标签:
SGD, BGD初步描述
(原文来自:http://blog.csdn.net/lilyth_lilyth/article/details/8973972,@熊均达@SJTU 做出解释及说明)
梯度下降(GD)是最小化风险函数、损失函数(注意Risk Function和Cost Function在本文中其实指的一个意思,在不同应用领域里面可能叫法会有所不同。解释:@熊均达@SJTU)的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正。
下面的h(x)是要拟合的函数,J(θ)损失函数,θ是参数,要迭代求解的值,theta求解出来了那最终要拟合的函数h(θ)就出来了。其中m是训练集的记录条数,j是参数的个数。
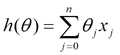
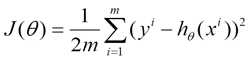
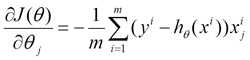
(2)由于是要最小化风险函数(注意这里用了风险函数,其实就是损失函数。解释:@熊均达@SJTU),所以按每个参数θ的梯度负方向,来更新每个θ
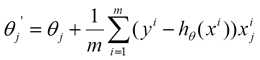
(3)从上面公式可以注意到,它得到的是一个全局最优解,但是每迭代一步,都要用到训练集所有的数据,如果m很大,那么可想而知这种方法的迭代速度!!所以,这就引入了另外一种方法,随机梯度下降。
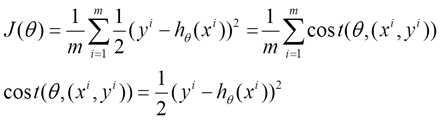
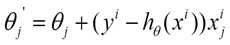
@熊均达@SJTU附注1:在BGD中,你需要把所有的样本都考虑,求所有样本处的误差的平方和。而对于SGD,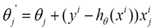 遍历到哪里就是哪里。
遍历到哪里就是哪里。
批量梯度下降 | 随机梯度下降 |
批量更新算法 | 在线算法 |
经验风险 | 泛化风险 |
可能陷入局部最优(初值选择敏感) | 可能找到全局最优 |
对步长不敏感 | 对步长敏感 |
迭代次数少 | 迭代次数多 |
计算量大 | 计算量不大 |
对于线性回归问题,批量梯度下降和随机梯度下降是如何找到最优解的?
最后附上带有大量干货的斯坦福CS229课程主页网址:http://cs229.stanford.edu/materials.html
有兴趣的同学可以自行查阅,其实网上大部分的资料都是根据这些资料翻译的,但是这些更权威。
参考资料:
Batch Gradient Descendent (BGD) & Stochastic Gradient Descendent (SGD)
标签:
原文地址:http://www.cnblogs.com/kaixiao/p/5975785.html