标签:hello 1.5.0 ash read 终端 perl editable sep 作业
spark都进化到2.0了,虽然之前对spark有所了解但总感觉似懂非懂的,所以想花时间看看源码。
面对大量的源码从哪里着手呢,想到老子的一句话“天下难事必作于易,天下大事必作于细”,所以就从脚本部分来啃。
因本人脚本编程能力也并不是那么强,所以在总结的时候会穿插一些shell的东西。此处只介绍shell脚本,不涉及bat脚本。
先按照首字母顺序介绍下每个脚本的功能:
spark-1.5.0/bin
beeline:基于SQLLine CLI的JDBC客户端,可以连接到hive,操作hive中的数据。
load-spark-env.sh:导入conf目录下的spark-env.sh文件。
pyspark:python调用spark.
run-example:运行examples目录下的示例。
spark-class:调用org.apache.spark.launcher.Main, 多被其他脚本调用。
spark-shell:spark shell交互脚本。
spark-sql:spark sql运行脚本。
spark-submit:spark作业提交脚本。
sparkR:R语言调用spark。
再介绍下脚本之间的调用关系:
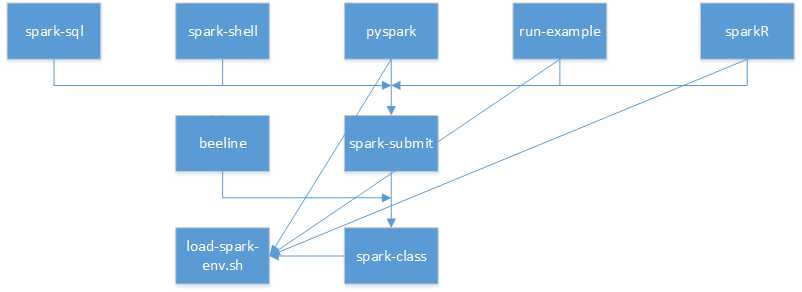
[注]箭头所指方向为被依赖或被引用的脚本
部分脚本解析:
spark-calss部分代码:
# The launcher library will print arguments separated by a NULL character, to allow arguments with # characters that would be otherwise interpreted by the shell. Read that in a while loop, populating # an array that will be used to exec the final command. CMD=() while IFS= read -d ‘‘ -r ARG; do CMD+=("$ARG") done < <("$RUNNER" -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main "$@")
exec "${CMD[@]}"
注解:对比之前版本的脚本,现在的脚本简化了很多东西,好多判断都移动到了java或scala代码内。下一步就是分析org.apache.spark.launcher.Main 这个类。
spark-shell 代码:
#!/usr/bin/env bash # Shell script for starting the Spark Shell REPL #验证是否是cygwin cygwin=false case "`uname`" in CYGWIN*) cygwin=true;; esac # 开启posix模式 set -o posix #获取父级目录的绝对路径,$0为当前脚本名 export FWDIR="$(cd "`dirname "$0"`"/..; pwd)" export _SPARK_CMD_USAGE="Usage: ./bin/spark-shell [options]" #手动添加 -Dscala.usejavacp=true,scala 默认不会使用 java classpath SPARK_SUBMIT_OPTS="$SPARK_SUBMIT_OPTS -Dscala.usejavacp=true" #脚本入口,实际调用的是spark-submit脚本 function main() { if $cygwin; then stty -icanon min 1 -echo > /dev/null 2>&1 export SPARK_SUBMIT_OPTS="$SPARK_SUBMIT_OPTS -Djline.terminal=unix" "$FWDIR"/bin/spark-submit --class org.apache.spark.repl.Main --name "Spark shell" "$@" stty icanon echo > /dev/null 2>&1 else export SPARK_SUBMIT_OPTS "$FWDIR"/bin/spark-submit --class org.apache.spark.repl.Main --name "Spark shell" "$@" fi } # Copy restore-TTY-on-exit functions from Scala script so spark-shell exits properly even in # binary distribution of Spark where Scala is not installed exit_status=127 saved_stty="" # restore stty settings (echo in particular) function restoreSttySettings() { stty $saved_stty saved_stty="" } function onExit() { if [[ "$saved_stty" != "" ]]; then restoreSttySettings fi exit $exit_status } # 中断时进行的操作 trap onExit INT # 保存终止设置 saved_stty=$(stty -g 2>/dev/null) # clear on error so we don‘t later try to restore them if [[ ! $? ]]; then saved_stty="" fi #调用main函数 main "$@" # 记录脚本退出状态 # then reenable echo and propagate the code. exit_status=$? onExit
注解:显然spark-shell调用的是spark-submit ,利用--class org.apache.spark.repl.Main --name "Spark shell"传入参数。
此处本人主要对shell交互的实现比较感兴趣,后续会调研下,之后研究的类自然是class org.apache.spark.repl.Main。
spark-sql代码
export FWDIR="$(cd "`dirname "$0"`"/..; pwd)" export _SPARK_CMD_USAGE="Usage: ./bin/spark-sql [options] [cli option]" exec "$FWDIR"/bin/spark-submit --class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver "$@"
注解:这部分脚本简单明了,要调研的类也很清楚:org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver 。
spark sql虽然操作的是hive,但是比HQL快多了,基于内存的计算果断有优势啊。
spark-submit代码
SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)" # disable randomized hash for string in Python 3.3+ export PYTHONHASHSEED=0 exec "$SPARK_HOME"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"
注解:不兼容python3.3+以上的版本,具体原因不明,表示没怎么接触过python。
调用spark-class实现的job提交,以何种模式提交的判断猜测应该在org.apache.spark.deploy.SparkSubmit中。
sparkR代码:
export SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)" source "$SPARK_HOME"/bin/load-spark-env.sh export _SPARK_CMD_USAGE="Usage: ./bin/sparkR [options]" exec "$SPARK_HOME"/bin/spark-submit sparkr-shell-main "$@"
注解:实现的方式与python类似。
shell不明点参照:
1.set -o posix
set命令是shell解释器的一个内置命令,用来设置shell解释器的属性,从而能够控制shell解释器的一些行为。
在set命令中,选项前面跟着 - 号表示开启这个选项, + 表示关闭这个选项。
set -o posix:开启bash的posix模式。
2.command -v java
command [-pVv] command [arg ...]
用command指定可取消正常的shell function寻找。只有内建命令及在PATH中找得到的才会被执行。
"-p"选项,搜寻命令的方式是用PATH来找。"-V"或"-v"选项,会显示出该命令的一些简约描述。
3.[ [[ test
[ is a shell builtin
[[ is a shell keyword
test is a shell builtin
[ = test
[[ 可用 && | ,常用可避免错误。
4.read -d
-d :表示delimiter,即定界符,一般情况下是以IFS为参数的间隔,但是通过-d,我们可以定义一直读到出现执行的字符位置。例如read –d madfds value,读到有m的字符的时候就不在继续向后读,例如输入为 hello m,有效值为“hello”,请注意m前面的空格等会被删除。这种方式可以输入多个字符串,例如定义“.”作为结符号等等
read命令 -n(不换行) -p(提示语句) -n(字符个数) -t(等待时间) -s(不回显)
5.setty
stty(set tty)命令用于显示和修改当前注册的终端的属性。
tty -icanon 设置一次性读完操作,如使用getchar()读操作,不需要按enter
stty icanon 取消上面设置
[-]icanon
enable erase, kill, werase, and rprnt special characters
6.$@
输入参数,常与shift连用。参数较多或参数个数不确定时可用。
总结:
shell脚本遵循简单明了的原则,而对比以前的脚本也会发现这点,一些复杂的判断逻辑大多都移入源码里了,例如submit脚本中运行模式的判断,这样会使脚本精简很多。
bin下的脚本都以2个空格为缩进,同一脚本中逻辑不同的代码块之间空行分隔,另有必要的注释,风格统一。
环境变量或全局变量的引入是放在load-spark-env.sh中的,其他脚本再以 . 的方式引入,脚本复用。
parent_dir="$(cd "`dirname "$0"`"/..; pwd)" 是一段很有用的代码。
命令性质的脚本统一放在了bin下,而功能性质的大多都放在了sbin下。
标签:hello 1.5.0 ash read 终端 perl editable sep 作业
原文地址:http://www.cnblogs.com/GodMode/p/5896605.html