标签:抽取 模型 png 定义类 最大 简单 另一个 问题 题意
1.数据为1981-1993年全国人均消费额和人均国民收入的数据,试分析人均收入对人均消费额的影响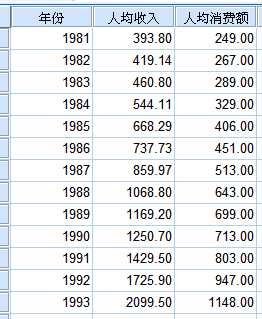
分析思路:
二者均为连续变量,回归分析可以定量的分析一个变量对另一个变量的影响,符合题意。同时还要考察一下数据是否符合回归分析的条件,虽然本题只是简单的两个变量
分析结果:
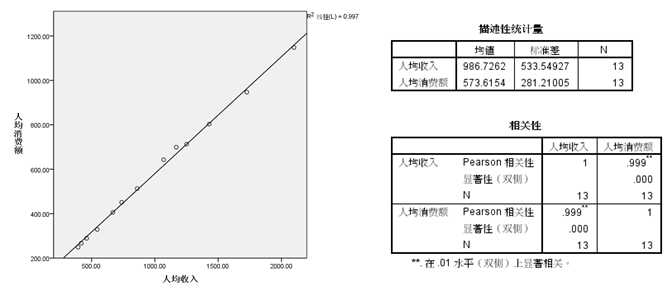
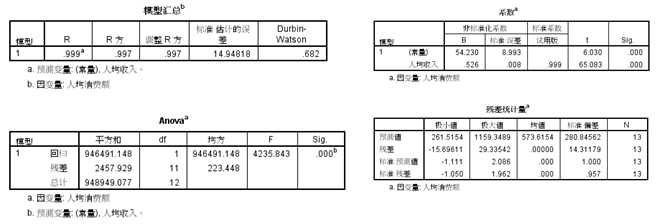
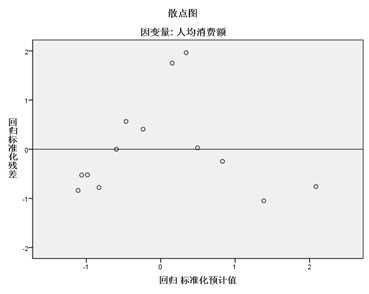
从散点图可以看出,两变量呈很强的线性相关关系,相关系数非常大,这符合常识,决定系数R方为0.997,说明模型效果很好,后续的模型整体检验,也说明该模型是有统计意义的,残差散点图可以显示残差分布较均匀,并没有明显趋势,最终得出的回归模型为:
人均消费额=54.23+0.526*人均收入,即人均收入每增加1元,人均消费增加0.526元
==========================================
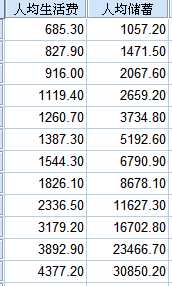
2.数据为1997年中国城镇居民家庭人均生活费X与城镇储蓄Y两个变量数据,试对人均生活费和人均储蓄两变量拟合最佳曲线模型
分析思路:
两变量均为连续变量,并且要求最佳拟合曲线模型,我们以往使用散点图判断两变量的大致关系只是一种粗略的判断,本题要求拟合最佳的曲线模型,因此需要选出一些可能的模型进行最后的筛选,筛选的标准就是决定系数越大,模型拟合效果越好。
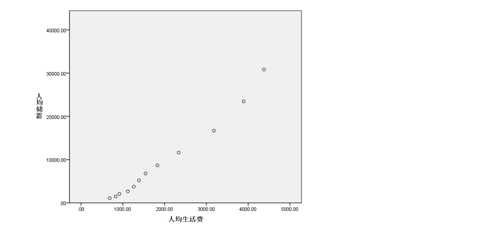
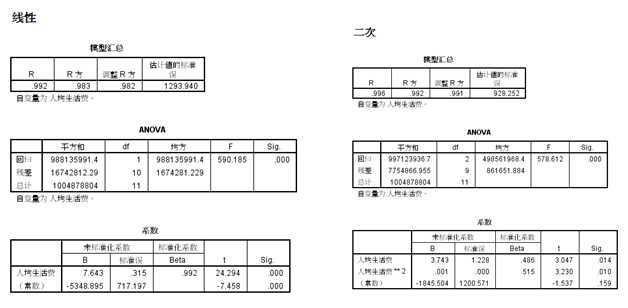
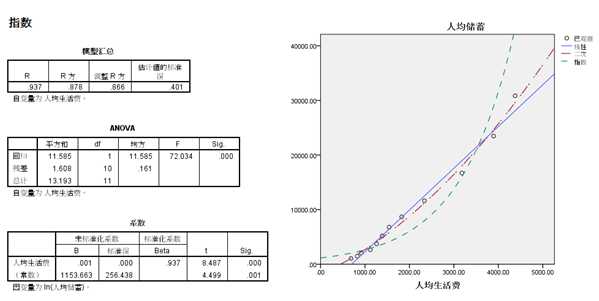
从两变量的散点图可以看出,二者大致呈直线关系,但是我们要求拟合最佳的曲线模型,因此我们在曲线回归过程中选择了线性、二次项、指数三个模型进行拟合,其中发现二次项的决定系数为0.991,三者最大,同时三种模型拟合的线图也显示,二次项模型和实测值的拟合度较好,因此我们最终拟合的模型为:
y=-1845.50+3.74x+0.001x2
==============================================
3.为研究全国消费支出规律,现抽取28个省、市、自治区生活消费支出中的6个相关指标,试做聚类分析。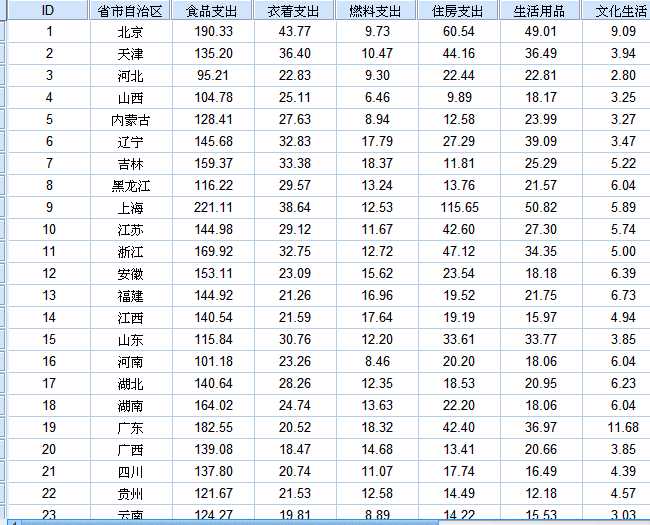
分析思路:本题要求做聚类分析,分析目的是根据消费支出的多少将城市分类,因此采用个案聚类。在此我们选择系统聚类法
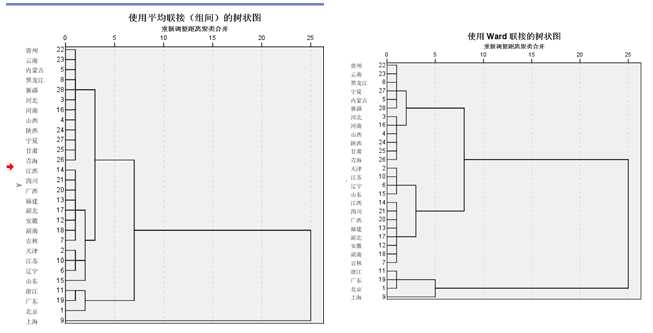
不同的聚类方法,得出的结论也会有所差异,在此我们采用组间连接和Ward法进行聚类,可以看出主要二者的区别主要在上海是单独作为一类还是和北京、广东共同为一类,此差别问题不大,因为三者都是经济文化中心。两种方法都将28个省市分为了3类,也可以自定义类别数。
标签:抽取 模型 png 定义类 最大 简单 另一个 问题 题意
原文地址:http://www.cnblogs.com/xmdata-analysis/p/5991087.html