标签:data nod mod images bin slave dir 技术分享 nbsp
配置Spark standalone HA
主机:node1,node2,node3
master: node1,node2
slave:node2,node3
node1,node3: spark-env.sh
export SPARK_MASTER_IP=node1 export SPARK_MASTER_PORT=7077 export SPARK_WORKER_CORES=1 export SPARK_WORKER_INSTANCES=1 export SPARK_WORKER_MEMORY=1024m export SPARK_LOCAL_DIRS=/data/spark/dataDir export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/sparkHA"
node2: spark-env.sh
export SPARK_MASTER_IP=node2
node2与node1的差别仅在此
ZooKeeper已经启动完毕,这里没有说明ZooKeeper的配置和启动。
spark启动脚本
node1:
/sbin/start-all.sh
node2:
/sbin/start-master.sh
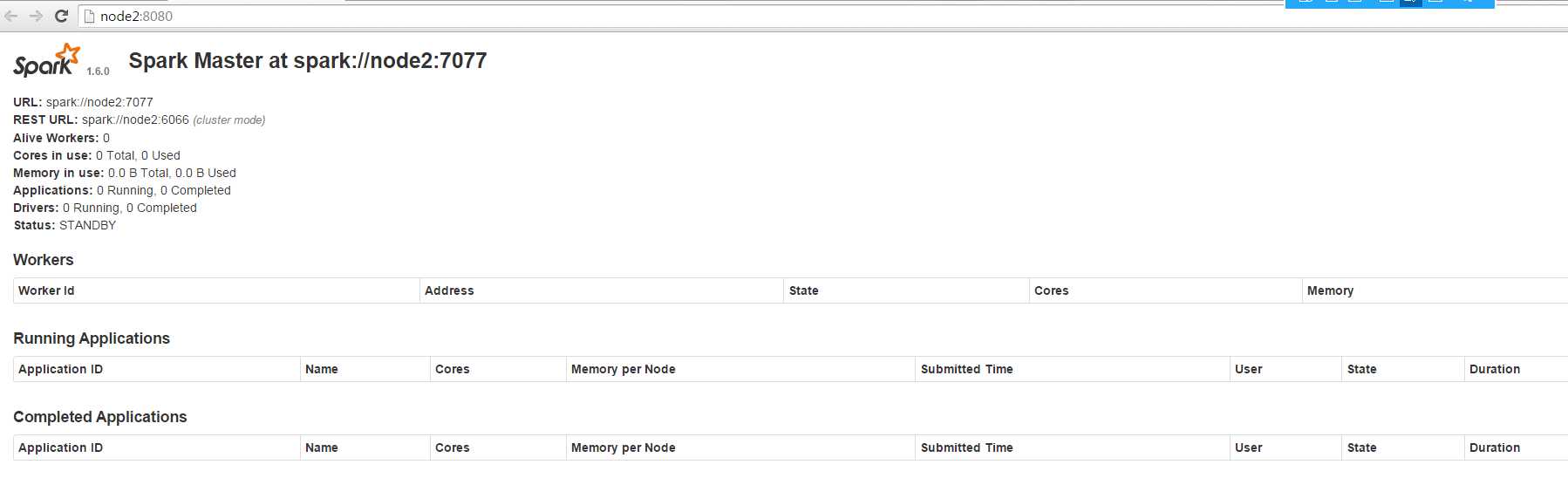
停掉node1 master
/sbin/stop-master.sh
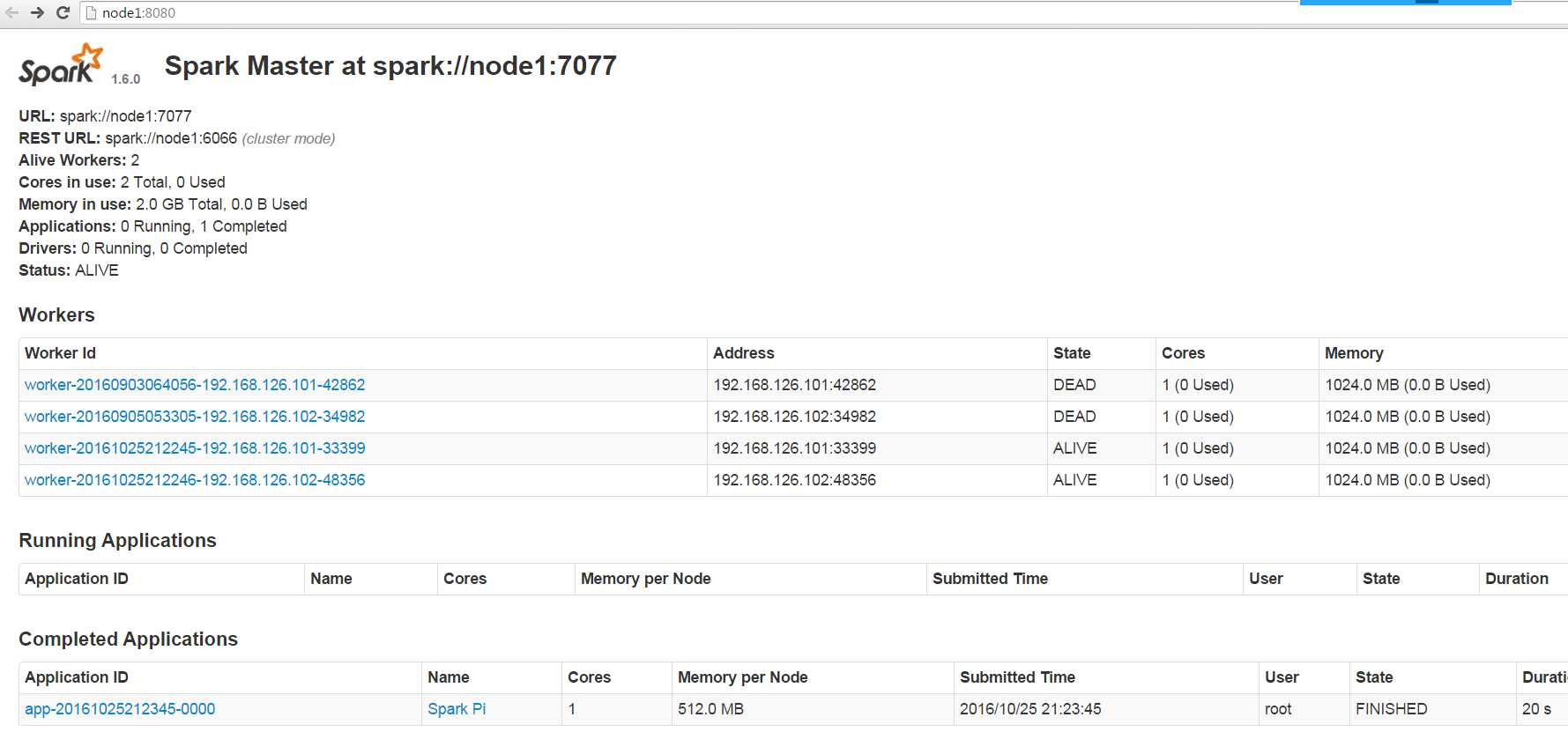
访问node2的master
没有停掉node1的master,访问node2
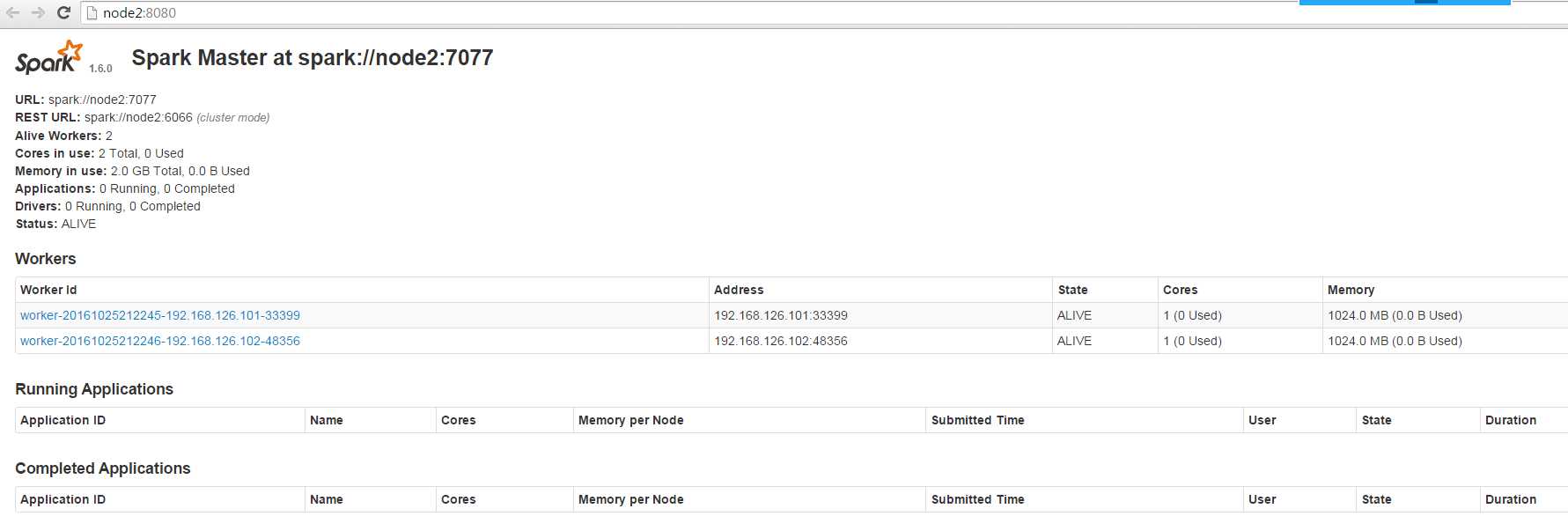
停掉node1的master之后,访问node2
标签:data nod mod images bin slave dir 技术分享 nbsp
原文地址:http://www.cnblogs.com/one--way/p/5998451.html