标签:
上两篇说了决策树到集成学习的大概,这节我们通过adaboost来具体了解一下集成学习的简单做法。
集成学习有bagging和boosting两种不同的思路,bagging的代表是随机森林,boosting比较基础的adaboost,高级一点有GBDT,在这里我也说下我理解的这两个做法的核心区别:
随机森林的bagging是采用有放回抽样得到n个训练集,每个训练集都会有重复的样本,每个训练集数据都一样,然后对每个训练集生成一个决策树,这样生成的每个决策树都是利用了整个样本集的一部分,也就说每棵决策树只是学习了大部分,然后决策的时候综合每棵决策树的评分,最终得出一个总的评分
boosting的adaboost每次训练的时候用的是同一个数据集,但是前一棵决策树分错的样本在后面的权重会升高,相当于说,后面的决策树利用了前面决策树学习的结果,不断的优化这个结果,也就是说,后面的决策树恰恰擅长的是前面决策树不擅长(分错)的样本,相当于说,boosting的每棵决策树擅长的“领域”不一样,并且在擅长的领域都很厉害
而对比bagging,bagging中的每一棵树都是同样普通的决策树,相当于每棵决策树擅长的“领域”区分不大,也没有很擅长。
下面我们看下adaboost是如何工作的吧,这次我们使用更简单的例子。
这是二维平面的上的两个点,红色是正样本,绿色是负样本,如果使用强分类器,例如深度大于1的决策树,很简单就可以区分开了,或者使用逻辑回归,计算一下,就可以轻松得到一条直线把这两个类别的点区分开了,我们这里主要是先学习adaboost是如何把弱分类器组装成强大的强分类器以及boosting的学习效果
类别和之前不一样,这里的正负样本的类似是1,-1,原因是预测结果的分界线不一样,决策树是没有对类别做任何的操作,adaboost设计到多棵树的权重相加,使用0作为正负样本的分界线会更好
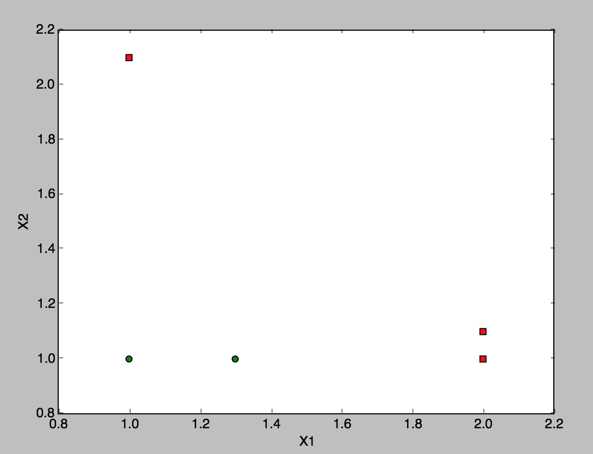
def loadSimpData(): datMat = matrix([[ 1. , 2.1], [ 2. , 1.1], [ 1.3, 1. ], [ 1. , 1. ], [ 2. , 1. ]]) classLabels = [1.0, 1.0, -1.0, -1.0, 1.0] return datMat,classLabels
选择弱分类器:深度为1的决策树无疑是很弱的分类器,深度为1的决策树我们一般称为决策树墩,决策树墩在二维平面上是一条平行坐标轴的直线
对于我们的数据集,决策树墩是没有办法正确划分的,除非能学习出直线之间的组合关系
决策树墩做什么事情:决策树墩做的事情是根据特征的特征值给出判断错误的列表(个数)
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):#just classify the data retArray = ones((shape(dataMatrix)[0],1)) if threshIneq == ‘lt‘: retArray[dataMatrix[:,dimen] <= threshVal] = -1.0 else: retArray[dataMatrix[:,dimen] > threshVal] = -1.0 return retArray
构建决策树墩:设定步伐,遍历所有的特征和步伐(阀值)和方向(大于阀值还是小于阀值),找到最好的特征以及步伐和方向
得到错误率最小的特征,步伐和方向
def buildStump(dataArr,classLabels,D): dataMatrix = mat(dataArr); labelMat = mat(classLabels).T m,n = shape(dataMatrix) numSteps = 10.0; bestStump = {}; bestClasEst = mat(zeros((m,1))) minError = inf #初始化为无穷大 for i in range(n):#遍历所有的特征 rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max(); stepSize = (rangeMax-rangeMin)/numSteps for j in range(-1,int(numSteps)+1):#遍历当前特征的所有步伐 for inequal in [‘lt‘, ‘gt‘]: #遍历当前特征当前步伐的所有方向 threshVal = (rangeMin + float(j) * stepSize) predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)#用该决策树墩去预测,返回预测的结果 errArr = mat(ones((m,1))) errArr[predictedVals == labelMat] = 0 weightedError = D.T*errArr #每个样本的权重*每个样本划分对错(对的为零,错的为一,所以这里计算的是错误的权重) # print "split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError) if weightedError < minError: minError = weightedError bestClasEst = predictedVals.copy() bestStump[‘dim‘] = i bestStump[‘thresh‘] = threshVal bestStump[‘ineq‘] = inequal return bestStump,minError,bestClasEst
下面是adaboost的核心内容:如何提高划分错的样本的权重
首先用当前划分的错误计算得到一个α值(每个决策树墩的权重),然后对每个样本根据区分对错改变其权重值,最后最改变权重后的样本的权重做归一化


def adaBoostTrainDS(dataArr,classLabels,numIt=40): weakClassArr = [] m = shape(dataArr)[0] D = mat(ones((m,1))/m) #一开始所有样本的权重一样 aggClassEst = mat(zeros((m,1))) for i in range(numIt): bestStump,error,classEst = buildStump(dataArr,classLabels,D)#构建决策树墩,找到最优的决策树墩 #print "D:",D.T alpha = float(0.5*log((1.0-error)/max(error,1e-16)))#计算α值 bestStump[‘alpha‘] = alpha #print "classEst: ",classEst.T expon = multiply(-1*alpha*mat(classLabels).T,classEst) #计算新的权重 D = multiply(D,exp(expon)) #权重归一化 D = D/D.sum() #每个样本到当前的评分 aggClassEst += alpha*classEst #得到分类错误的列表(分对为零,分错为1,计算内积,得到分错的个数) aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1))) errorRate = aggErrors.sum()/m print "total error: ",errorRate bestStump[‘error_rate‘]=errorRate weakClassArr.append(bestStump) #记录每一棵最优的决策树墩 if errorRate == 0.0: break return weakClassArr,aggClassEst
下面我们看每一棵决策树墩的分类的效果吧:样本类别如下:
[1.0, 1.0, -1.0, -1.0, 1.0]
每个样本的权重如下
[ 0.2 0.2 0.2 0.2 0.2]
第一棵决策树,X1小于等于1.3为负样本,这棵树的权重为0.69,错误率0.2(分错了一个),每个样本被预测的结果如下:
[-0.69314718 0.69314718 -0.69314718 -0.69314718 0.69314718]
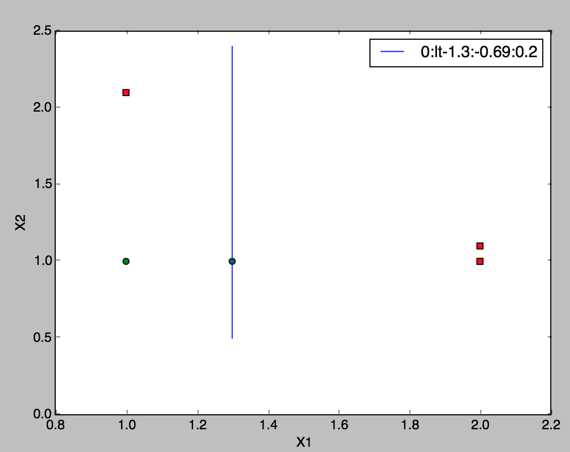
第一次权重调整:可以发现第一个样本(被分错的)权重升高了
[ 0.5 0.125 0.125 0.125 0.125]
两棵决策树:第二棵决策树X2小于等于1.0为负样本,权重0.97,错误率还是0.2,样本预测总评分如下
[ 0.27980789 1.66610226 -1.66610226 -1.66610226 -0.27980789]
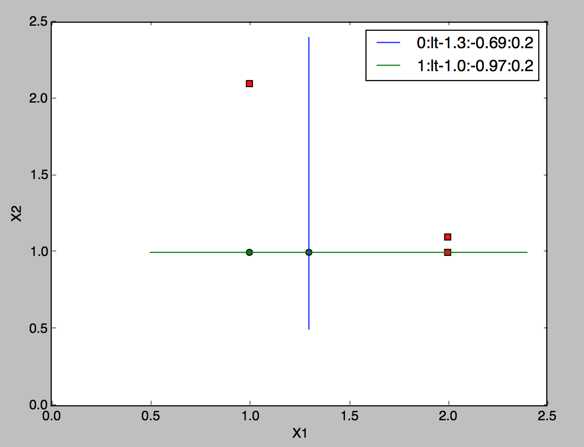
第二次调整权重,可以看到最后一次被分错的权重最高,前一次被分错的稍小,一直被分对的概率最小
[ 0.28571429 0.07142857 0.07142857 0.07142857 0.5 ]
看下三棵决策树墩的效果:X1小于等于0.9的为负样本,权重0.9,错误率0,所有样本评分如下:可以发现虽然每个正样本的评分都大于0,但是有些评分已经高达2.5了,不过我们也发现,最后的评分跟一直分对或者分错没什么关系
[ 1.17568763 2.56198199 -0.77022252 -0.77022252 0.61607184]
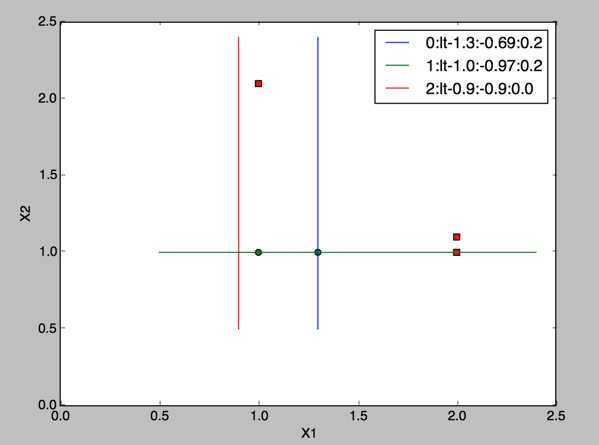
在这个简单的数据中,错误率可以降到0,但是不是所有的数据集都可以达到错误率为0的,比如我们前面的100个点的实验
真正的原因在于数据集在特征维度是否是超平面可分的,如果可以,adaboost理论上可以把错误率降到0
希望到这里大家可以理解adaboost,理解集成学习。
标签:
原文地址:http://www.cnblogs.com/qwj-sysu/p/5970760.html