标签:
Caffe简要介绍:
Caffe还没有windows版本,所以我需要远程登录linux服务器
Caffe主要处理图片/图片序列
Caffe读取的数据格式
|
从专用的数据库中读取(lmdb、leveldb) |
|
直接读取图片 |
|
从内存中读取(会占很多内存) |
|
从HDF5文件中读取 |
|
从滑动窗口中读取(在大图中滑动一次作为一张小图) |
最常用的是前面两种方式。默认是从lmdb数据库格式中读取,因此需要先把图片文件转换成lmdb格式文件。直接读取图片会导致无法减均值。如果不考虑减均值的情况,可直接读取图片。
Caffe操作1----准备数据
Step1:得到文件列表清单
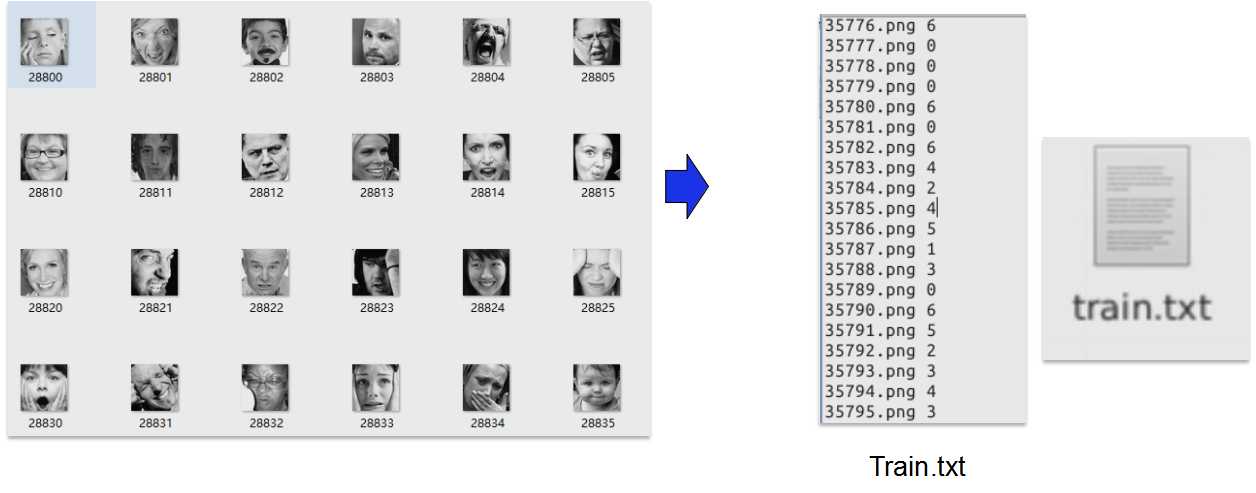
上面的图片源自FER库,其中单张图表示一个表情,写代码自动生成txt文档
Step2:转换成imdb格式
命令原理:

其中包括上面四个参数,粉色参数可以选择不设,其中--表示可以不调整
实际操作:
在根目录home下的/caffe路径下打开终端,输入sudo命令,输入密码,进入最大权限:
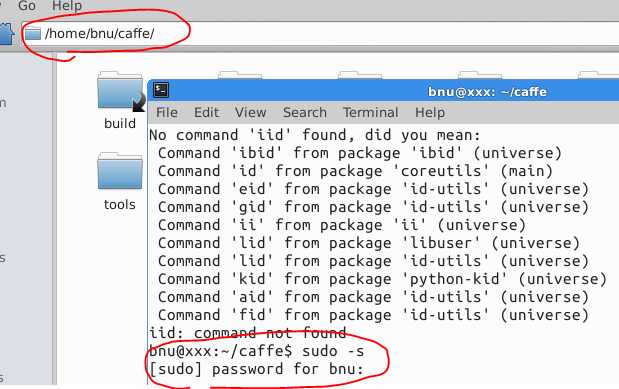
输入命令:(输入时注意空格)

在caffe中,作者为我们提供了这样一个文件:convert_imageset.cpp,存放在根目录下的tools文件夹下。编译之后,生成对应的可执行文件放在 buile/tools/ 下面,这个文件的作用就是用于将图片文件转换成caffe框架中能直接使用的imdb文件。
屏幕上显示:

查看结果:
在目标目录下新增了我命名的一个文件夹
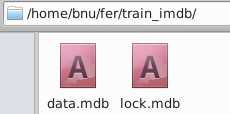
文件夹里包括两个子文件,data.mdb存放数据;lock.mdb存放标签
基础知识补充
Linux下的文件夹与目录
|
/home |
根目录,分区时分得最大 |
|
/bin |
存放系统命令 |
|
/user |
最大的目录,存放应用程序和文件 |
|
/etc |
存放配置文件 |
|
/dev |
设备特殊文件 |
|
/mnt |
用于临时挂载硬盘、光盘 |
|
/src |
里面放源文件如cpp |
如何生成train.txt文件以及如何在转imdb格式时调整图片格式,见:http://www.cnblogs.com/denny402/p/5082341.html
Step3:计算均值
减去均值,可以提高精度。当然也可以选择不减均值。
扩展名必须是binaryproto
实际代码:

其中包括两个参数,一个是放置imdb数据的文件地址,另一个是保存均值文件的地址及文件名字
得到binarypro均值文件
扩展阅读:http://www.cnblogs.com/denny402/p/5102328.html
Caffe操作2----构建网络结构
在运行的整个流程中,可以分为三个阶段:训练阶段、验证阶段和测试阶段。网络结构在不同的阶段是不同的,都存放在prototxt文件里面。为了方便,一般将训练阶段和验证阶段的网络结构放在一个文件里,测试阶段的网络结构单独放在一个文件里:

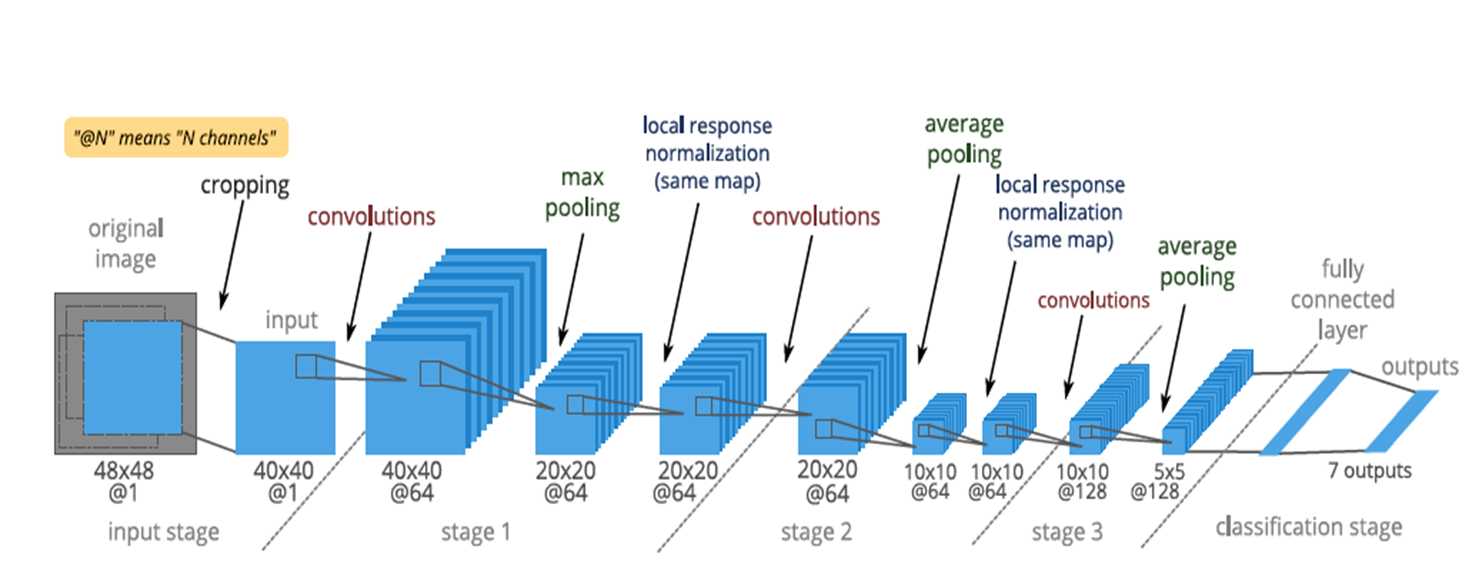
一个layer表示一层
layer是可以复制可以嵌套的
1)数据层

Name可以随便取
Type是系统自带的,不可以自己命名
Top表示向上传送数据,bottom表示从下面接收数据,通过这个top还是bottom就决定了数据的流向以及不同层之间的链接关系
Phase:train表示只有训练时调用这层
Mirror表示翻转
Cropsize表示一张图变为40*40*10,使得样本数增加
Batchsize是2的倍数,表示批量处理
http://www.cnblogs.com/denny402/p/5070928.html
2)卷积层

Decay=0表示不衰减
Num_output 卷积核个数/节点数目
Kernal_size 一般是3*3 5*5 7*7 不能太大
Padding 卷积后图变小,所以固定填充0,如果=2,表示周边上下左右填充2个pixel
Gaussian表示用高斯方法对w与b进行初始化
http://www.cnblogs.com/denny402/p/5071126.html
3)激活层

常用relu,sigmod
http://www.cnblogs.com/denny402/p/5072507.html
4)池化层

caffe只支持max和average,stochastic是随机的意思
Stride不能写1,否则就没有池化功能
http://www.cnblogs.com/denny402/p/5071126.html
5)全连接层

Xvaier初始化方法很好,默认值为0
Type类型都不变
http://www.cnblogs.com/denny402/p/5072746.html
6)其它层

Loss层加在全连接层后面
如果要测试,还加一层softmax层
Deploy.prototxt文件用于测试阶段,测试数据没有标签值,因此数据输入层与其它两个阶段不同。

Caffe自动会复制灰度图变为3通道图
Caffe操作3----配置参数solver.prototxt
这里设置全局参数

每训练完成一个interval以后就验证一次是否>449
基础学习率决定收敛不收敛
Step:每隔多少变化一次
Stepshot:每训练多少保存一次参数

http://www.cnblogs.com/denny402/p/5074049.html
Caffe操作4----训练模型
这一步会生成caffe 的model文件,把参数训练完成
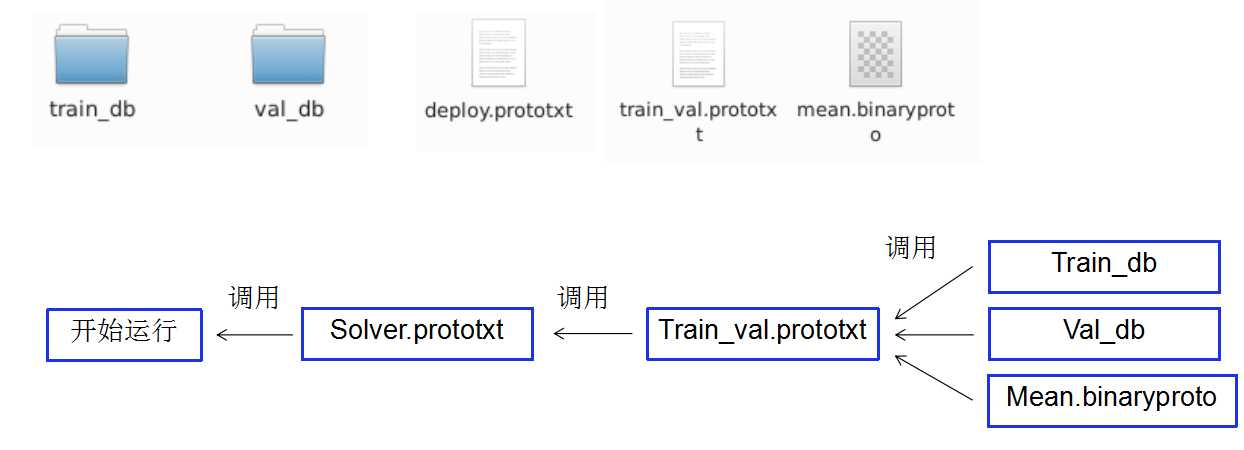
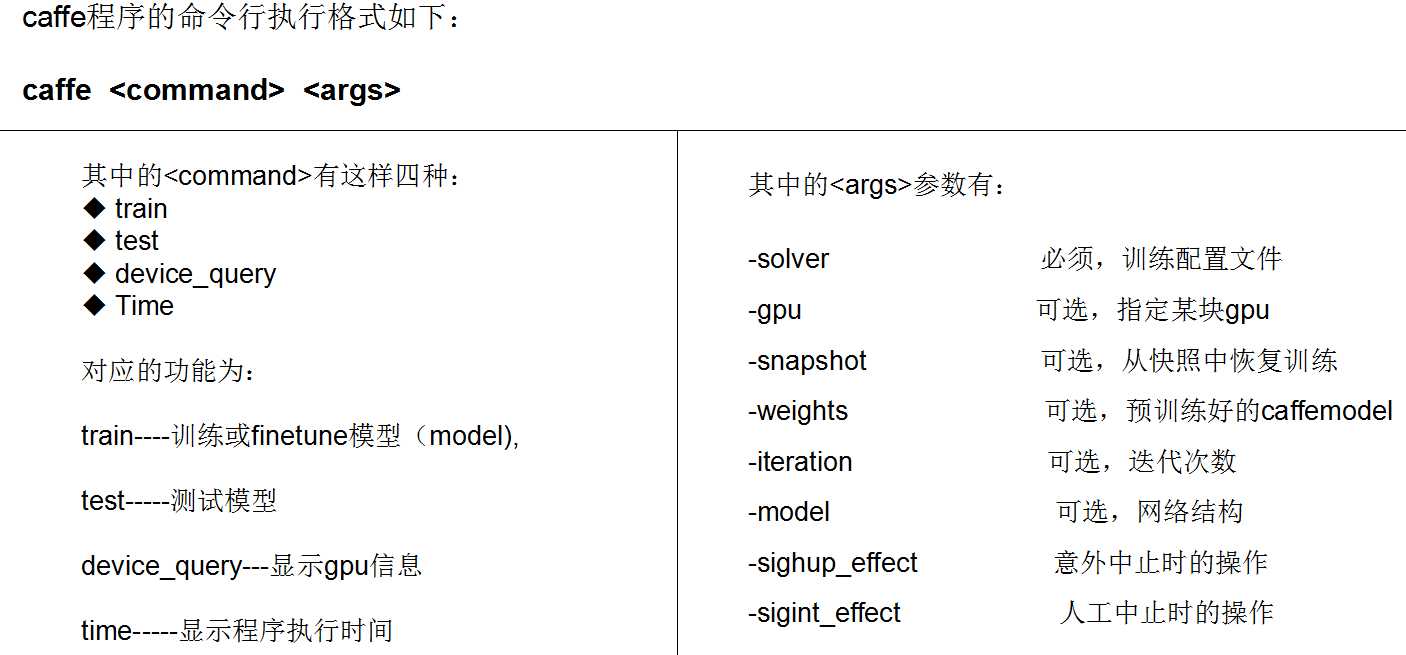
例:
build/tools/caffe train -solver /home/bnu/fer/solver.prototxt
http://www.cnblogs.com/denny402/p/5076285.html
Caffe操作5----测试模型

Classification.bin是自带的可执行体
http://www.cnblogs.com/denny402/p/5111018.html
标签:
原文地址:http://www.cnblogs.com/weiqinglan/p/5969016.html