标签:
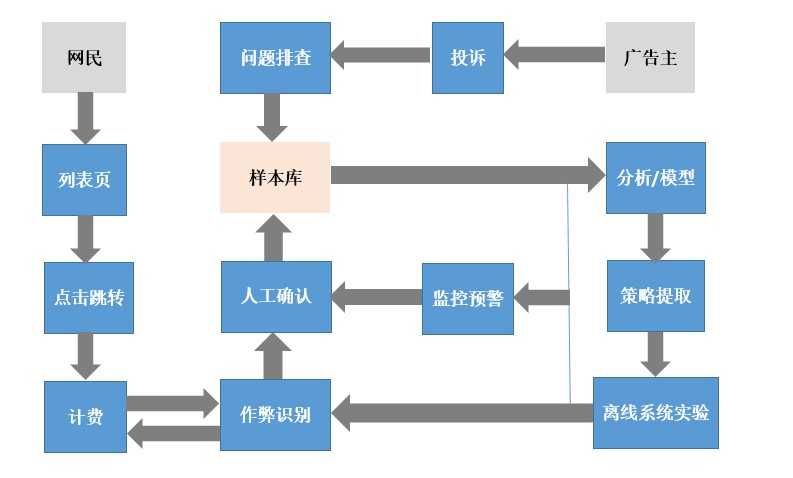
反作弊主要业务流程:
常见作弊方式:
机器作弊:机器刷量、任务分发、流量劫持
人为作弊:QQ群/水军、直接人工、诱导
常见作弊手段:
电商:刷单,刷信誉,刷好评,职业差评师
支付平台:洗钱,诈骗
广告:数据造假、刷流量 (引流—广告展示—广告点击—转化)
自媒体、社交软件:刷粉丝、刷点击、阅读量
搜索:seo使用作弊手段刷排名(案例:2015蜻蜓FM “普罗米修斯”、“宙斯”函数,修改转化量、流量在前端展现欺骗投资人,被对手反编译识破)
广告作弊涉及的点击类型分类:
1、 按照是否找商品找服务为目的
2、 是否按照是否恶意,有无真实转化为依据
(CPC基于点击计费的模式、CPA基于成交的点击进行收费)
点击四大分类:
无效点击(没有形成转化的意愿,仅仅浏览)
恶意点击(必须识别出来)
转化点击(真实意愿点击)
误点(不是以找商品为目的,例如内部人员点击,需要识别出来)
人群划分:
误点:员工、广告主自己、竞品销售中介、爬虫
恶意点击:同行、同行朋友、联盟站点、机器
反作弊策略应对框架:
数据层:鼠标轨迹行为、指纹数据、案例库、行为数据
特征层:离散指标、连续指标
行为识别层:点击识别模型、异常监测模型、流量识别模型、关系图模型、人群识别模型
策略应对层:规则
三层监控指标体系,提前预警:
运营指标监控:投诉率、转化率、撞线速率/频率、消耗速率、通过率
规则监控指标:拦截率、准确率、覆盖率
异常监控指标:IP维度、Cookie维度、计费名维度、广告维度、设备维度、鼠标轨迹维度
分类监控、分级响应:
1、 针对监控情况、采用四级响应机制;
2、 红色:非常严重,需要自动化采取短期策略应对,例如临时黑名单机制
3、 橙色:较为严重,短信举报,要求4h内完成分析和短平快策略压制,后续进一步处理
机器学习在反作弊应用几个案例:
如关联规则、决策树模型:策略挖掘—规则自动提取
确定建模问题:自动发现规则、辅助策略设计;
应用:挖出的规则,上线到离线反作弊系统
评估指标:支持度、置信度、覆盖率、拦截率
流量聚类分级模型,kmeans算法:异常行为识别—流量识别
作用:支持流量分级打折策略
例如分为以下类别,特征描述:
1、 主要为品牌浏览器入口,转化效果较好,用户粘性较高;
2、 电话转化很好,包括搜索行为、点击行为、转化行为都较好;
3、 电话转化良好,没有明显的特征异常;
4、 电话转化率略偏低,详情页其它点击行为略偏少;
5、 详情页停留时间短,转化效果特别差;
6、 电话转化很好,无其它任何转化行为,专门点击商业广告,行为非常异常;
7、 点击率高,无转化,行为非常异常.
如半监督或图算法:异常行为识别—基于关系发现:
作弊用户标签比较少,如何召回更多的数量?
借助半监督或图算法发现更多的异常用户·
SVM算法:异常行为识别—销售识别
作用:识别用户是否销售
数据来源:行为日志,聊天记录
惩罚系数C,选择RBF函数作为kernel的参数gamma的选择.
粗粒度搜索:
对大数据集,先选择一个较小的子集做粗粒度搜索;
选择较大的步长,找到一个最优的(c,g)局部区域.
细粒度搜索:
在局部区域,以较小的步长,找到全局最优的(c,g)
如图论与余弦距离:搜索引擎防作弊
图论:作弊的网站一般需要相互链接,以提高自己的排名,这样在互联网大图中形成一些Clique.图论中有专门发现Clique的方法.
余弦距离:那些卖链接的网站,都有大量的出链(这些出链的特点和不作弊的网站出链特点大不相同).每一个网站到其他网站的出链数目可以作为一个向量,计算余弦距离.发现,有些网站的出链向量之间的余弦距离几乎为1.一般来讲这些网站通常是一个人建的,目的只有一个:卖链接.
标签:
原文地址:http://www.cnblogs.com/dudumiaomiao/p/5982861.html