标签:
从写nodejs的第一个爬虫开始陆陆续续写了好几个爬虫,从爬拉勾网上的职位信息到爬豆瓣上的租房帖子,再到去爬知乎上的妹子照片什么的,爬虫为我打开了一扇又一扇新世界的大门。除了涨了很多姿势之外,与网管斗智斗勇也是一个比较有意思的事情。虽然很多东西都是浅尝辄止,但万事都有个由浅入深的过程嘛(天真脸~~)
爬虫?应该是长这样的吧:

其实,没有那么萌啦。
所谓爬虫,就是把目标网站的信息收集起来的一种工具。基本流程跟人访问网站是一样的,打开链接>>获取信息>>打开链接……这个循环用编程实现,就是爬虫了。专业一点的说法就是,发起请求>>解析响应数据。普通网站访问的时候,返回值是一个html文本,这时候需要解析html文本获取所需信息,比如可以用cheerio这种类jQuery的操作dom的方式去解析html文本;而使用ajax动态生成内容的网站,可以直接去请求相应的接口,从而直接获得数据。爬虫爬的,就是这些url或者接口,慢慢地爬呀爬,直到世界尽头~~~
获取信息是爬虫的核心,但是最有技术含量的却不在于此。爬虫路上的第一个大敌,就是网管了。由于太多人利用爬虫去剽窃别人的成果,所以爬虫在生产内容的网站都不受待见。就想农民伯伯辛辛苦苦种大的大白菜,自然是不希望被猪拱了。网管叔叔们通常会根据爬虫的特征来辨别爬虫,大体上有这么几个方面:
1) 检查请求头。一些很初级的爬虫只是单纯得发请求,连最基本的user agent之类的请求头都没有,看见这种请求,不用说也知道是爬虫了。除了user agent,Referer也是一个通常被用来检查爬虫的字段。
2) 判断用户行为。很多网站在未登录状态的时候会经常返回登录页面让用户登录,用户登录之后通过统计用户访问行为就可以判断出用户是不是人,比如在短时间内进行了大量的访问,这显然不是人力所能做到的了。
3) 判断IP的访问量。如果一个ip在短时间内进行了大量的访问,显然,这也不是人干的事。尤其是同一IP出现高并发的情况,这种会加重服务器负荷甚至搞垮服务器的爬虫,绝对是网管的眼中钉肉中刺。
4) 根据浏览器行为判断。浏览器在打开网页的时候会自动将网页中的图片、css、js等资源加载下来,但是爬虫却只是获取了网页的文本,并不会自动加载相关的资源,通过这一特征也能很好区分爬虫。比如说在网页中加入一个会自动发请求的js文件,服务器端如果接收不到这个请求就可以认为是爬虫在访问了。但是这招对利用浏览器内核写成的爬虫或者是高级爬虫来说就不管用了。
通常网管们比较常用的是就是前3种方式的组合,第4点需要开发改动前后端代码,这对身为运维的网管叔叔们来说,给开发提需求可不容易啊。但如果在开发阶段就已经考虑到防火防盗防爬虫的话,那就会对接口进行加密或是校验了。虽然说前端代码都是裸奔的,但是假如有意去混淆js的话,想要破解出加密算法也不是那么简单的。校验就跟普通的应付csrf攻击的做法也相差无几,在页面中嵌入服务器端返回的随机数,接口调用时校验这个随机数即可。
但是俗话说,你有张良计,我有过墙梯。即使网管叔叔好像做了很多反爬虫的工作,但是人民群众的智商是无限的。
什么,你要检查请求头?你要什么样的header,我这里都有!根据IP判断?花几十块买了一堆高匿代理服务器呢。判断用户行为?呵呵,我有一堆小号呀~

具体来说:
1)伪造header。这实在太简单了,随便打开一个浏览器F12,把请求的header都复制一遍,不要太完整哦。
2)多用户爬虫。提前注册好一堆小号,登录之后F12分析cookie,找出账号相关的cookie,将cookie按账号存到数组中不断轮换即可。在有csrf防御策略的网站上,还需要分析token的来源,在请求的时候带上预埋的token即可。例如知乎就在网页中预埋了一个_xsrf,在请求的时候要带上这个自定义头才可以获得请求的权限。
3)多IP爬虫。这个就稍微复杂一些,主要是高匿代理IP比较难搞到手。网上的免费代理不少,能用的不多。要么掏钱,要么就做一个爬虫来爬取可用的代理服务器吧。
4)接口参数解密。这种情况下,参数被加密成一个密码字符串,服务器端通过解密算法来还原参数,也就是说每次请求的参数都是不同的。这里的关键在于找到加密算法和钥匙,而前端的js通常也会被混淆加密,所以这种情况是最复杂的。目前我还没遇到这种情况,所以就不多说了。
如果一只爬虫动不动就几百个并发,这吃相就难看了。所以我们通常会控制一下并发和爬取间隔,尽量不干扰服务器的正常运转。这就是一只爬虫的修养了。

流程控制方面你可以使用集成的async库,也可以手动管理流程,时刻考虑异常情况就可以写出最贴合你要求的控制流程了。现在es7从语言上加入了async、await语法糖,手动编码的代码也非常优雅了。
1)知乎图片爬虫:这个是受不了一个曾经很火的帖子诱惑而写的(长得好看,但没有男朋友是怎样的体验? ),这个爬虫可以爬取任一话题下所有回答中的图片并下载到本地目录下,你们感受下:
如你所见,大部分妹子长得并没有很好看。。。。(心酸泪奔)
但是!质量不行,我还有数量呀: 
其实并不是很有动力写这种爬虫,不过看到答案中一个家伙写了一个爬虫,但是却只能爬第一页。。。这是什么感觉?就好像是拉链还没拉下来,片子却播完了!忍不住,就写了一个可以下载所有答案的爬虫,然后还用数据库和json两种方式储存了一下数据。刚看的数据库,学以致用!源码和相应说明均在文后有给出。
2)豆瓣小组爬虫:这个是我在豆瓣上找房子的时候写的简单爬虫,这个爬虫的吃相比较难看!。!因为没有控制并发。。。因为租房帖子的更新非常快,所以就爬取了最新的10页(250条)帖子,主要逻辑就是对标题进行关键词的筛选,将符合条件的帖子输出到网页中(这里用json文件来示范了)。结果大概长这个样子:

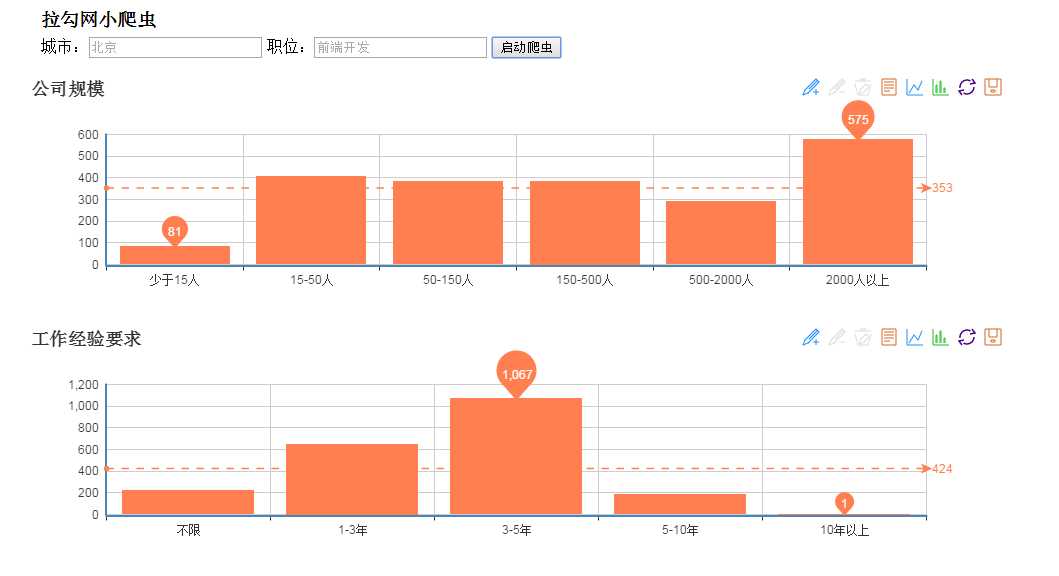
3)拉勾网爬虫:这个是在换工作的时候写的一个很简单的爬虫,主要是想统计一下不同岗位的需求情况、公司分布,本来还想要结合地图做分布图、热力图什么的,最后也是不了了之。只是简单地用echart做了一个图表就完事了,太简陋!拉钩是ajax接口返回数据的,而且没有加密,实在是太好爬了!反爬虫的策略是基于IP的,单个ip访问频繁就会被封哦,要注意!
PS:上面提到的爬虫都在我的 github 上了,觉得不错的哥们请赏颗星星哈!
好久没写文字了,最近一直在看后端相关的东西、还看了下比较火的Vue,感觉收获还是蛮大的,后续会分享相关的学习感悟,敬请期待!
最后,还是惯例放图吧。(幸好假期出去了一趟,不然都没图可放了,囧囧囧)

原创文章,转载请注明出处!本文链接:http://www.cnblogs.com/qieguo/p/5859927.html
标签:
原文地址:http://www.cnblogs.com/qieguo/p/5859927.html