标签:项目 学习 记录 分享 过程 信息 port 集中 参考
声明:
机器学习系列主要记录自己学习机器学习算法过程中的一些参考和总结,其中有部分内容是借鉴参考书籍和参考博客的。
目录:
一、什么是关联规则
所谓数据挖掘就是以某种方式分析源数据,从中发现一些潜在的有用的信息,即数据挖掘又可以称作知识发现。而机器学习算法则是这种“某种方式”,关联规则作为十大经典机器学习算法之一,因此搞懂关联规则(虽然目前使用的不多)自然有着很重要的意义。顾名思义,关联规则就是发现数据背后存在的某种规则或者联系。
举个简单的例子(尿布和啤酒太经典):通过调研超市顾客购买的东西,可以发现30%的顾客会同时购买床单和枕套,而在购买床单的顾客中有80%的人购买了枕套,这就存在一种隐含的关系:床单→枕套,也就是说购买床单的顾客会有很大可能购买枕套,因此商场可以将床单和枕套放在同一个购物区,方便顾客购买。
一般,关联规则可以应用的场景有:
二、概念
假如有一条规则:牛肉—>鸡肉,那么同时购买牛肉和鸡肉的顾客比例是3/7,而购买牛肉的顾客当中也购买了鸡肉的顾客比例是3/4。这两个比例参数是很重要的衡量指标,它们在关联规则中称作支持度(support)和置信度(confidence)。对于规则:牛肉—>鸡肉,它的支持度为3/7,表示在所有顾客当中有3/7同时购买牛肉和鸡肉,其反应了同时购买牛肉和鸡肉的顾客在所有顾客当中的覆盖范围;它的置信度为3/4,表示在买了牛肉的顾客当中有3/4的人买了鸡肉,其反应了可预测的程度,即顾客买了牛肉的话有多大可能性买鸡肉。其实可以从统计学和集合的角度去看这个问题, 假如看作是概率问题,则可以把“顾客买了牛肉之后又多大可能性买鸡肉”看作是条件概率事件,而从集合的角度去看,可以看下面这幅图:
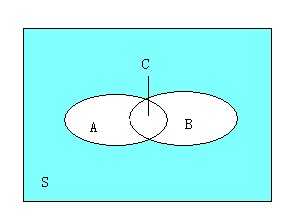
上面这副图可以很好地描述这个问题,S表示所有的顾客,而A表示买了牛肉的顾客,B表示买了鸡肉的顾客,C表示既买了牛肉又买了鸡肉的顾客。那么C.count/S.count=3/7,C.count/A.count=3/4。
三、实现过程
四、如何生成频繁项集
五、注意点
六、总结
标签:项目 学习 记录 分享 过程 信息 port 集中 参考
原文地址:http://www.cnblogs.com/hdu-cpd/p/5987904.html