标签:text enter 属性 数值 数据集 机器 范围 算法 支持
本文主要介绍:统计学基本概念、数据的收集、数据的描述、回归和分类、多元分析,其中回归和分类、多元分析是学习重点。统计学中的其它概念如:概率及分布、参数估计、假设检验属于经典统计的内容,在此文略去,时间序列分析及指数是金融方面的应用,也一并略去,如有需要请查阅相关书籍。
参考书籍:
贾俊平.《统计学》.第六版
王喜之.《统计学:从数据到结论》.第四版
统计学:收集、处理、分析、解释数据并从中得出结论的科学。
数据分析的方法可分为描述统计和推断统计。
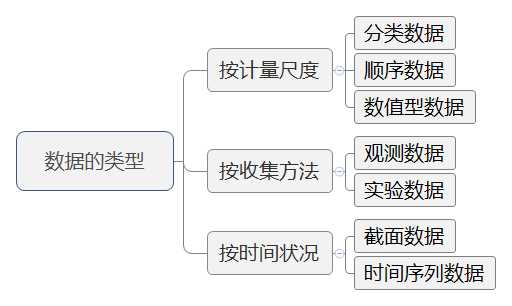
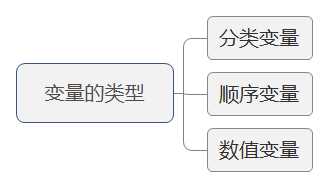
注意:分类变量如“行业”,其变量值可以为“零售业”、“旅游业”、“汽车制造业”;顺序变量如“产品等级”,其变量值可以位“一等品”、“二等品”、“次品”。分类变量与顺序变量均可称为定性变量、属性变量。
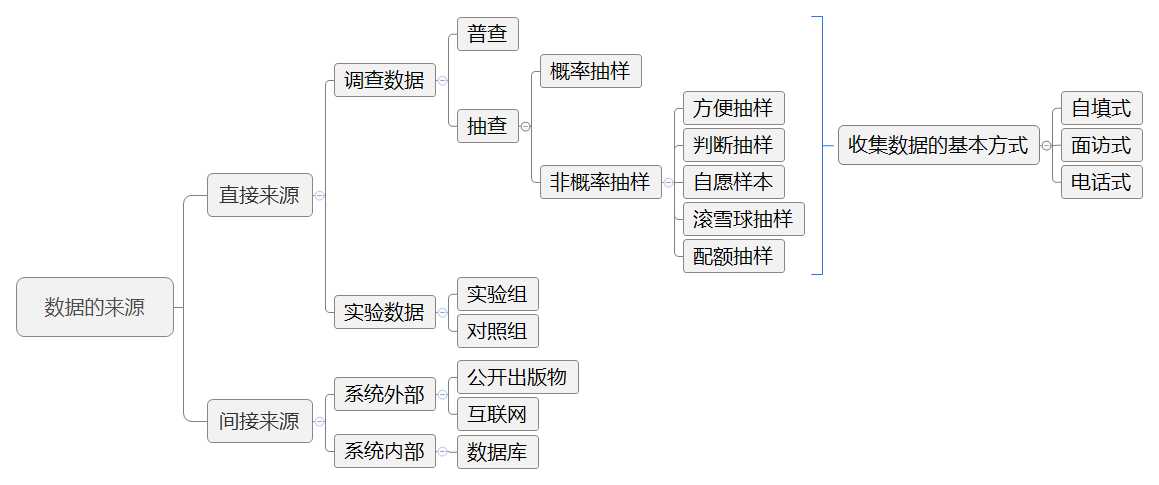
注意: 在抽查中可根据具体项目采取概率抽样和非概率抽样相结合的方式,收集数据也可以采用自填、电访、面访相结合的方式以节省成本。 在间接来源中,注意对二手数据评估,可以考虑:数据是谁收集的?为什么目的收集的?数据怎么收集的?什么时候收集的?避免对二手数据的错用、误用、滥用。

注意:在excel 数据---“数据分析---描述统计 中能得到所有指标值。
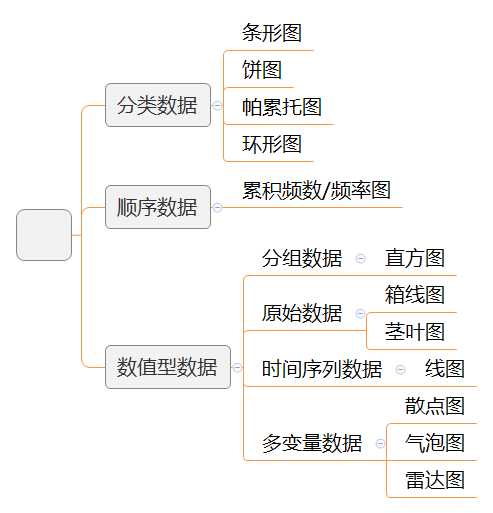
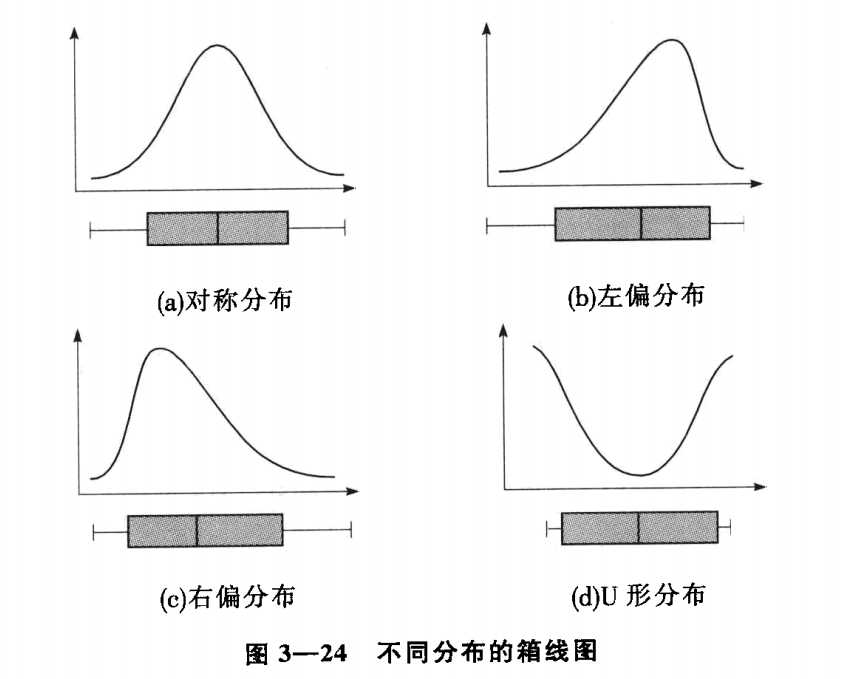
说明:不同的箱线图对应的分布如下
| 拟合优度指标 | 检验方法 | 是否需要假设分布背景 | 准确度排名 | |
| 线性回归 | 判定系数 R2 | F统计量、t统计量 | 是 | 4 |
| 决策树 | 判定系数 R2 | 交叉验证 | 否 | 5 |
| boosting | 判定系数 R2 | 交叉验证 | 否 | 2 |
| 随机森林 | 判定系数 R2 | 交叉验证 | 否 | 1 |
| 支持向量机 | 判定系数 R2 | 交叉验证 | 否 | 3 |
线性回归属于经典统计学,模型能够写成公式,而其它几种方式属于现代方法,模型体现在算法之中,这些方法广泛应用于机器学习或数据挖掘之中。算法模型适用范围比经典的统计模型根据广泛。在处理巨大的数据集上,在无法假定任何分布背景的情况下,在面对众多竞争模型,算法模型较经典模型有着不可比拟的优越性。
| 拟合优度指标 | 检验方法 | 是否需要假设分布背景 | 准确度排名 | |
| Logistic回归 | 是 | 因变量只能为2个变量 | ||
| 线性判别分析(Fisher判别法) | 错分比例 | 交叉验证 | 否 | 4 |
| 决策树 | 错分比例 | 交叉验证 | 否 | 5 |
| boosting | 错分比例 | 交叉验证 | 否 | 3 |
| 随机森林 | 错分比例 | 交叉验证 | 否 | 1 |
| 支持向量机 | 错分比例 | 交叉验证 | 否 | 2 |
说明:Logistic回归、线性判别分析(Fisher判别法)均属于经典统计的内容。支持向量机是基于数学模型但充分结合了计算机的算法。
| 拟合优度指标 | 检验方法 | 是否需要假设分布背景 | 准确度排名 | |
| 决策树 | 错分比例 | 交叉验证 | 否 | 2 |
| boosting | 错分比例 | 交叉验证 | 否 | 1 |
| 随机森林 | 错分比例 | 交叉验证 | 否 | 1 |
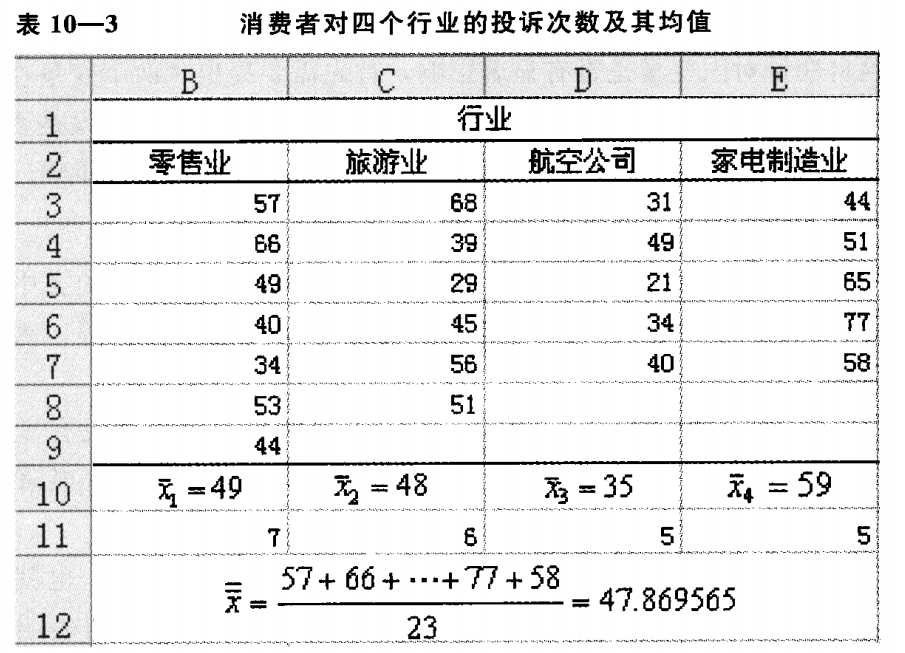
列联表是若干分类变量的各种可能取值组合的出现频数分布表,主要目的是看这些变量是否想关。如:

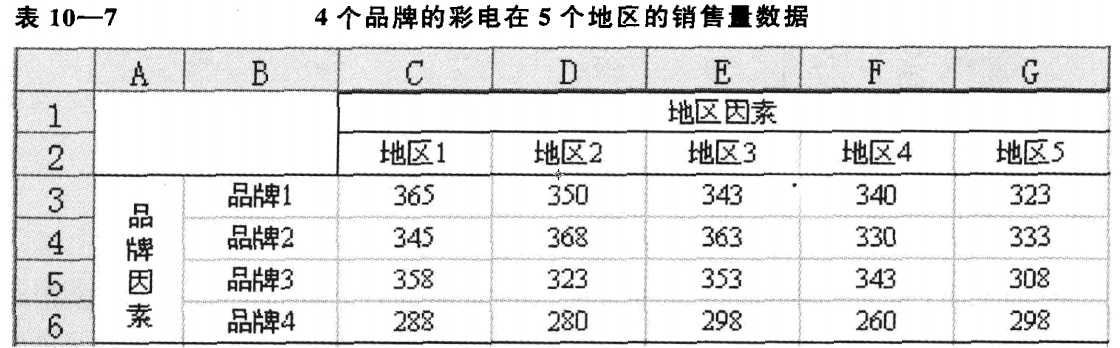
方差分析是通过对数据误差来源的分析来判断不同总体的均值是否相等,进而分析自变量(分类型)对因变量(数值型)是否有显著影响。可分为单因素方差分析,双因素方差分析。如:
5.1寻找多个变量的代表:主成分分析和因子分析
5.2把对象分类:聚类分析
详见《多元统计分析》、《实用多元统计分析》
标签:text enter 属性 数值 数据集 机器 范围 算法 支持
原文地址:http://www.cnblogs.com/xiaofeng1234/p/5987845.html