标签:数据传输 html 分类 框架 遍历 摩托罗拉 摄像头 深度 扩展
使用python抓取京东商城商品(以手机为例)的详细信息,并将相应的图片下载下载保存到本地。
1.选取种子URL:http://list.jd.com/list.html?cat=9987,653,655
2.使用urllib和urllib2下载网页
3.使用BeautifulSoup和re正则表达式解析html
4.保存数据
python2.7
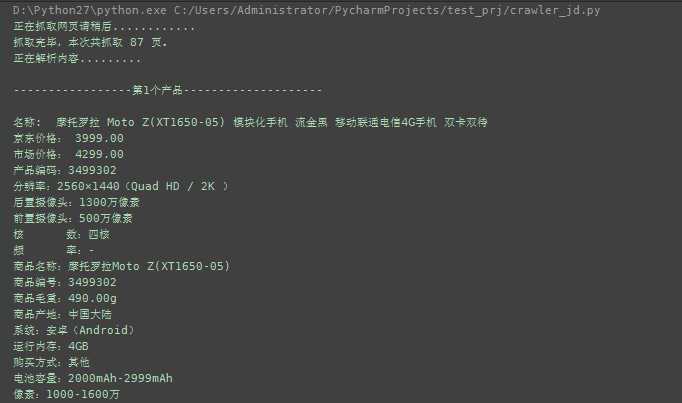
名称: 摩托罗拉 Moto Z(XT1650-05) 模块化手机 流金黑 移动联通电信4G手机 双卡双待
京东价格: 3999.00
市场价格: 4299.00
产品编码:3499302
分辨率:2560×1440(Quad HD / 2K )
后置摄像头:1300万像素
前置摄像头:500万像素
核 数:四核
频 率:-
商品名称:摩托罗拉Moto Z(XT1650-05)
商品编号:3499302
商品毛重:490.00g
商品产地:中国大陆
系统:安卓(Android)
运行内存:4GB
购买方式:其他
电池容量:2000mAh-2999mAh
像素:1000-1600万
机身内存:64GB
热点:骁龙芯片,双卡双待,快速充电,指纹识别,VoLTE,金属机身,2K屏,支持NFC
品牌 摩托罗拉(Motorola)
型号 XT1650-05
入网型号 XT1650-05
上市年份 2016年
上市月份 9月
机身颜色 黑色前后面板加玫瑰金硬铝框架
机身长度(mm) 155.3
机身宽度(mm) 75.3
机身厚度(mm) 5.19
机身重量(g) 134
输入方式 触控
运营商标志或内容 无
机身材质分类 其他;金属边框
机身材质工艺 美国铝业航空级硬铝
操作系统 Android
操作系统版本 6.0.1
CPU品牌 骁龙(Snapdragon)
CPU频率 -
CPU核数 四核
CPU型号 骁龙820(MSM8996)
双卡机类型 双卡双待单通
最大支持SIM卡数量 2个
SIM卡类型 Nano SIM
4G网络 4G:移动(TD-LTE);4G:联通(FDD-LTE);4G:电信(FDD-LTE);4G:联通(TD-LTE)
3G/2G网络 3G:移动(TD-SCDMA);3G:联通(WCDMA);3G:电信(CDMA2000);2G:移动联通(GSM)+电信(CDMA)
4G+(CA) 移动4G+;联通4G+;电信4G+
高清语音通话(VOLTE) 移动VOLTE
网络频率(2G/3G) 2G:GSM 850/900/1800/1900;3G:TD-SCDMA 1900/2000
ROM 64GB
RAM 4GB
RAM类型 LPDDR 4
存储卡 支持MicroSD(TF)
最大存储扩展容量 2TB
主屏幕尺寸(英寸) 5.5英寸
分辨率 2560×1440(Quad HD / 2K )
屏幕像素密度(ppi) 540
屏幕材质类型 OLED
触摸屏类型 电容屏
前置摄像头 500万像素
前摄光圈大小 f/2.2
闪光灯 LED灯
摄像头数量 1个
后置摄像头 1300万像素
摄像头光圈大小 f/1.8
闪光灯 LED灯
拍照特点 数码变焦;防抖;全景;HDR
电池容量(mAh) 2600
电池类型 锂电池
电池是否可拆卸 否
充电器 5V/3A
数据传输接口 WIFI;NFC;蓝牙;WiFi热点
NFC/NFC模式 其他
耳机接口类型 Type-C
充电接口类型 Type-C
数据线 USB3.0
指纹识别 支持
语音识别 支持
GPS 支持
电子罗盘 支持
陀螺仪 支持
其他 光线感应
常用功能 收音机;录音;手势识别;便签;超大字体;重力感应

1 # coding=utf-8 2 3 #导入模块 4 import urllib2,re,urllib 5 from bs4 import BeautifulSoup 6 import json,time 7 8 9 #定义抓取类 10 class JD: 11 12 #记录抓取产品个数 13 prodNum = 1 14 #初始化参数 15 def __init__(self,baseurl,page): 16 self.baseurl = baseurl 17 self.page = page 18 #拼装成url 19 self.url = self.baseurl+‘&‘+‘page=‘+str(self.page) 20 #获取html源代码 21 def getHtml(self,url): 22 #请求抓取对象 23 request = urllib2.Request(url) 24 #响应对象 25 reponse = urllib2.urlopen(request) 26 #读取源代码 27 html = reponse.read() 28 #返回源代码 29 return html 30 #获取总页数 31 def getNum(self,html): 32 #封装成BeautifulSoup对象 33 soup = BeautifulSoup(html) 34 #定位到总页数节点 35 items = soup.find_all(‘span‘,class_=‘p-skip‘) 36 #获取总页数 37 for item in items: 38 pagenum = item.find(‘em‘).find(‘b‘).string 39 return pagenum 40 #获取所有产品id列表 41 def getIds(self,html): 42 #生成匹配规则 43 pattern = re.compile(‘<a target="_blank" href="//item.jd.com/(.*?).html".*?>‘) 44 #查询匹配对象 45 items = re.findall(pattern,html) 46 return items 47 #根据产品id获取同款产品列表 48 def getIdByItems(self,id): 49 #拼装成url 50 url = basePd+str(id)+‘.html‘ 51 #调用抓取函数返回源代码 52 html = self.getHtml(url) 53 # 封装成BeautifulSoup对象 54 soup = BeautifulSoup(html) 55 #查询匹配对象 56 items = soup.find(‘div‘,class_=‘dd clearfix‘) 57 l = [] 58 #生成列表 59 for item in items: 60 pattern = re.compile(‘href="//item.jd.com/(.*?).html".*?>‘) 61 id = re.findall(pattern,str(item)) 62 if id: 63 l += id 64 return l 65 66 #获取产品价格 67 def getPrice(self,id): 68 url = ‘http://p.3.cn/prices/mgets?skuIds=J_‘+str(id) 69 jsonString = self.getHtml(url) 70 jsonObject = json.loads(jsonString.decode()) 71 price_jd = jsonObject[0][‘p‘] 72 price_mk = jsonObject[0][‘m‘] 73 print ‘京东价格:‘,str(price_jd) 74 print ‘市场价格:‘,str(price_mk) 75 76 #获取产品图片 77 def getImg(self,html,subid): 78 pattern = re.compile(r‘<img id=.*?data-origin="(.*?)" alt=.*?‘, re.S) 79 items = re.findall(pattern, html) 80 for item in items: 81 imgurl = ‘http:%s‘ % (item) 82 urllib.urlretrieve(imgurl, ‘d:/temp/jdimg/%s.jpg‘ % (str(subid))) 83 84 #获取内容 85 def getContent(self,html,subid): 86 soup = BeautifulSoup(html) 87 title = soup.find(‘div‘,class_=‘sku-name‘) 88 print ‘\n-----------------第‘+ str(JD.prodNum) +‘个产品--------------------\n‘ 89 for t in title: 90 print ‘名称: ‘,t.string 91 time.sleep(1) 92 #价格 93 self.getPrice(subid) 94 #编码 95 print ‘产品编码:%s‘ % (str(subid)) 96 items1 = soup.find_all(‘ul‘,class_=‘parameter1 p-parameter-list‘) 97 #商品基本信息 98 for item in items1: 99 p = item.findAll(‘p‘) 100 for i in p: 101 print i.string 102 # 商品基本信息 103 items2 = soup.find_all(‘ul‘, class_=‘parameter2 p-parameter-list‘) 104 for item in items2: 105 p = item.findAll(‘li‘) 106 for i in p: 107 print i.string 108 #规格与包装 109 items3 = soup.find_all(‘div‘,class_=‘Ptable-item‘) 110 for item in items3: 111 contents1 = item.findAll(‘dt‘) 112 contents2 = item.findAll(‘dd‘) 113 for i in range(len(contents1)): 114 print contents1[i].string,contents2[i].string 115 JD.prodNum += 1 116 #启动抓取程序 117 def start(self): 118 html = spider.getHtml(self.url) 119 pageNum = self.getNum(html) 120 print ‘正在抓取网页请稍后............‘ 121 time.sleep(3) 122 print ‘抓取完毕,本次共抓取‘,pageNum,‘页。‘ 123 time.sleep(1) 124 print ‘正在解析内容.........‘ 125 #循环1--页数 126 for page in range(1,int(pageNum)+1): 127 url = self.baseurl+‘&‘+‘page=‘+str(page) 128 html = self.getHtml(url) 129 ids = self.getIds(html) 130 #循环2--产品列表 131 for id in ids: 132 urlprod = basePd+str(id)+‘.html‘ 133 htmlprod = self.getHtml(urlprod) 134 subids = self.getIdByItems(id) 135 #循环3--产品组列表 136 for subid in subids: 137 urlsubprod = basePd+str(subid)+‘.html‘ 138 subhtml = self.getHtml(urlsubprod) 139 time.sleep(1) 140 self.getContent(subhtml,subid) 141 self.getImg(subhtml,subid) 142 143 #产品列表base页 144 basePd = ‘http://item.jd.com/‘ 145 #抓取入口URL 146 baseURL = ‘http://list.jd.com/list.html?cat=9987,653,655‘ 147 #生成爬虫抓取对象 148 spider = JD(baseURL,1) 149 150 #开始抓取 151 spider.start()
一、网络爬虫的基本结构及工作流程
一个通用的网络爬虫的框架如图所示:
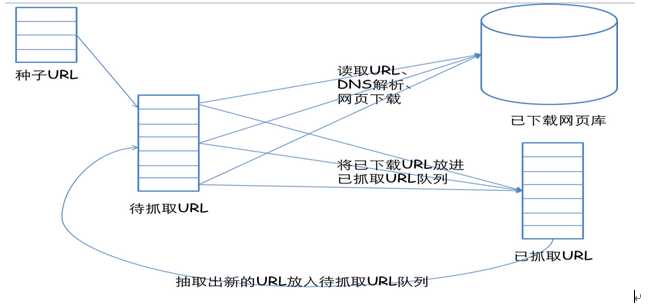
网络爬虫的基本工作流程如下:
1.首先选取一部分精心挑选的种子URL;
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
二、从爬虫的角度对互联网进行划分
对应的,可以将互联网的所有页面分为五个部分:
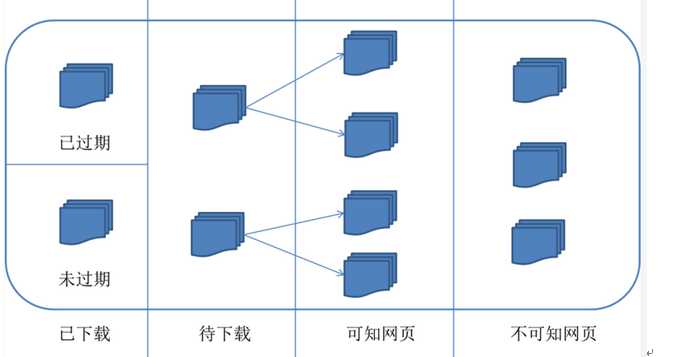
1.已下载未过期网页
2.已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的,一部分互联网上的内容已经发生了变化,这时,这部分抓取到的网页就已经过期了。
3.待下载网页:也就是待抓取URL队列中的那些页面
4.可知网页:还没有抓取下来,也没有在待抓取URL队列中,但是可以通过对已抓取页面或者待抓取URL对应页面进行分析获取到的URL,认为是可知网页。
5.还有一部分网页,爬虫是无法直接抓取下载的。称为不可知网页。
三、抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。我们以下面的图为例:
如下遍历路径:A-F-G E-H-I B C D
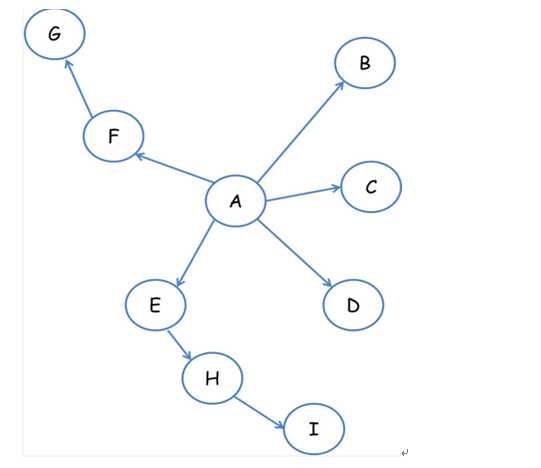
2.宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以上面的图为例:
遍历路径:A-B-C-D-E-F G H I
3.反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数量。反向链接数表示的是一个网页的内容受到其他人的推荐的程度。因此,很多时候搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后顺序。
在真实的网络环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那个也的重要程度。因此,搜索引擎往往考虑一些可靠的反向链接数。
4.Partial PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于已经下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每个页面的PageRank值,计算完之后,将待抓取URL队列中的URL按照PageRank值的大小排列,并按照该顺序抓取页面。
如果每次抓取一个页面,就重新计算PageRank值,一种折中方案是:每抓取K个页面后,重新计算一次PageRank值。但是这种情况还会有一个问题:对于已经下载下来的页面中分析出的链接,也就是我们之前提到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总,这样就形成了该未知页面的PageRank值,从而参与排序。下面举例说明:
5.OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P之后,将P的现金分摊给所有从P中分析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面按照现金数进行排序。
6.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因此叫做大站优先策略。
----------------------------谢谢大家-----------------------------------
标签:数据传输 html 分类 框架 遍历 摩托罗拉 摄像头 深度 扩展
原文地址:http://www.cnblogs.com/majh/p/6004622.html
