标签:style blog class code java tar
总算到了第5章—高级数据管理了啊
作为这本书第一部分—入门的收官之章,本章还是挺重要的呢
这章可以分为三个部分,第一部分:快速浏览R 中的多种数学、统计和字符处理函数,第二部分:如何编写函数来完成数据处理和分析任务,第三部分:了解数据的整合和概数方法,以及数据集的重塑和重构方法

> 学生姓名 <- c("John Davis", "Angela Williams", "Bullwinkle Moose", "David Jones", "Janice Markhammer", "Cheryl Cushing", "Reuven Ytzrhak", "Greg Knox", "Joel England", "Mary Rayburn") > 数学 <- c(502,600,412,358,495,512,410,625,573,522) > 科学 <- c(95,99,80,82,75,85,80,95,89,86) > 英语 <- c(25,22,18,15,20,28,15,30,27,18) > 学生成绩数据 <- data.frame(学生姓名, 数学, 科学, 英语) > 学生成绩数据 学生姓名 数学 科学 英语 1 John Davis 502 95 25 2 Angela Williams 600 99 22 3 Bullwinkle Moose 412 80 18 4 David Jones 358 82 15 5 Janice Markhammer 495 75 20 6 Cheryl Cushing 512 85 28 7 Reuven Ytzrhak 410 80 15 8 Greg Knox 625 95 30 9 Joel England 573 89 27 10 Mary Rayburn 522 86 18
利用这段代码创建了一个数据集,要求是对学生进行成绩等级评定,为了给所有学生确定一个单一的成绩量指标,需要将这些科目的成绩组合起来;另外,还想将前20%的学生评定为A,前40%为B,以此类推
但是问题出现了:首先,三科考试的成绩是无法比较的,由于它们的均值和标准差相去甚远,所以对它们求平均值是无意义的;其次,未来评定等级,还需要一种方法来确定某个学生在上述得分上百分比排名;此外,表示姓名的字段只有一个,这让排序任务复杂化了,为了正确地将其排序,需要将姓和名拆开
数值和字符处理函数
在R 中存在着一大批数据处理的函数,可分为数值(数学、统计、概率)和字符处理函数
数学函数
abs( )
sqrt( )
ceiling( ), 不小于x的最小整数
floor( ), 不大于x的最大整数
trunc(x), 向0的方向截取的x中的整数部分
round(x, digits=n), 将x舍入为指定的小数
signif(x, digits=n), 将x舍入为指定的有效数字位数
cos(x), sin(x), tan(x)
acos(x), asin(x), atan(x)
cosh(x), sinh(x), tanh(x), 双曲余弦、双曲正弦、双曲正切,(双曲函数在工程函数中常用到)
acosh(x), asinh(x), atanh(x), 反双曲余弦、反双曲正弦、反双曲正切
log(x, base=n)
log(x)
log10(x)
exp(x)
统计函数
mean(x)
median(x), 中位数
sd(x), 标准差
var(x)
mad(x), 绝对中位差(即二分之一的四分位差)
quantile(x, probs), 求分位数
range(x), 求值域
sum(x)
diff(x, lag=n), 滞后差分(就是依次后面-前面)
min(x)
max(x)
scale(x, center=TRUE, scale=TRUE), 为数据对象x按列进行中心化(cente=TRUE)或标准化(center=TRUE, scale=TRUE)
此外,在默认情况下,scale( )函数对矩阵或数据框的指定列进行均值为0,标准差为1的标准化,如需修改:newdata <- scale(mydata)*SD + M
接下来是概率函数
在R 中概率函数因为其特殊性从统计函数里单独来讲,形式如下:
[dpqr]distribution_abbreviation( )
其中,d = 密度函数density
p = 分布函数distribution function
q = 分位数函数quantile function
r = 生成随机数(随机偏差)
常用分布如下:(缩写,分布名称)
beta, Beta分布
binom, 二项分布
cauchy, 柯西分布
chisq, (非中心)卡方分布
exp, 指数分布
f, F分布
gamma, Gamma分布
geom, 几何分布
hyper, 超几何分布
lnorm, 对数正态分布
logis, Logistic分布
multinom, 多项分布
nbinom, 负二项分布
norm, 正态分布
pois, 泊松分布
signrank, Wilcoxon符号秩分布
t, t分布
unif, 均匀分布
weibull, Weibull分布
Wilcox, Wilcoxon秩和分布
然后以正态函数为例:
> x <- pretty(c(-3,3),30) > y <- dnorm(x) > plot(x,y,type="l",xlab="NormalDeviate",ylab="Density",yaxs="i") > pnorm(1.96) [1] 0.9750021 > qnorm(.9,mean=500,sd=100) [1] 628.1552 > rnorm(50,mean=50,sd=10) [1] 57.77309 57.92006 49.19227 59.06174 55.04387 49.31641 49.84629 57.96677 [9] 50.21337 50.22981 50.37167 56.10702 56.56807 63.24012 45.13379 40.71906 [17] 44.73569 65.11037 42.11258 35.81041 56.78520 56.60466 58.06007 53.44807 [25] 56.51045 34.15292 32.25604 68.58253 63.59537 56.97910 36.56898 36.50259 [33] 43.63777 52.73502 47.61792 30.66723 44.95935 40.41800 48.84267 61.01907 [41] 63.17504 46.18625 64.83684 50.39462 59.45504 43.47186 32.71913 58.17246 [49] 35.04387 60.33170
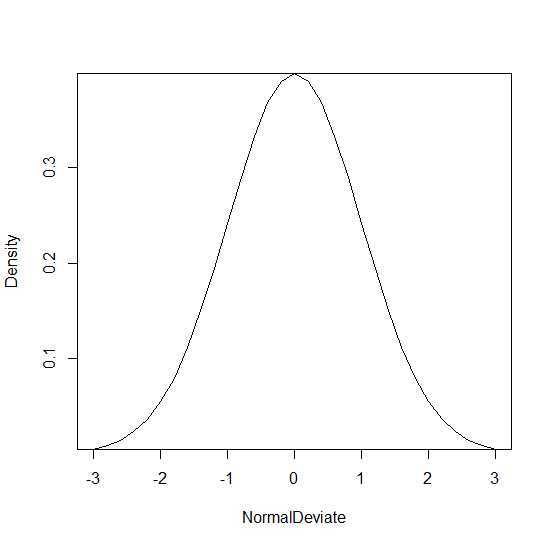
在这里用到了密度函数dnorm( ), 分布函数pnorm( ), 分位数函数qnorm( ), 随机数生成函数rnorm( )
再下面是设定随机数种子
在每次生成伪随机数的时候,函数都会使用一个不同的种子,因此也会产生不同的结果,可以通过函数set.seed( )显示指定这个种子,让结果可以重现(reproducible),在这里用runif( )函数来生成0到1区间上服从均匀分布的伪随机数
> runif(5) [1] 0.15476319 0.87902409 0.03751162 0.46050912 0.80083666 > runif(5) [1] 0.5415807 0.1542395 0.2040502 0.5139353 0.1317150 > set.seed(1234) > runif(5) [1] 0.1137034 0.6222994 0.6092747 0.6233794 0.8609154 > set.seed(1234) > runif(5) [1] 0.1137034 0.6222994 0.6092747 0.6233794 0.8609154
再下面是生成多元正态数据
在模拟研究和蒙特卡罗方法中,经常需要获取来自给定均值向量和协方差阵的多元正态分布的数据。MASS包中的mvrnorm( )函数可以让这个问题变得很容易,其调用格式为:
mvrnorm(n, mean, sigma), 其中n为样本大小,mean为均值向量,sigma为方差-协方差矩阵或相关矩阵
> install.packages("MASS") > library(MASS) > options(digits=3) > set.seed(1234) > mean <- c(230.7, 146.7, 3.6) > sigma <- matrix(c(15360.8, 6721.2, -47.1, 6721.2, 4700.9, -16.5, -47.1, -16.5, 0.3), nrow=3, ncol=3) > mydata <- mvrnorm(500, mean, sigma) > mydata <- as.data.frame(mydata) > names(mydata) <- c("y", "x1", "x2") > dim(mydata) [1] 500 3 > head(mydata, n=10) y x1 x2 1 98.8 41.3 3.43 2 244.5 205.2 3.80 3 375.7 186.7 2.51 4 -59.2 11.2 4.71 5 313.0 111.0 3.45 6 288.8 185.1 2.72 7 134.8 165.0 4.39 8 171.7 97.4 3.64 9 167.2 101.0 3.50 10 121.1 94.5 4.10
其中options(digest=3)指把R 的整数能力设为3位
再下面是字符处理函数了啊
常见的如下啊:
nchar(x), 计算x中的字符数量
substr(x, start, stop), 提取或替换一个字符向量中的子串
grep(pattern, x, ignore, case=FALSE, fixed=FALSE), 在x中搜索某种模式,若fixed=FALSE,则pattern为一个正则表达式;若fixed=TRUE, 则pattern为一个文本字符串,返回值为匹配的下标
sub(pattern, replacement, x, ignore.case=FALSE, fixed=FALSE), 在x中搜索pattern,并以文本replacement将其替换,若fixed=FALSE,则pattern为一个正则表达式;若fixed=TRUE,则pattern为一个文本字符串
strsplit(x, split, fixed=FALSE), 在split处分割字符向量x中的元素,若fixed=FALSE,则pattern为一个正则表达式;若fixed=TRUE,则pattern为一个文本字符串
paste(..., sep=""), 连接字符串,分隔符为sep
toupper(x), 大写转换
tolower(x), 小写转换
其中,正则表达式由于难度比较大,以后有空再学一学把
再下面是其它实用函数的介绍
length(x)
seq(from, to, by), 生成一个序列
rep(x, n), 将x重复n次
cut(x, n), 将连续型变量x分割为有着n个水平的因子
pretty(x, n), 创建美观的分割点,绘图中常用
cat(..., file="myfile", append=FALSE), 连接...中的对象,并将其输出到屏幕上或文件中(如果声明了一个的话)
此外,输出时的转义符如下:
\n表示新行,\t为制表符,\‘为单引号,\b为退格,等等,键入?Quotes可以了解更多
再下面是将函数应用于矩阵和数据框
> a <- 5 > sqrt(a) [1] 2.24 > b <- c(1.243, 5.654, 2.99) > round(b) [1] 1 6 3 > c <- matrix(runif(12), nrow=3) > c [,1] [,2] [,3] [,4] [1,] 0.353 0.350 0.299 0.287 [2,] 0.931 0.104 0.932 0.354 [3,] 0.677 0.357 0.289 0.881 > log(c) [,1] [,2] [,3] [,4] [1,] -1.040 -1.05 -1.2075 -1.249 [2,] -0.071 -2.27 -0.0706 -1.038 [3,] -0.391 -1.03 -1.2419 -0.126 > mean(c) [1] 0.485
此外,在R 中提供了一个apply( )函数,可以将一个任意函数“应用”到矩阵、数组、数据框的任何维度上,apply( )函数的使用格式为:apply(x, MARGIN, FUN, ...)
其中x为数据对象,MARGIN为维度的下标,FUN为指定的函数,而...则包括了任何想传递给FUN的参数,在矩阵或数据框中,MARGIN=1表示行,MARGIN=2表示列
> mydata <- matrix(rnorm(30), nrow=6) > mydata [,1] [,2] [,3] [,4] [,5] [1,] -0.604 0.935 0.609 -1.944 -0.8657 [2,] 1.203 1.234 0.591 -0.281 -0.0599 [3,] 0.769 -1.891 -0.435 0.812 0.0115 [4,] 0.238 -0.223 -0.251 -0.208 0.2691 [5,] -1.415 0.768 -0.926 1.451 -0.5282 [6,] 2.934 0.388 1.087 0.841 -0.6171 > apply(mydata, 1, mean) [1] -0.3740 0.5374 -0.1468 -0.0347 -0.1301 0.9267 > apply(mydata, 2 ,mean) [1] 0.521 0.202 0.112 0.112 -0.298 > apply(mydata, 2, mean, trim=0.2) [1] 0.401 0.467 0.128 0.291 -0.298
与apply( )函数类似的是,lapply( )和sapply( )函数则可以将函数应用到列表上
好了,现在就来小试一下牛刀把
数据处理难题的一套解决方案
这章最开始的要求是利用一段代码创建了一个数据集,要求是对学生进行成绩等级评定,为了给所有学生确定一个单一的成绩量指标,需要将这些科目的成绩组合起来;另外,还想将前20%的学生评定为A,前40%为B,以此类推
但是问题出现了:首先,三科考试的成绩是无法比较的,由于它们的均值和标准差相去甚远,所以对它们求平均值是无意义的;其次,未来评定等级,还需要一种方法来确定某个学生在上述得分上百分比排名;此外,表示姓名的字段只有一个,这让排序任务复杂化了,为了正确地将其排序,需要将姓和名拆开
现在可以用这么一种解决方案
> options(digits=2) > Student <- c("John Davis", "Angela Williams", "Bullwinkle Moose", "David Jones", "Janice Markhammer", "Cheryl Cushing", "Reuven Ytzrhak", "Greg Knox", "Joel England", "Mary Rayburn") > Math <- c(502, 600, 412, 358, 495, 512, 410, 625, 573, 522) > Science <- c(95, 99, 80, 82, 75, 85, 80, 95, 89, 86) > English <- c(25, 22, 18, 15, 20, 28, 15, 30, 27, 18) > roster <- data.frame(Student, Math, Science, English, stringsAsFactors=FALSE) > z <- scale(roster[,2:4]) > score <- apply(z, 1, mean) > roster <- cbind(roster, score) > y <- quantile(score, c(.8, .6, .4, .2)) > roster$grade[score >= y[1]] <- "A" > roster$grade[score < y[1] & score >= y[2]] <- "B" > roster$grade[score < y[2] & score >= y[3]] <- "C" > roster$grade[score < y[3] & score >= y[4]] <- "D" > roster$grade[score < y[4]] <- "F" > name <- strsplit((roster$Student), " ") > lastname <- sapply(name, "[", 2) > firstname <- sapply(name, "[", 1) > roster <- cbind(firstname, lastname, roster[,-1]) > roster <- roster[order(lastname,firstname),] > roster firstname lastname Math Science English score grade 6 Cheryl Cushing 512 85 28 0.35 C 1 John Davis 502 95 25 0.56 B 9 Joel England 573 89 27 0.70 B 4 David Jones 358 82 15 -1.16 F 8 Greg Knox 625 95 30 1.34 A 5 Janice Markhammer 495 75 20 -0.63 D 3 Bullwinkle Moose 412 80 18 -0.86 D 10 Mary Rayburn 522 86 18 -0.18 C 2 Angela Williams 600 99 22 0.92 A 7 Reuven Ytzrhak 410 80 15 -1.05 F
其中,scale( )函数是用来将变量标准化,以标准差来表示的函数;默认情况下是将一组数的每个数都减去这组数的平均值后再除以这组数的均方根;其中有两个参数,center=TRUE,默认的,是将一组数中每个数减去平均值,若为false,则不减平均值
quantile( )函数是计算百分数的函数
strsplit( )函数是分隔字符串的函数
sapply( )函数是lapply( )函数的升级版,格式为:sapply(X, FUN, ..., simplify = TRUE, USE.NAMES = TRUE);“["(包括引号的)则是一个可以提取某个对象的一部分的函数(其实这个函数不懂!)
然后到了控制流了啊
正常情况下,R 语言是程序语句是从上至下顺序执行的,但有时候需要一点例外
R 拥有一般现代编程语言中都有的标准控制结构,然后请牢记一下概念:语句statement,条件cond,表达式expr,序列seq(是一个数值或字符串序列)
首先是重复和循环
for结构:for (var in seq) statement
while结构:while (cond) statement
在处理大数据集中的行和列时,R 中的循环可能比较低效费时,只要可能,最好联用R 中的内建数值/字符处理和apply族函数
再是条件执行
if-else结构:if (cond) statement
if (cond) statement1 else statement2
ifelse结构
ifelse(cond, statement1, statement2)
switch结构
switch(expr, ...)
> feelings <- c("sad", "afraid") > for (i in feelings) + print( + switch(i, + happy = "I am glad you are happy", + afraid = "There is nothing to fear", + sad = "Cheer up", + angry = "Calm down now") + ) [1] "Cheer up" [1] "There is nothing to fear"
当然R 也支持用户自编函数
一个函数的结构大致如此:
myfunction <- function(arg1, arg2, ...){
statements
return(object)
}
函数中的对象只在函数内部使用,返回对象的数据类型是任意的,从标量到列表皆可。来看个例子把
> mystats <- function(x, parametric=TRUE, print=FALSE){ + if (parametric){ + center <- mean(x); spread <- sd(x) + } else { + center <- median(x); spread <- mad(x) + } + if (print & parametric){ + cat("Mean=", center, "\n", "SD=", spread, "\n") + } else if (print & !parametric){ + cat("Median=", center, "\n", "MAD=", spread, "\n") + result <- list(center=center, spread=spread) + return(result) + }
当然我觉得我应该不会自己编函数,所以就水水地就过了啊,以后再结合更多例子好好学啊
最后是整合和重构
在整合数据时,往往将多组观测替换为根据这些观测值计算的描述性统计量;在重塑数据时,则会通过修改数据的结构(行和列)来决定数据的组织方式
转置,使用t( )函数即可对一个矩阵或数据库进行转置
> cars <- mtcars[1:5, 1:4] > cars mpg cyl disp hp Mazda RX4 21.0 6 160 110 Mazda RX4 Wag 21.0 6 160 110 Datsun 710 22.8 4 108 93 Hornet 4 Drive 21.4 6 258 110 Hornet Sportabout 18.7 8 360 175 > t(cars) Mazda RX4 Mazda RX4 Wag Datsun 710 Hornet 4 Drive Hornet Sportabout mpg 21 21 22.8 21.4 18.7 cyl 6 6 4.0 6.0 8.0 disp 160 160 108.0 258.0 360.0 hp 110 110 93.0 110.0 175.0
整合数据
在R 红使用一个或多个by变量和一个预先定义好的函数来折叠数据是比较容易的,调用格式为:aggregate(x, by, FUN)
其中x是待折叠的数据对象,by是一个变量名组成的列表,这些变量将被去掉以形成新的观测,而FUN则是计算描述性统计量的标量函数,它将被用来计算新观测中的值
> options(digits=3) > attach(mtcars) 下列对象被屏蔽了from package:ggplot2: mpg > aggdata <- aggregate(mtcars, by=list(cyl,gear), FUN=mean, na.rm=TRUE) > aggdata Group.1 Group.2 mpg cyl disp hp drat wt qsec vs am gear carb 1 4 3 21.5 4 120 97 3.70 2.46 20.0 1.0 0.00 3 1.00 2 6 3 19.8 6 242 108 2.92 3.34 19.8 1.0 0.00 3 1.00 3 8 3 15.1 8 358 194 3.12 4.10 17.1 0.0 0.00 3 3.08 4 4 4 26.9 4 103 76 4.11 2.38 19.6 1.0 0.75 4 1.50 5 6 4 19.8 6 164 116 3.91 3.09 17.7 0.5 0.50 4 4.00 6 4 5 28.2 4 108 102 4.10 1.83 16.8 0.5 1.00 5 2.00 7 6 5 19.7 6 145 175 3.62 2.77 15.5 0.0 1.00 5 6.00 8 8 5 15.4 8 326 300 3.88 3.37 14.6 0.0 1.00 5 6.00
但是这些和reshape包相比,不算什么
reshape包是一套重构和整合数据集的绝妙的万能工具
大致来说,首先将数据融合melt,以使每一行都是一个唯一的标识符-变量组合,然后将数据”重铸“cast为想要的任何形状,在重铸中可以使用任何函数对数据进行整合
> ID <- c(1,1,2,2) > Time <- c(1,2,1,2) > X1 <- c(5,3,6,2) > X2 <0 c(6,5,1,4) 错误: 意外的符号 in "X2 <0 c" > X2 <- c(6,5,1,4) > mydata <- data.frame(ID, Time, X1, X2) > mydta 错误: 找不到对象‘mydta‘ > mydata ID Time X1 X2 1 1 1 5 6 2 1 2 3 5 3 2 1 6 1 4 2 2 2 4
融合
数据集的融合是将它重构为这样一种格式:每个测量变量独占一行,行中带有要唯一确定这个测量所需的标识符变量
> library(reshape)
载入程辑包:‘reshape’
下列对象被屏蔽了from ‘package:plyr’:
rename, round_any
下列对象被屏蔽了from ‘package:reshape2’:
colsplit, melt, recast
> md <- melt(mydata, id=(c("ID","Time")))
> md
ID Time
variable value
1 1 1 X1 5
2 1 2 X1 3
3 2
1 X1 6
4 2 2 X1 2
5 1 1 X2 6
6
1 2 X2 5
7 2 1 X2 1
8 2 2 X2
4
重铸
cast( )函数读取已融合的数据,并使用提供的公式和一个用于整合数据的函数将其重塑,调用格式为:newdata <- cast(md, formula, FUN)
其中,md是已融合的数据,formula描述了想要的最后结构,而FUN(可选的)数据整合函数,其接受的公式形如:rowvar1 + rowvar2 + ... ~ colvar1 + colvar2 + ...
在这一公式中,rowvar1 + rowvar2 + ...定义了要划掉的变量集合,以确定各行的内容,colvar1 + colvar2 + ...则定义了要划掉的、确定各列内容的变量集合
> cast(md,ID~variable+Time) ID X1_1 X1_2 X2_1 X2_2 1 1 5 3 6 5 2 2 6 2 1 4 > cast(md,ID+variable~Time) ID variable 1 2 1 1 X1 5 3 2 1 X2 6 5 3 2 X1 6 2 4 2 X2 1 4 > cast(md,ID+Time~variable) ID Time X1 X2 1 1 1 5 6 2 1 2 3 5 3 2 1 6 1 4 2 2 2 4
虽然只列出了3个例子,但是足以看到reshape包的强大
这些基本R 的工具掌握了,后面就可以开始进行真正的数据分析了啊
最后的最后,感谢作者Rober I. Kabacoff等,译者高涛、肖楠、陈钢
《R语言实战》学习笔记fifth,布布扣,bubuko.com
标签:style blog class code java tar
原文地址:http://www.cnblogs.com/SSSSQD/p/3703496.html