标签:高性能 多个 创建 9.png 正则 文本框 span strong images
分组就是对文本加括号以帮助执行某种操作,比如:
选择操作
选择操作可在多个可选模式中匹配一个。例如,你想在"The rime of the Ancyent Mariner"中找出the出现过多少次,包括THE,The和the的形式。
若在RegExr上方文本框输入
(THE|The|the)
则看到所有the都被标亮。
可以使用选项来使分组更简短。例如:
(?i)
可以让模式不再区分大小写。所有上面带选择操作的模式可以写成
(?i)the
正则表达式中的选项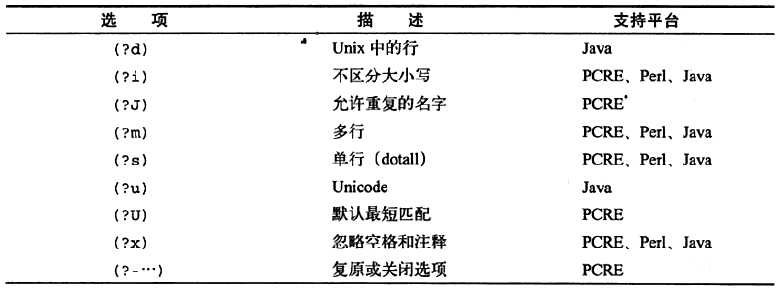
子模式
正则表达式中的子模式是指分组中的一个或多个分组。
例如:
(the|The|THE)
(t|T)h(e|eir)
括号对于子模式不是必须的。
\b[tT]h[ceinry]*\b
这个模式会匹配the或The还有thee,thy以及thence等单词。
捕获分组和后向引用
当一个模式的全部或者部分内容由一对括号分组时,它就对内容进行捕获并临时存储与内存中。可以通过后向引用重用捕获的内容。
\1
或者
$1
这里\1或$1引用的是第一个捕获的分组,而\2或$2引用的是第二个捕获的分组,以此类推。
命名分组
命名分组就是有名字的分组。
假如你要查找含有连续六个0的字符串:
000000
就可以用这个模式对连续三个0的分组命名:
(?<z>0{3})
然后你可以再使用该分组:
(?<z>0{3})\k<z>
或者
(?<z>0{3})\k‘z‘
或者
(?<z>0{3})\g{z}
命名分组的语法

非捕获分组
非捕获分组不会将内容存储在内存中。在你并不想引用分组的时候可以使用,因为没有存储内容,所以可以带来性能上的提升。
(the|The|THE)
这个分组不需要任何后向引用,所以可以写成非捕获分组:
(?:the|The|THE)
添加选项将其变为不区分大小写的模式:
(?i)(?:the)
也可以这样写:
(?:(?i)the)
最推荐的写法是这样的:
(?i:the)
原子分组
另一种非捕获分组是原子分组。
如果你使用的正则表达式引擎进行回溯操作,这种分组就可以将回溯操作关闭,但它只针对原子分组内的部分,而不针对整个正则表达式。
(?>the)
小结:
1.(THE|The|the),通过竖线|可以多个可选模式中匹配一个
2.括号()内的模式和字符组[]都可以看做一个分组
3.括号()内的分组会被捕获到内存中,使用\1或者$1后向引用
4.通过命名的分组可以用名字来后向引用
5.(?:the|The|THE)非捕获分组不会存在内存中,以提高性能
标签:高性能 多个 创建 9.png 正则 文本框 span strong images
原文地址:http://www.cnblogs.com/hahazexia/p/5994965.html
{kind=link}