标签:table dex style equals shc 情况 效率 ext factor
HashMap
HashMap实现了Map接口,继承AbstractMap类。AbstractMap中包含了map的基本功能。
(1) 初始大小
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
从源码可以看出大小是16(1左移动4位1000 = 16)
static final int MAXIMUM_CAPACITY = 1 << 30;
最大长度是2的30次方1073741824 基本能满足绝大部分需求的使用。
static final float DEFAULT_LOAD_FACTOR = 0.75f;
默认的负载因子是0.75 ,默认的负载因子一般不需要改动。如果更加关注内存空间,而不怎么关注速度,可以调大负载因子,反之,如果更加关注HashMap读写速度,而不太关注内存空间,则可以调小负载因子。
从1.7之前的hashMap是用数组table+链表实现的,而在1.8jdk中队hashMap做了优化,通过数组,链表,红黑树(二叉树的一种)来实现,链表数组长度超过8时,转成红黑树从而提高了HashMap的效率。
(1)1.7中 hashMap的put方法详解:
public V put(K key, V value) { // 如果 key 为 null,调用 putForNullKey 方法进行处理 if (key == null) return putForNullKey(value); // 根据 key 的 keyCode 计算 Hash 值,hash函数为一个数学方法用位运算继续计算hash值 int hash = hash(key.hashCode()); // 查找hash值在table中的索引(此处的indexfor方式是一个数学方法, 返回值为 hash&table.length-1 ,通过位运算,保证此函数的返回值总是小于等于table.length,这样能确保i值在table数组的索引之内) int i = indexFor(hash, table.length); // 如果 i 索引处的 Entry 不为 null,通过循环不断遍历 e 元素的下一个元素 // table的i处存放的Entry中next值记录了链表情况,可能有多个Entry链,所以此时对链表循环处理 for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; // 1.找到key值的hash值与插入值的hash值相同的key,并且key的值要与插入的key值相同, // 2.两者同时满足才能判断插入的是同一个key( 不同key值的hash值可能相等(hash碰撞),所以此处要增加key值自身的判断) if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { //key值相同时直接替换value值,跳出函数 V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } // 如果 i 索引处的 Entry 为 null 或者key的hash值相同而key不同 ,则需要新增Entry modCount++; // 将 key、value 添加到 i 索引处 addEntry(hash, key, value, i); return null; }
下面通过viso图来简要描述流程
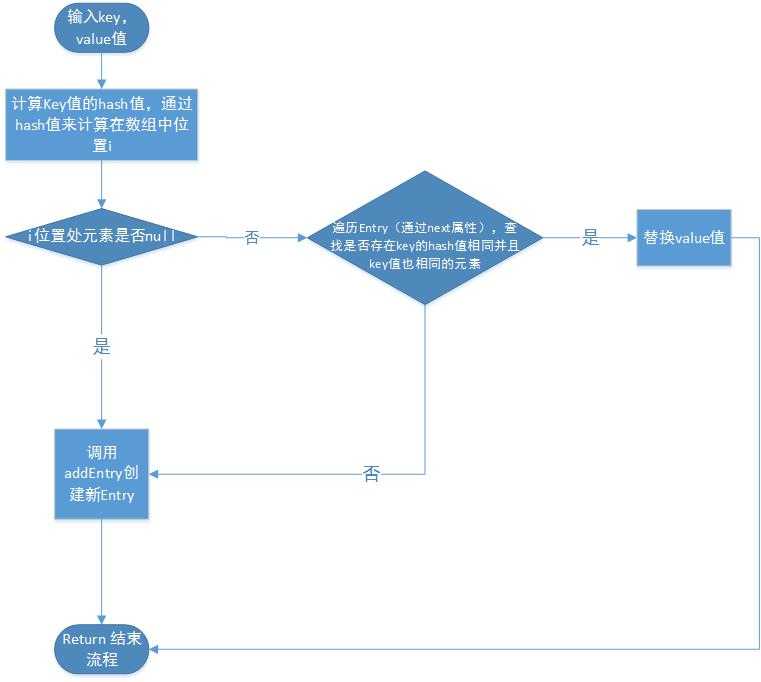
addEntry这个函数这里在简单的说一下,先上代码
//table数组节点中新增 Entry void addEntry(int hash, K key, V value, int bucketIndex) { // 获取指定 bucketIndex 索引处的 Entry Entry<K,V> e = table[bucketIndex]; // ① //将新创建的 Entry 放入 bucketIndex 索引处,并让新的 Entry 指向原来的 Entry //此处分为两种情况 //1.table中i出无元素,则 e的值为null,新插入的Entry的next为null,无链表 //2.table中i处存在元素,新插入的元素会覆盖数组中的位置,同时新创建的Entry中next指向老元素的,形成链表。 table[bucketIndex] = new Entry<K,V>(hash, key, value, e); // 如果 Map 中的 key-value 对的数量超过了极限 if (size++ >= threshold) // 把 table 对象的长度扩充到 2 倍。 resize(2 * table.length); // ② }
在table的指定位置添加Entry元素,如果已经有entry元素,用新增的Entry替代老元素,但在entry中的next记录原元素的位置,实现链表查询。
到这里基本上put方法的原理基本上就清晰明了,下面看一下get方法
public V get(Object key) { // 如果 key 是 null,调用 getForNullKey 取出对应的 value if (key == null) return getForNullKey(); // 根据该 key 的 hashCode 值计算它的 hash 码 int hash = hash(key.hashCode()); // 直接取出 table 数组中指定索引处的值, for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; // 搜索该 Entry 链的下一个 Entr e = e.next) // ① { Object k; // 如果该 Entry 的 key 与被搜索 key 相同 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) return e.value; } return null; }
先通过hash方法查到在数组中的位置,查找出entry并通过entry的next做遍历,查到key值对应的value
标签:table dex style equals shc 情况 效率 ext factor
原文地址:http://www.cnblogs.com/zhuangyan728/p/5986471.html