标签:chrome 分享 reg user python 是什么 通过 type username
由于好奇一直想试试模拟登陆,然后就把目标定在某所大学的登录网站上
大至样式就是这样的
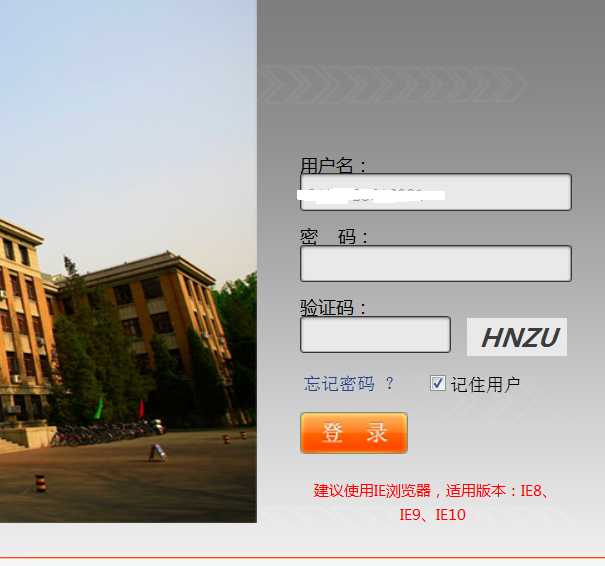
通过界面我们大致可以了解到请求可能会后username,password,验证码,记住用户
接着使用burp进行抓包得:
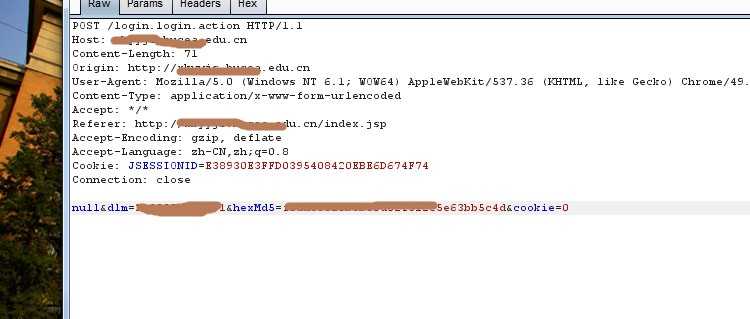
可以通过post请求知道dlm就是uesrname,hexMd5是加密后的password(加密手段应该是MD5),cookie就是记住用户
...等等,怎么没有验证码,真奇怪,算了待会再看验证码把
通过浏览器中查看源码,得:

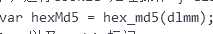
我们看出来dlmm是原始密码,而hexMd5是通过md5加密后的值
而后我的好奇心又回到了验证码上,源码显示:
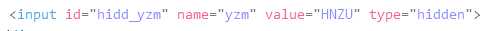
哈哈哈,验证码居然在明面上,那简直太简单了,抓一下试试,代码如下:
1 import re 2 def reg_html(html): 3 parttern = re.compile(r‘<input type="hid.*‘) 4 yzm = parttern.findall(html) 5 return yzm
但结果也大失所望,抓到的value值为空,可能是我对前端知识不太了解,愿意坚持看下去

发现这个验证码调用了一个js的generateMixed函数
找到这个函数 得:

大致看明白了,别的还好说,关键这个random就让人没法弄啊。苦恼想放弃.....回家!
在路上,我问了一个师哥,我说我的post请求里没有验证码这是什么情况,他告诉我两种情况:
1 验证码在只是在前端作为一个check,可以绕过
2 验证码可能和用户密码等参数分着发过去了
我不解,回去用fiddler又做了一次抓包,post的数据中确实没有验证码,所以我猜想是第二种可能
于是我写了个脚本进行验证 代码如下:
1 #!/usr/bin/env python 2 #coding:utf-8 3 4 import re 5 import requests 6 from bs4 import BeautifulSoup 7 import hashlib 8 9 URL = ‘http://xxxxx.xxxxxx.edu.cn/login.login.action‘ #login_url 10 URL_p = ‘http://xxxxx.xxxxxx.edu.cn/login.toStudentJsp.action?math=4636‘ #跳转url,可以通过js找到 11 URL_p2 = ‘http://xxxxxx.xxxxxx.edu.cn/stumiddle.jsp‘ #user_info_url 12 13 def md5Encode(string): 14 m = hashlib.md5() 15 m.update(string) 16 return m.hexdigest() 17 18 def post_html(url,url2,url3): 19 session = requests.Session() 20 headers = {‘User-Agent‘:‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1581.2 Safari/537.36‘} 21 payload = {‘dlm‘:‘xxxxxxxxxxxxxxx‘, 22 ‘hexMd5‘:‘%s‘%md5Encode(‘xxxxxxxxxxxxxx‘), 23 ‘cookie‘:‘0‘ 24 } 25 session.post(url,data=payload,headers=headers) 26 session.get(url2,headers=headers) 27 text = session.get(url3,headers=headers).text 28 return text 29 30 def parser_html(html): 31 soup = BeautifulSoup(html,‘html.parser‘) 32 return soup.prettify() 33 34 35 if __name__ == ‘__main__‘: 36 parser_html(post_html(URL,URL_p,URL_p2))
其中URL_p可以通过fiddler抓包得到或者通过js的跳转代码也可以找到,其中math=4636,如果看到js源码,这个就是js随机生成的一个4位数,可能为了标记每次的用户信息页面不一样吧
URL_p2通过fildder可以找到
运行这个脚本,如果我们的username或者password有错误,会返回这个text

但如果正确,则会get到正确页面,下图是上面脚本运行后,fiddler抓到的

模拟登陆成功了!,完全绕过了页面的验证码环节。
那么话说回来,既然有账号密码,我用的着这么麻烦,我个人认为有两方面原因
一是为了练习一下模拟登陆
二是可以 b r u t e f o r c e 阿,但我有个不好的消息,这所大学的登录系统,如果5次尝试失败,会将username冻住30分钟。这真是杀敌一千自损八百啊,
但如果你要真想让这个用户崩,你可以写一个30钟登录5次的模拟登陆脚本,让该用户始终上不了。
haha,不聊了,看电视剧去了
标签:chrome 分享 reg user python 是什么 通过 type username
原文地址:http://www.cnblogs.com/fuzzier/p/6000548.html