标签:nbsp ring 分享 ges measure ons ror tee work
For each training pattern presented to a multilayer neural network, we can computer the error:
yd(p)-y(p)
Sum-Squared Error squaring and summing across all n patterns, SSE give a good measure of the overall performance of the network.
SSE depends on weight and threshholds.
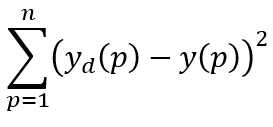
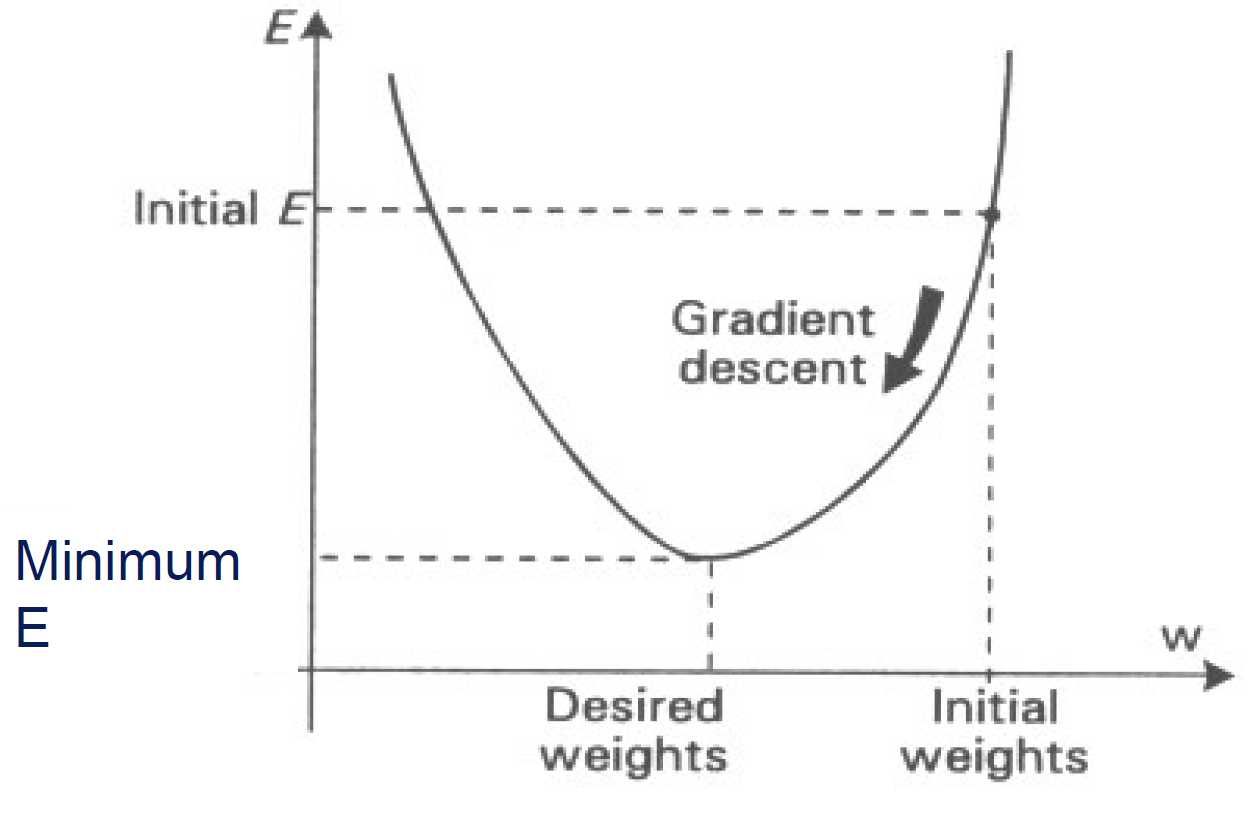
Back-propagation is a "gradient descent" training algorithm
![]()
Step:
1. Calculate error for a single patternm
2. Compute weight changes that will make the greatest change in error with error gradient(steepest slope)
only possible with differentiable activation functions(e.g. sigmoid)
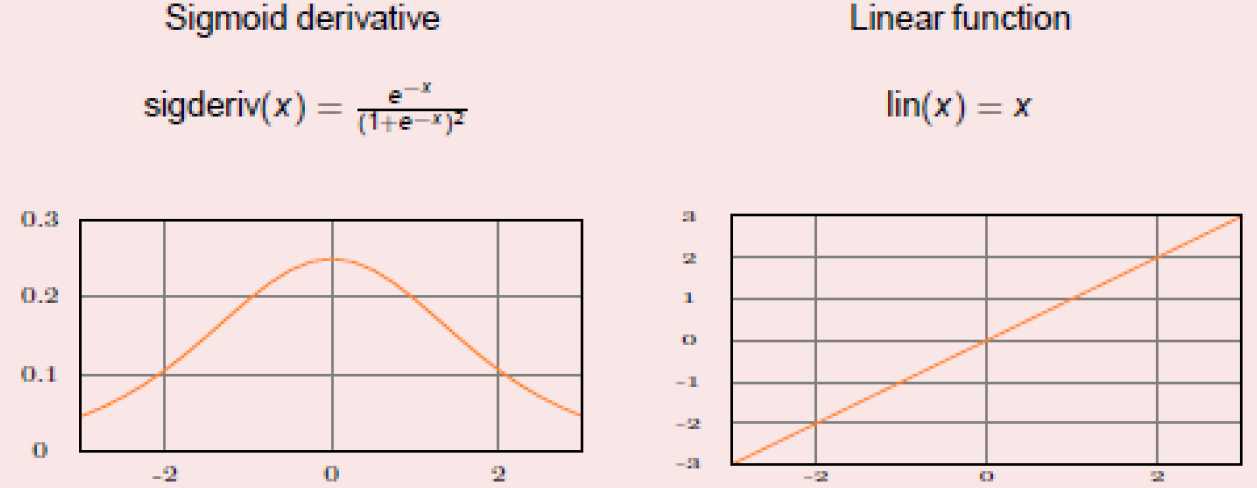
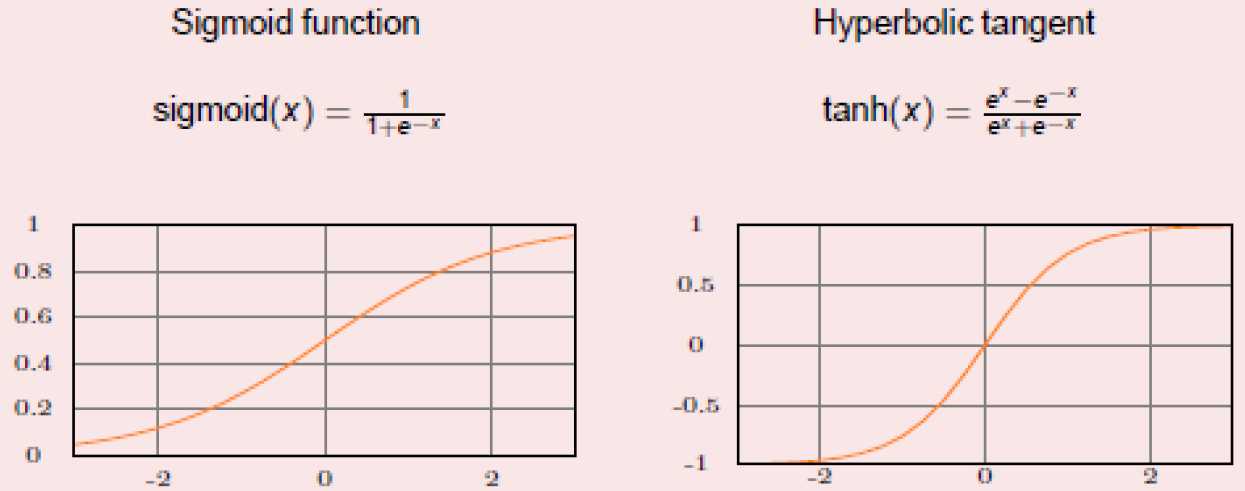
gradient descent only approximate training proceeds pattern-by pattern.
gradient descent may not always reach true global error minimum, otherwise it may get stuck in "local" minimum.
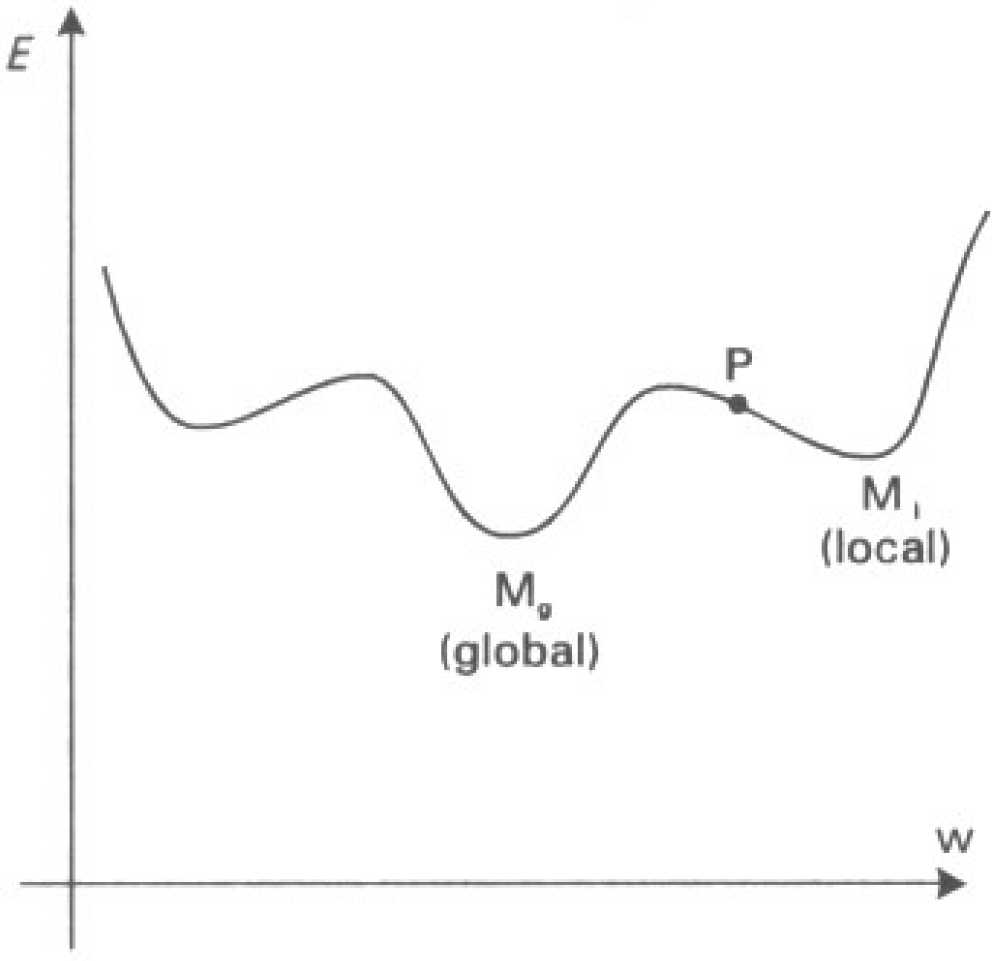
solution: momentum term
![]()
BP, Gradient descent and Generalisation
标签:nbsp ring 分享 ges measure ons ror tee work
原文地址:http://www.cnblogs.com/eli-ayase/p/5906175.html