值20也是可以进一步优化的。
对于稀疏的数据集我们可以用随机森林、xgboost或卡方等方式来进行特征选择。下面的例子中我们用了卡方的方法选择了20个特征出来。当然这个参数值20也是可以进一步优化的。

同样,以上我们用的所有方法都要记录储存用以交叉验证。
一般而言,常用的机器学习模型有以下几种,我们将在这些模型中选择最好的模型:
下表中展示了每种模型分别需要优化的参数,这其中包含的问题太多太多了。究竟参数取什么值才最优,很多人往往有经验但是不会甘愿把这些秘密分享给别人。但是在这里我会把我的经验跟大家分享。
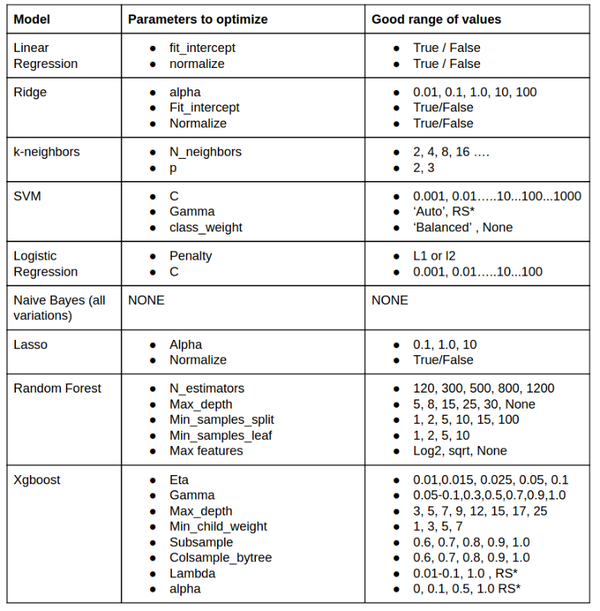
RS*是指没有一个确切的值提供给大家。
在我看来上面的这些模型基本会完爆其他的模型,当然这只是我的一家之言。下面是上述过程的一个总结,主要是强调一下要保留训练的结果用来给验证集验证,而不是重新用验证集训练!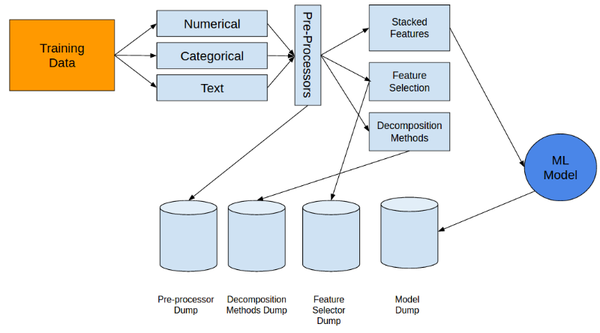

在我长时间的实践过程中,我发现这些总结出来的规则和框架还是很有用的,当然在一些极其复杂的工作中这些方法还是力有不逮。生活从来不会完美,我们只能尽自身所能去优化,机器学习也是一样。
 原文作者:Abhishek Thakur
原文作者:Abhishek Thakur
原文链接:Approaching (Almost) Any Machine Learning Problem
译者:Cup
标签:
原文地址:http://www.cnblogs.com/harvey888/p/5966637.html