标签:mode target and 图像处理 idt 筛子 性能 颜色 建立
卷积神经网络的理论基础看这篇:http://blog.csdn.net/stdcoutzyx/article/details/41596663/
卷积神经网络的tenserflow教程看这里:http://www.tensorfly.cn/tfdoc/tutorials/deep_cnn.html
卷积神经网络(convolutional neural networks,简称cnn)
CNN的基本结构包括两层,其一为特征提取层,每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征。一旦该局部特征被提取后,它与其它特征间的位置关系也随之确定下来;其二是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数(我们的实例中使用的死ralu函数),使得特征映射具有位移不变性。此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数。卷积神经网络中的每一个卷积层都紧跟着一个用来求局部平均与二次提取的计算层,这种特有的两次特征提取结构减小了特征分辨率。
在神经网络中,神经元都和前一层所有神经有连接,这样就使得神经网络各层之间连接的参数非常多。在卷积神经网络主要是通过下列两个方法减少参数:
1.局部感知视野
原理:人对外界的认知是从局部到全局的,而图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。
实现:如下图,我们将每个神经元只和10*10的像素相连,那么现在对应参数应该为10*10。我们将这个过程称做为卷积。
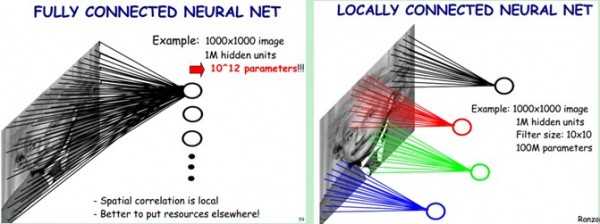
2.共享参数
共享参数也就是权值共享。
原理:图像的一部分的统计特性与其他部分是一样的。这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征。
我们可以将上面的100个参数看成是特征的提取方式,也可以看成是过滤器。也就是说我们用这个过滤器对一张大图片进行扫描工作。并获取特征,我们将这100个参数又叫做卷积核。、
如下图所示,展示了一个33的卷积核在55的图像上做卷积的过程。每个卷积都是一种特征提取方式,就像一个筛子,将图像中符合条件(激活值越大越符合条件)的部分筛选出来。
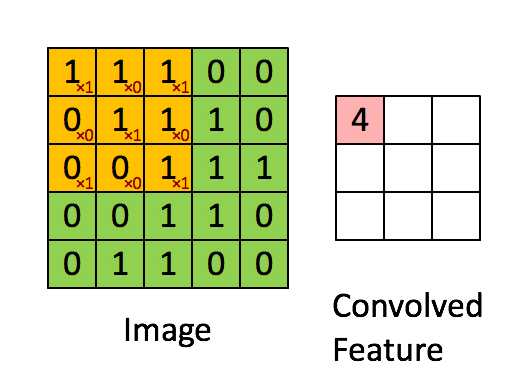
3.多核卷积
如上面所述,只有100个参数的时候,表名只有1个10*10的卷积核,显然特征提取是不从分的,我可以添加多个卷积核,比如可以添加32个卷积核,在多个卷积核时,如下图所示
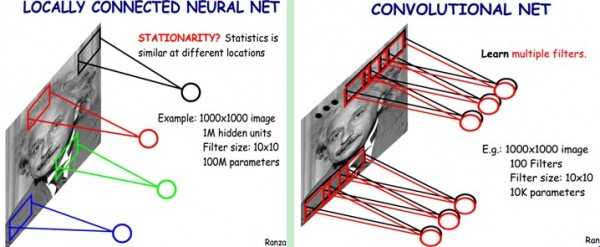
上图右,不同颜色表明不同的卷积核。每个卷积核都会将图像生成为另一幅图像。比如两个卷积核就可以将生成两幅图像,这两幅图像可以看做是一张图像的不同的通道。
下图展示了在四个通道上的卷积操作,有两个卷积核,生成两个通道。其中需要注意的是,四个通道上每个通道对应一个卷积核,先将w2忽略,只看w1,那么在w1的某位置(i,j)处的值,是由四个通道上(i,j)处的卷积结果相加然后再取激活函数值得到的。
这里还有一个公式!!!!!!!!!!!
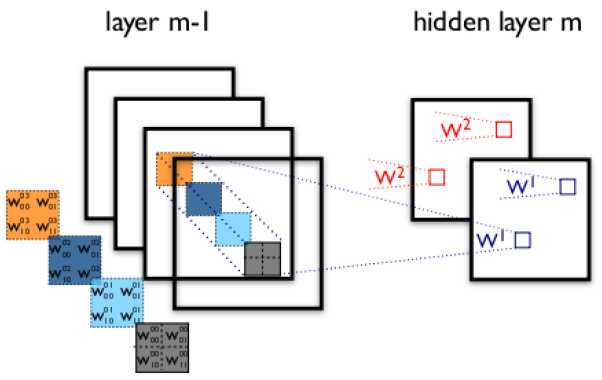
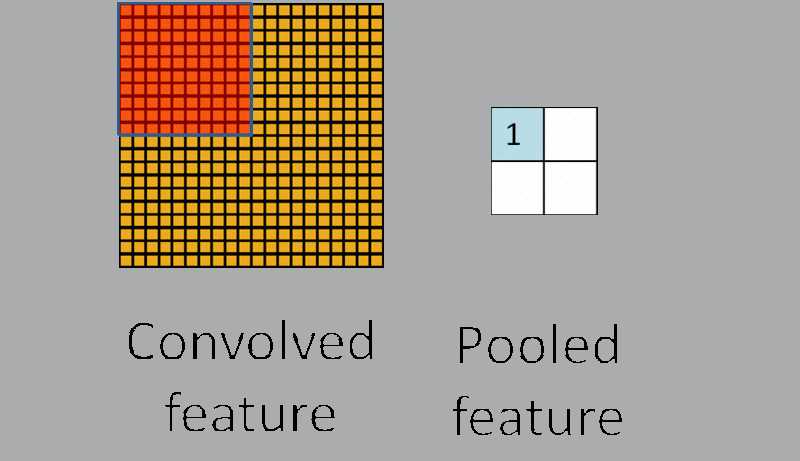
4.池化(Down-pooling)
原理:对不同位置的特征进行聚合统计
做法:计算图像的一个区域上的某个特定特征的平均值(或者最大值)。
在通过卷积获得了特征 (features) 之后,下一步我们希望利用这些特征去做分类。理论上讲,人们可以用所有提取得到的特征去训练分类器,例如 softmax 分类器,但这样做面临计算量的挑战。对于一个 96X96 像素的图像,假设我们已经学习得到了400个定义在8X8输入上的特征,每一个特征和图像卷积都会得到一个 (96 ? 8 + 1) × (96 ? 8 + 1) = 7921 维的卷积特征,由于有 400 个特征,所以每个样例 (example) 都会得到一个 7921 × 400 = 3,168,400 维的卷积特征向量。学习一个拥有超过 3 百万特征输入的分类器十分不便,并且容易出现过拟合 (over-fitting)。
为了解决这个问题,首先回忆一下,我们之所以决定使用卷积后的特征是因为图像具有一种“静态性”的属性,这也就意味着在一个图像区域有用的特征极有可能在另一个区域同样适用。因此,为了描述大的图像,一个很自然的想法就是对不同位置的特征进行聚合统计,例如,人们可以计算图像一个区域上的某个特定特征的平均值 (或最大值)。这些概要统计特征不仅具有低得多的维度 (相比使用所有提取得到的特征),同时还会改善结果(不容易过拟合)。这种聚合的操作就叫做池化 (pooling),有时也称为平均池化或者最大池化 (取决于计算池化的方法)。
原理到这就结束了,现在分析tenserflow里面卷积神经部分的代码:
运行方式:
源文件所在文件夹:tensorflow/models/image/cifar10/
| 文件 | 作用 |
|---|---|
cifar10_input.py |
读取本地CIFAR-10的二进制文件格式的内容。 |
cifar10.py |
建立CIFAR-10的模型。 |
cifar10_train.py |
在CPU或GPU上训练CIFAR-10的模型。 |
cifar10_multi_gpu_train.py |
在多GPU上训练CIFAR-10的模型。 |
cifar10_eval.py |
评估CIFAR-10模型的预测性能。 |
输入命令:python cifar10.train.py 对模型进行训练,训练大概需要四五个小时,训练结果会保存。
输入命令:python cifar10_eval.py 对训练结果进行评估
cifar-10模型
cifar-10神经网络的模型部分代码位于cifar10.py,主要包含以下模块:
1.数据输入:包含inputs() distorted_input()等函数,主要是下载数据,并读取数据,对数据进行预处理,方便后续评估和训练的输入;
2.模型预测:主要包含了inference函数,通过调用tenserflow已有的函数,构建cnn完整的模型;
3.模型训练:包括了loss() 和 train()函数,对模型进行训练,使其能够进行分类。
输入模型是通过 inputs() 和distorted_inputs()函数建立起来的,这2个函数会从CIFAR-10二进制文件中读取图片文件,由于每个图片的存储字节数是固定的,因此可以使用tf.FixedLengthRecordReader函数。更多的关于Reader类的功能可以查看Reading Data。
图片文件的处理流程如下:
对于训练,我们另外采取了一系列随机变换的方法来人为的增加数据集的大小:
函数可以查看下面的链接。
模型的预测流程由inference()构造,该函数会添加必要的操作步骤用于计算预测值的 logits,其对应的模型组织方式如下所示:
上图模型的基本参数为:
tensorflow中图像处理的相关函数:http://www.tensorfly.cn/tfdoc/api_docs/python/image.html
tenserflow中神经网络相关的函数: http://www.tensorfly.cn/tfdoc/api_docs/python/nn.html
参考:
http://ibillxia.github.io/blog/2013/04/06/Convolutional-Neural-Networks/
http://stackoverflow.com/questions/34619177/what-does-tf-nn-conv2d-do-in-tensorflow
http://www.cnblogs.com/hellocwh/p/5564568.html 实验实现
标签:mode target and 图像处理 idt 筛子 性能 颜色 建立
原文地址:http://www.cnblogs.com/yuqt/p/5994530.html