标签:
谈谈互联网后端基础设施
来自:http://chuansong.me/n/717637351233
对于一个互联网企业,后端服务是必不可少的一个组成部分。抛开业务应用来说,往下的基础服务设施做到哪些才能够保证业务的稳定可靠、易维护、高可用呢?纵观整个互联网技术体系再结合公司的目前状况,个人认为必不可少或者非常关键的后端基础技术/设施如下图所示:
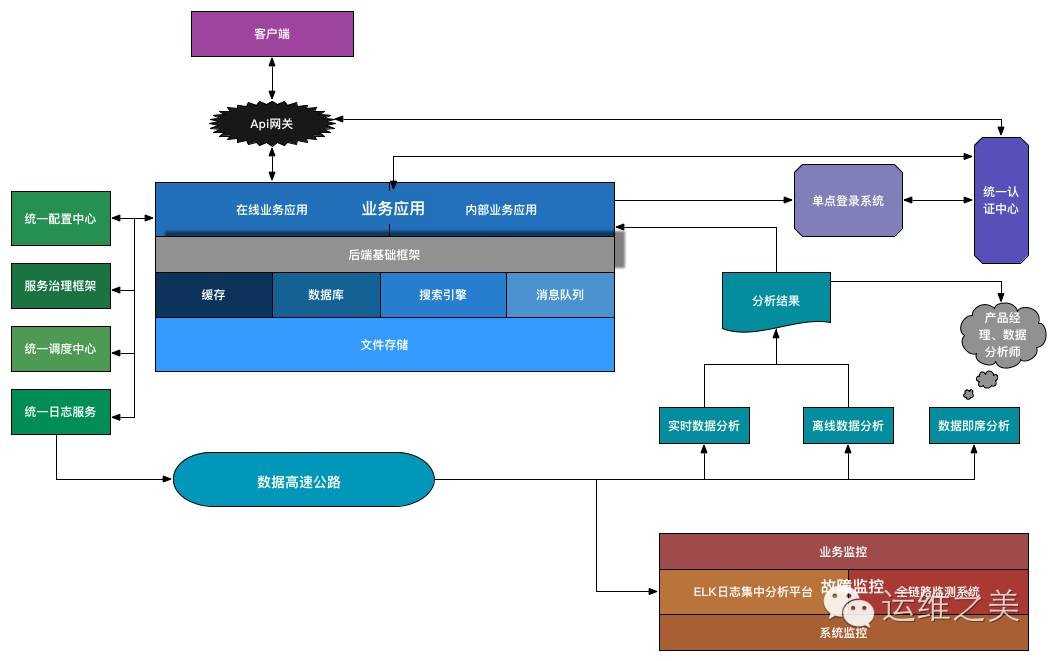
这里的后端基础设施主要指的是应用在线上稳定运行需要依赖的关键组件/服务等。开发或者搭建好以上的后端基础设施,一般情况下是能够支撑很长一段时间内的业务的。此外,对于一个完整的架构来说,还有很多应用感知不到的系统基础服务,如负载均衡、自动化部署、系统安全等,并没有包含在本文的描述范围内。
Api网关
在移动app的开发过程中,通常后端提供的接口需要以下功能的支持:
一般的做法,使用nginx做负载均衡,然后在每个业务应用里做api接口的访问权限控制和用户鉴权,更优化一点的方式则是把后两者做成公共类库供所有业务调用。但从总体上来看,这三种特性都属于业务的公共需求,更可取的方式则是集成到一起作为一个服务,既可以动态地修改权限控制和鉴权机制,也可以减少每个业务集成这些机制的成本。这种服务就是Api网关(http://blog.csdn.net/pzxwhc/article/details/49873623),可以选择自己实现,也可以使用开源软件实现,如Kong。如下图所示:
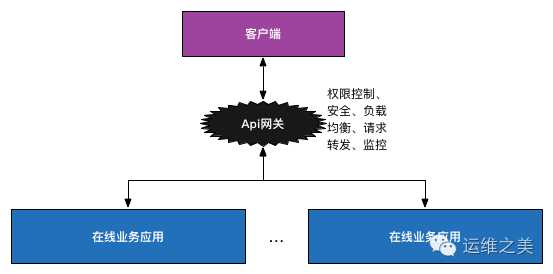
但是以上方案的一个问题是由于所有api请求都要经过网关,它很容易成为系统的性能瓶颈。因此,可以采取的方案是:去掉api网关,让业务应用直接对接统一认证中心,在基础框架层面保证每个api调用都需要先通过统一认证中心的认证,这里可以采取缓存认证结果的方式避免对统一认证中心产生过大的请求压力。
业务应用和后端基础框架
业务应用分为:在线业务应用和内部业务应用。
业务应用基于后端的基础框架开发,针对Java后端来说,应该有的几个框架如下:
一般来说,以上几个框架即可以完成一个后端应用的雏形。
对于这些框架来说,最为关键的是根据团队技术构成选择最合适的,有能力开发自己的框架则更好。此外,这里需要提供一个后端应用的模板或生成工具(如maven的archetype)给团队成员使用,可以让大家在开发新的应用的时候,迅速的生成雏形应用,而无需再做一些框架搭建的重复性劳动。
缓存、数据库、搜索引擎、消息队列
缓存、数据库、搜索引擎、消息队列这四者都是应用依赖的后端基础服务,他们的性能直接影响到了应用的整体性能,有时候你代码写的再好也许就是因为这些服务导致应用性能无法提升上去。
缓存
如缓存五分钟法则所讲:如果一个数据频繁被访问,那么就应该放内存中。这里的缓存就是一种读写效率都非常高的存储方案,能够应对高并发的访问请求,通常情况下也不需要持久化的保证。但相对其他存储来说,缓存一般是基于内存的,成本比较昂贵,因此不能滥用。
缓存可以分为:本地缓存和分布式缓存。
对于缓存的使用,需要注意以下几点:
对于其具体的实现机制,可以参考《Redis设计与实现》一书
数据库
数据库是后端开发中非常常见的一个服务组件。对于数据库的选型,要根据业务的特点和数据结构的特点来决定。
从存储介质上,数据库可以分为:
从存储数据类型、数据模式上,数据库可以分为:
和数据库相关的一个很重要的就是数据库的索引。有一种说法是:“掌握了索引就等于掌握了数据库”。暂且不去评判此说法是否真的准确,但索引的确关系着数据库的读写性能。需要对数据库的索引原理做到足够的了解才能更好的使用各种数据库。通常来说,Mysql、Oracle、Mongodb这些都是使用的B树作为索引,是考虑到传统硬盘的特点后兼顾了读写性能以及范围查找需求的选择,而Hbase用得LSM则是为了提高写性能对读性能做了牺牲。
搜索引擎
搜索引擎也是后端应用中一个很关键的组件,尤其是对内容类、电商类的应用,通过关键词、关键字搜索内容、商品是一个很常见的用户场景。比较成熟的开源搜索引擎有Solr和Elasticsearch,很多中小型互联网公司搜索引擎都是基于这两个开源系统搭建的。它们都是基于Lucence来实现的,不同之处主要在于termIndex的存储、分布式架构的支持等等。
对于搜索引擎的使用,从系统熟悉、服务搭建、功能定制,需要花费较长时间。在这个过程中,需要注意以下问题:
更为详细的对于搜索引擎的工程化实践可以参考有赞工程师的这篇文章:有赞搜索引擎实践(工程篇)
另外,搜索引擎还可以用在数据的多维分析上,就是GrowingIO、MixPanel中的可以任意维度查询数据报表的功能。当然,druid也许是一个更好的实现多维分析的方案,官方也有其与es的比较:http://t.cn/RcGFIxn。
消息队列
软件的组织结构,从开始的面向组件到SOA、SAAS是一个逐渐演变的过程。而到了今天微服务盛行的时代,你都不好意思说自己的系统只是单一的一个系统而没有解耦成一个个service。当然,小的系统的确没有拆分的必要性,但一个复杂的系统拆成一个个service做微服务架构确实是不得不做的事情。
那么问题就来了,service之间的通信如何来做呢?使用什么协议?通过什么方式调用?都是需要考虑的问题。
先抛开协议不谈,service之间的调用方式可以分为同步调用以及异步调用。同步调用的方式无需多说,那么异步调用是怎么进行的呢?一种很常见的方式就是使用消息队列,调用方把请求放到队列中即可返回,然后等待服务提供方去队列中去获取请求进行处理,然后把结果返回给调用方即可(可以通过回调)。
异步调用就是消息中间件一个非常常见的应用场景。此外,消息队列的应用场景还有以下:
目前主流的消息队列软件,主要有以下几种:
文件存储
不管是业务应用、依赖的后端服务还是其他的各种服务,最终还是要依赖于底层文件存储的。通常来说,文件存储需要满足的特性有:可靠性、容灾性、稳定性,即要保证存储的数据不会轻易丢失,即使发生故障也能够有回滚方案,也要保证高可用率。在底层可以采用传统的RAID作为解决方案,再上一层,目前hadoop的hdfs则是最为普遍的分布式文件存储方案,当然还有NFS、Samba这种共享文件系统也提供了简单的分布式存储的特性。
此外,如果文件存储确实成为了应用的瓶颈或者必须提高文件存储的性能从而提升整个系统的性能时,那么最为直接和简单的做法就是抛弃传统机械硬盘,用SSD硬盘替代。像现在很多公司在解决业务性能问题的时候,最终的关键点往往就是SSD。这也是用钱换取时间和人力成本最直接和最有效的方式。在数据库部分描述的SSDB就是对LevelDB封装之后,利用SSDB的特性的一种高性能KV数据库。
至于HDFS,如果要使用上面的数据,是需要通过hadoop的。类似xx on yarn的一些技术就是将非hadoop技术跑在hdfs上的解决方案(当然也是为了使用MR)。
统一认证中心
统一认证中心,主要是对app用户、内部用户、app等的认证服务,包括
之所以需要统一认证中心,就是为了能够集中对这些所有app都会用到的信息进行管理,也给所有应用提供统一的认证服务。尤其是在有很多业务需要共享用户数据的时候,构建一个统一认证中心是非常必要的。此外,通过统一认证中心构建移动app的单点登录也是水到渠成的事情(模仿web的机制,将认证后的信息加密存储到本地磁盘中供多个app使用)。
单点登录系统
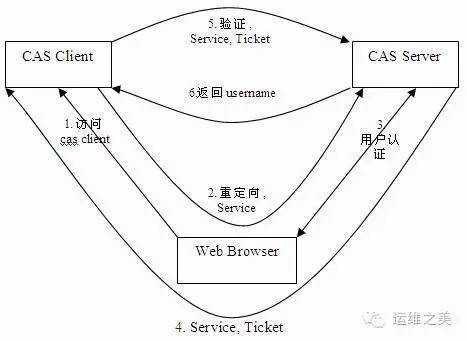
目前很多大的在线web网站都是有单点登录系统的,通俗的来说就是只需要一次用户登录,就能够进入多个业务应用(权限可以不相同),非常方便用户的操作。而在移动互联网公司中,内部的各种管理、信息系统同样也需要单点登录系统。目前,比较成熟的、用的最多的单点登录系统应该是耶鲁大学开源的CAS, 可以基于https://github.com/apereo/cas/tree/master/cas-server-webapp来定制开发的。此外,国人开源的kisso的这个也不错。基本上,单点登录的原理都类似下图所示:
统一配置中心
在Java后端应用中,一种读写配置比较通用的方式就是将配置文件写在propeties、yaml、HCON文件中,修改的时候只需要更新文件重新部署即可,可以做到不牵扯代码层面改动的目的。统一配置中心,则是基于这种方式之上的统一对所有业务或者基础后端服务的相关配置文件进行管理的统一服务, 具有以下特性:
disconf是可以在生产环境使用的一个方案,也可能根据自己的需求开发自己的配置中心(可以选择zookeeper作为配置存储)。
服务治理框架
对于外部API调用或者客户端对后端api的访问,可以使用http协议或者说restful(当然也可以直接通过最原始的socket来调用)。但对于内部服务间的调用,一般都是通过RPC机制来调用的。目前主流的RPC协议有:
这些RPC协议各有优劣点,需要针对业务需求做出相应的最好的选择。
这样,当你的系统服务在逐渐增多,RPC调用链越来越复杂,很多情况下,需要不停的更新文档来维护这些调用关系。一个对这些服务进行管理的框架可以大大节省因此带来的繁琐的人力工作。
传统的ESB(企业服务总线)本质就是一个服务治理方案,但esb作为一种proxy的角色存在于client和server之间,所有请求都需要经过esb,使得esb很容易成为性能瓶颈。因此,基于传统的esb,更好的一种设计如下图所示:
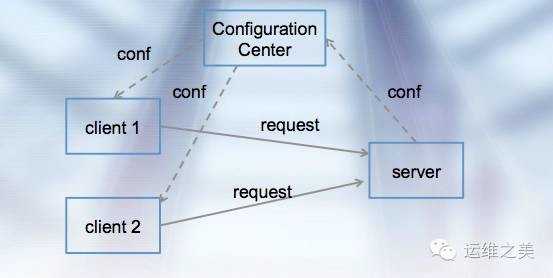
如图,以配置中心为枢纽,调用关系只存在于client和提供服务的server之间,就避免了传统esb的性能瓶颈问题。对于这种设计,esb应该支持的特性如下:
阿里开源的dubbo则对以上做了很好的实现,也是目前很多公司都在使用的方案。但由于某些原因,dubbo现已不再维护,推荐大家使用当当后来维护的dubbox。
统一调度中心
在很多业务中,定时调度是一个非常普遍的场景,比如定时去抓取数据、定时刷新订单的状态等。通常的做法就是针对各自的业务依赖Linux的cron机制或者java中的quartz。统一调度中心则是对所有的调度任务进行管理,这样能够统一对调度集群进行调优、扩展、任务管理等。azkaban和oozie是hadoop的流式工作管理引擎,也可以作为统一调度中心来使用。当然,你也可以使用cron或者quartz来实现自己的统一调度中心。
对于Java的quartz这里需要说明一下:这个quartz需要和spring quartz区分,后者是spring对quartz框架的简单实现也是目前使用的最多的一种调度方式。但是,其并没有做高可用集群的支持。而quartz虽然有集群的支持,但是配置起来非常复杂。现在很多方案都是使用zookeeper来实现spring quartz集群的。这里有一个国人开源的uncode-shcedule对此实现的还不错,可以根据自己的业务需求做二次开发。
统一日志服务
日志是开发过程必不可少的东西。有时候,打印日志的时机、技巧是很能体现出工程师编码水平的。毕竟,日志是线上服务能够定位、排查异常最为直接的信息。
通常的,将日志分散在各个业务中非常不方便对问题的管理和排查。统一日志服务则使用单独的日志服务器记录日志,各个业务通过统一的日志框架将日志输出到日志服务器上。
可以通过实现log4j后者logback的appender来实现统一日志框架,然后通过RPC调用将日志打印到日志服务器上。
数据基础设施
数据是最近几年非常火的一个领域。从《精益数据分析》到《增长黑客》,都是在强调数据的非凡作用。很多公司也都在通过数据推动产品设计、市场运营、研发等。详细的可见之前的一篇《数据杂谈》,对数据相关的东西做过一些总结。这里需要说明的一点是,只有当你的数据规模真的到了单机无法处理的规模才应该上大数据相关技术,千万不要为了大数据而大数据。很多情况下使用单机程序+mysql就能解决的问题非得上hadoop即浪费时间又浪费人力。
这里需要补充一点的是,对于很多公司,尤其是离线业务并没有那么密集的公司,在很多情况下大数据集群的资源是被浪费的。因此诞生了xx on yarn一系列技术让非hadoop系的技术可以利用大数据集群的资源,能够大大提高资源的利用率,如Docker on yarn(Hulu的VoidBox)。
数据高速公路
接着上面讲的统一日志服务,其输出的日志最终是变成数据到数据高速公路上供后续的数据处理程序消费的。这中间的过程包括日志的收集、传输。
此外,这里还有一个关键的技术就是数据库和数据仓库间的数据同步问题,即将需要分析的数据从数据库中同步到诸如hive这种数据仓库时使用的方案。比较简单的、用的也比较多的可以使用sqoop进行基于时间戳的数据同步,此外,阿里开源的canal实现了基于binlog增量同步,更加适合通用的同步场景,但是基于canal你还是需要做不少的业务开发工作的。推荐另一款国人开源的MySQL-Binlog,原理和canal类似,默认提供了任务的后台管理功能,只需要实现接收到binlog后的处理逻辑即可。
离线数据分析
离线数据分析是可以有延迟的,一般针对是非实时需求的数据分析工作,产生的也是T-1的报表。目前最常用的离线数据分析技术除了hadoop还有spark。相比hadoop,spark性能上有很大优势,当然对硬件资源要求也高。
对于hadoop,传统的MR编写很复杂,也不利于维护,可以选择使用hive来用sql替代编写mr,但是前提务必要对hive的原理做到了解。可以参见美团的这篇博文来学习:Hive SQL的编译过程。而对于spark,也有类似hive的spark sql。
此外,对于离线数据分析,还有一个很关键的就是数据倾斜问题。所谓数据倾斜指的是region数据分布不均,造成有的结点负载很低,而有些却负载很高,从而影响整体的性能。因此,处理好数据倾斜问题对于数据处理是很关键的。对于hive的数据倾斜,可见:hive大数据倾斜总结。对于spark的倾斜问题,可见:Spark性能优化指南——高级篇。
实时数据分析
相对于离线数据分析,实时数据分析也叫在线数据分析,针对的是对数据有实时要求的业务场景,如广告结算、订单结算等。目前,比较成熟的实时技术有storm和spark streaming。相比起storm,spark streaming其实本质上还是基于批量计算的。如果是对延迟很敏感的场景,还是应该使用storm。
对于实时数据分析,需要注意的就是实时数据处理结果写入存储的时候,要考虑并发的问题,虽然对于storm的bolt程序来说不会有并发的问题,但是写入的存储介质是会面临多任务同时读写的。通常采用的方案就是采用时间窗口的方式对数据做缓冲后批量写入。
此外,实时数据处理一般情况下都是基于增量处理的,相对于离线来说并非可靠的,一旦出现故障(如集群崩溃)或者数据处理失败,是很难对数据恢复或者修复异常数据的。因此结合离线+实时是目前最普遍采用的数据处理方案。Lambda架构就是一个结合离线和实时数据处理的架构方案。
数据即席分析
离线和实时数据分析产生的一些报表是给数据分析师、产品经理参考使用的,但是很多情况下,线上的程序并不能满足这些需求方的需求。这时候就需要需求方自己对数据仓库进行查询统计。针对这些需求方,SQL上手容易、易描述等特点决定了其可能是一个最为合适的方式。因此提供一个SQL的即席查询工具能够大大提高数据分析师、产品经理的工作效率。Presto、Impala、Hive都是这种工具。如果想进一步提供给需求方更加直观的ui操作界面,可以搭建内部的Hue。
故障监控
对于面向用户的线上服务,发生故障是一件很严重的事情。因此,做好线上服务的故障检测告警是一件非常重要的事情。可以将故障监控分为以下两个层面的监控:
监控还有一个关键的步骤就是告警。告警的方式有很多种:邮件、im、短信等。考虑到故障的重要性不同、告警的合理性、便于定位问题等因素,有以下建议:
故障告警之后,那么最最关键的就是应对了。对于创业公司来说,24小时待命是必备的素质,当遇到告警的时候,需要尽快对故障做出反应,找到问题所在,并能在可控时间内解决问题。对于故障问题的排查,基本上都是依赖于日志的。只要日志打的合理,一般情况下是能够很快定位到问题所在的,但是如果是分布式服务,并且日志数据量特别大的情况下,如何定位日志就成为了难题。这里有几个方案:
标签:
原文地址:http://www.cnblogs.com/dragonsuc/p/5974148.html