标签:购物 技术 最好 img oba 递推 之间 pre viterbi
链接:https://www.zhihu.com/question/20962240/answer/33438846
霍金曾经说过,你多写一个公式,就会少一半的读者。
还是用最经典的例子,掷骰子。假设我手里有三个不同的骰子。
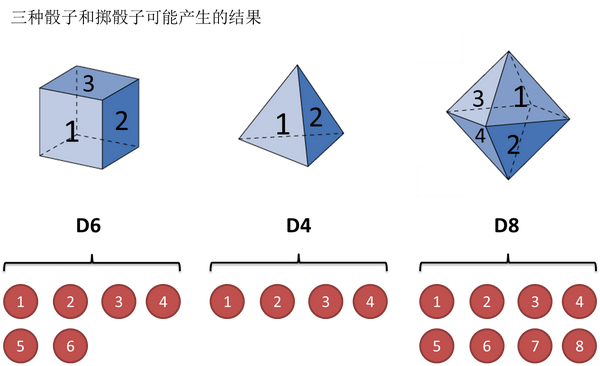
假设我们开始掷骰子,我们先从三个骰子里挑一个,挑到每一个骰子的概率都是1/3。
然后我们掷骰子,得到一个数字,1,2,3,4,5,6,7,8中的一个。
不停的重复上述过程,我们会得到一串数字,每个数字都是1,2,3,4,5,6,7,8中的一个。
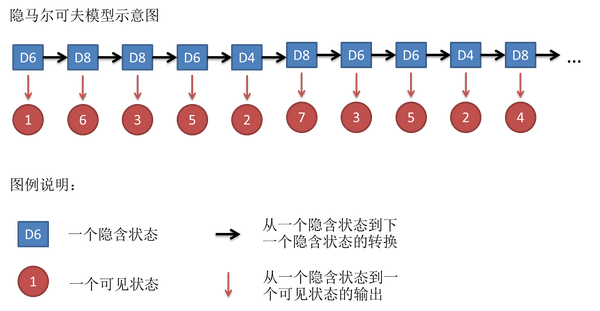
例如我们可能得到这么一串数字(掷骰子10次):1 6 3 5 2 7 3 5 2 4
这串数字叫做可见状态链。
但是在隐马尔可夫模型中,我们不仅仅有这么一串可见状态链,还有一串隐含状态链。在这个例子里,这串隐含状态链就是你用的骰子的序列。
比如,隐含状态链有可能是:D6 D8 D8 D6 D4 D8 D6 D6 D4 D8
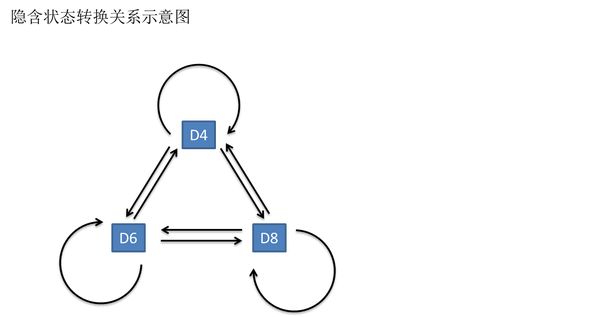
隐含状态(骰子)之间存在转换概率(transition probability)。
在我们这个例子里,D6的下一个状态是D4,D6,D8的概率都是1/3。
D4,D8的下一个状态是D4,D6,D8的转换概率也都一样是1/3。
这样设定是为了最开始容易说清楚,但是我们其实是可以随意设定转换概率的。比如,我们可以这样定义,D6后面不能接D4,D6后面是D6的概率是0.9,是D8的概率是0.1。这样就是一个新的HMM。
同样的,尽管可见状态之间没有转换概率,
但是隐含状态和可见状态之间有一个概率叫作 输出概率(emission probability)。
就我们的例子来说,六面骰(D6)产生1的输出概率是1/6。产生2,3,4,5,6的概率也都是1/6。我们同样可以对输出概率进行其他定义。比如,我有一个被赌场动过手脚的六面骰子,掷出来是1的概率更大,是1/2,掷出来是2,3,4,5,6的概率是1/10。
其实对于HMM来说,如果提前知道所有隐含状态之间的转换概率和所有隐含状态到所有可见状态之间的输出概率,做模拟是相当容易的。但是应用HMM模型时候呢,往往是缺失了一部分信息的,有时候你知道骰子有几种,每种骰子是什么,但是不知道掷出来的骰子序列;有时候你只是看到了很多次掷骰子的结果,剩下的什么都不知道。如果应用算法去估计这些缺失的信息,就成了一个很重要的问题。这些算法我会在下面详细讲。
回到正题,和HMM模型
相关的算法主要分为三类,分别解决三种问题:
1)知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道每次掷出来的都是哪种骰子(隐含状态链)。这个问题呢,在语音识别领域呢,叫做
解码问题。
这个问题其实有两种解法,会给出两个不同的答案。每个答案都对,只不过这些答案的意义不一样。
- 第一种解法求最大似然状态路径,说通俗点呢,就是我求一串骰子序列,这串骰子序列产生观测结果的概率最大。(这里只讲这个)
- 第二种解法呢,就不是求一组骰子序列了,而是求每次掷出的骰子分别是某种骰子的概率。比如说我看到结果后,我可以求得第一次掷骰子是D4的概率是0.5,D6的概率是0.3,D8的概率是0.2.第一种解法我会在下面说到,但是第二种解法我就不写在这里了,如果大家有兴趣,我们另开一个问题继续写吧。
2)还是知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道掷出这个结果的概率。
看似这个问题意义不大,因为你掷出来的结果很多时候都对应了一个比较大的概率。问这个问题的目的呢,其实是检测观察到的结果和已知的模型是否吻合。如果很多次结果都对应了比较小的概率,那么就说明我们已知的模型很有可能是错的,有人偷偷把我们的骰子給换了。
3)知道骰子有几种(隐含状态数量),不知道每种骰子是什么(转换概率),观测到很多次掷骰子的结果(可见状态链),我想反推出每种骰子是什么(转换概率)。
这个问题很重要,因为这是最常见的情况。很多时候我们只有可见结果,不知道HMM模型里的参数,我们需要从可见结果估计出这些参数,这是建模的一个必要步骤。
问题阐述完了,下面就开始说解法。(0号问题在上面没有提,只是作为解决上述问题的一个辅助)
0.一个简单问题
其实这个问题实用价值不高。由于对下面较难的问题有帮助,所以先在这里提一下。
“知道骰子有几种,每种骰子是什么,每次掷的都是什么骰子,根据掷骰子掷出的结果,求产生这个结果的概率。”
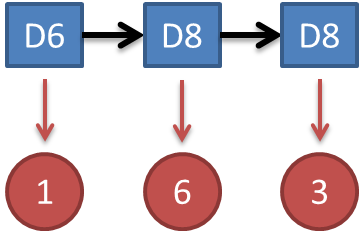
解法无非就是概率相乘:
1.看见不可见的,破解骰子序列
这里我说的是第一种解法,解最大似然路径问题。
举例来说,我知道我有三个骰子,六面骰,四面骰,八面骰。我也知道我掷了十次的结果(1 6 3 5 2 7 3 5 2 4),我不知道每次用了那种骰子,我想知道最有可能的骰子序列。
其实最简单而暴力的方法就是穷举所有可能的骰子序列,然后
依照第零个问题的解法把每个序列对应的概率算出来。然后我们从里面把对应最大概率的序列挑出来就行了。如果马尔可夫链不长,当然可行。如果长的话,穷举的数量太大,就很难完成了。
另外一种很有名的算法叫做
Viterbi algorithm. 要理解这个算法,我们先看几个简单的列子。
(1)首先,如果我们只掷一次骰子:

因为D4产生1的概率是1/4,高于1/6和1/8,so,对应的最大概率骰子序列就是D4,
(2)把这个情况拓展,我们掷两次骰子:

结果为1,6.这时问题变得复杂起来,我们要计算三个值,分别是第二个骰子是D6,D4,D8的最大概率。
显然,要取到最大概率,第一个骰子必须为D4。第二个骰子取D6:
同样的,我们可以计算第二个骰子是D4或D8时的最大概率。我们发现,第二个骰子取到D6的概率最大。
(3)继续拓展,我们掷三次骰子:

同样,我们计算第三个骰子分别是D6,D4,D8的最大概率。我们再次发现,要取到最大概率,第二个骰子必须为D6。这时,第三个骰子取到D4的最大概率是:
同上,我们可以计算第三个骰子是D6或D8时的最大概率。我们发现,第三个骰子取到D4的概率最大。而使这个概率最大时,第二个骰子为D6,第一个骰子为D4。所以最大概率骰子序列就是D4 D6 D4。
写到这里,大家应该看出点规律了。既然掷骰子一二三次可以算,掷多少次都可以以此类推。我们发现,我们要求最大概率骰子序列时要做这么几件事情。首先,不管序列多长,要从序列长度为1算起,算序列长度为1时取到每个骰子的最大概率。然后,逐渐增加长度,每增加一次长度,重新算一遍在这个长度下最后一个位置取到每个骰子的最大概率。因为上一个长度下的取到每个骰子的最大概率都算过了,重新计算的话其实不难。当我们算到最后一位时,就知道最后一位是哪个骰子的概率最大了。然后,我们要把对应这个最大概率的序列从后往前推出来。
2.谁动了我的骰子?
比如说你怀疑自己的六面骰被赌场动过手脚了,有可能被换成另一种六面骰,这种六面骰掷出来是1的概率更大,是1/2,掷出来是2,3,4,5,6的概率是1/10。你怎么办么?答案很简单,算一算正常的
三个骰子掷出一段序列的概率,再算一算
不正常的六面骰和
另外两个正常骰子掷出这段序列的概率。如果前者比后者小,你就要小心了。
比如说掷骰子的结果是:
要算用正常的三个骰子掷出这个结果的概率,其实就是将所有可能情况的概率进行加和计算。同样,简单而暴力的方法就是把穷举所有的骰子序列,还是计算每个骰子序列对应的概率,但是这回,我们不挑最大值了,而是把所有算出来的概率相加,得到的总概率就是我们要求的结果。这个方法依然不能应用于太长的骰子序列(马尔可夫链)。
我们会应用一个和前一个问题类似的解法,只不过
前一个问题关心的是
概率最大值,这个问题关心的是
概率之和。解决这个问题的算法叫做
前向算法(forward algorithm)。
首先,如果我们只掷一次骰子:
看到结果为1.产生这个结果的总概率可以按照如下计算,总概率为0.18:

把这个情况拓展,我们掷两次骰子:
看到结果为1,6.产生这个结果的总概率可以按照如下计算,总概率为0.05:

继续拓展,我们掷三次骰子:
看到结果为1,6,3. 产生这个结果的总概率可以按照如下计算,总概率为0.03:
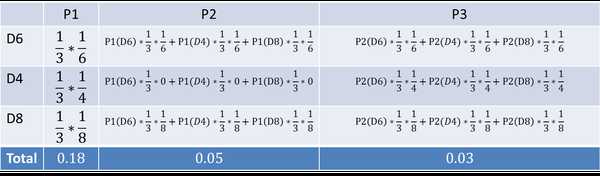
同样的,我们一步一步的算,有多长算多长,再长的马尔可夫链总能算出来的。用同样的方法,也可以算出不正常的六面骰和另外两个正常骰子掷出这段序列的概率,然后我们比较一下这两个概率大小,就能知道你的骰子是不是被人换了。
3.掷一串骰子出来,让我猜猜你是谁
(答主很懒,还没写,会写一下EM这个号称算法的方法)
链接:https://www.zhihu.com/question/20962240/answer/33561657
下图是一个例子,这时候大叔切换骰子的可能性被描述得淋漓尽致。
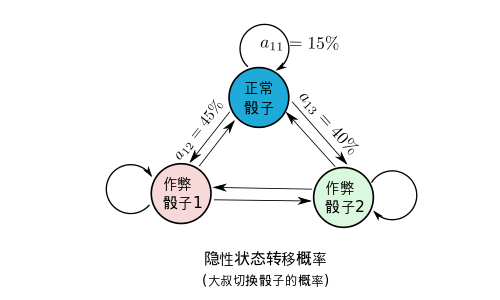
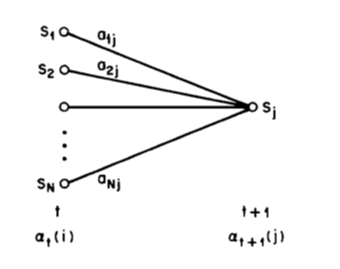
隐形状态转移概率:概率转移图,其中a_{ij}代表的是从i状态到j状态发生的概率

隐性状态表现转移概率。也就是骰子出现各点的概率分布,
(e.g. 作弊骰子1能有90%的机会掷到六,作弊骰子2有85%的机会掷到‘小’). 给个图如下,
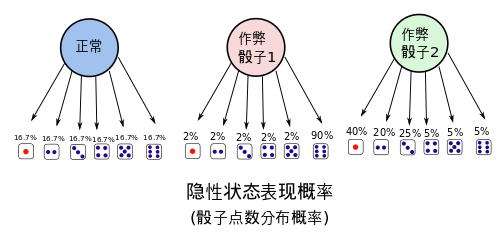
隐性状态表现概率也可以用矩阵表示出来,

把这两个东西总结起来,就是整个HMM模型。
比如我们想知道这位大叔下一局连续掷出10个6的概率是多少? 如下
先假设一个隐性状态序列,
假设大叔前5个用的是正常骰子, 后5个用的是作弊骰子1.
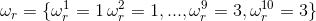
好了,那么我们可以计算,在这种隐性序列假设下掷出10个6的概率.
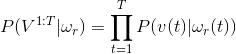
这个概率其实就是,
隐性状态表现概率B的乘积.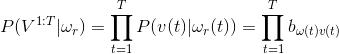
但是问题又出现了,刚才那个隐性状态序列是我假设的,而实际的序列我不知道,这该怎么办。好办,把所有可能出现的隐状态序列组合全都试一遍就可以了。
链接:https://www.zhihu.com/question/20962240/answer/64187492
问题1,已知整个模型,我女朋友告诉我,连续三天,她下班后做的事情分别是:散步,购物,收拾。那么,根据模型,计算产生这些行为的概率是多少。
问题2,同样知晓这个模型,同样是这三件事,我女朋友要我猜,这三天她下班后北京的天气是怎么样的。这三天怎么样的天气才最有可能让她做这样的事情。
问题3,最复杂的,我女朋友只告诉我这三天她分别做了这三件事,而其他什么信息我都没有。她要我建立一个模型,晴雨转换概率,第一天天气情况的概率分布,根据天气情况她选择做某事的概率分布。(惨绝人寰)
而要解决这些问题,伟大的大师们分别找出了对应的算法。
- 问题一,Forward Algorithm,向前算法,或者 Backward Algo,向后算法。
- 问题二,Viterbi Algo,维特比算法。
- 问题三,Baum-Welch Algo,鲍姆-韦尔奇算法。
问题1的“Sol 1”:遍历算法(穷举)。要计算产生这一系列行为的概率,那我们把每一种天气情况下产生这些行为都罗列出来,那每种情况的和就是这个概率。有三天,每天有两种可能的天气情况,则总共有

种情况.
举例其中一种情况 :
P(下雨,下雨,下雨,散步,购物,收拾)
=P(第一天下雨)P(第一天下雨去散步)P(第二天接着下雨)P(下雨去购物)P(第三天还下雨)P(下雨回家收拾)
=0.6X0.1X0.7X0.4X0.7X0.5
=0.00588
//就是:一系列行为同时发生的概率
当然,这里面的 P(第二天接着下雨)当然是已知第一天下雨的情况下,第二天下雨的概率,为0.7.
将八种情况相加可得,三天的行为是{散步,购物,收拾}的可能性为0.033612.
看似简单易计算,但是一旦观察序列变长,计算量就会非常庞大(

的复杂度,T 为观测序列的长度)。
问题1 的"Sol2":向前算法。
先计算 t=1时刻,发生『散步』一行为的概率,如果下雨,则为:
P(散步,下雨)
=P(第一天下雨)X P(散步 | 下雨)
=0.6X0.1=0.06;晴天,
P(散步,晴天)
=0.4X0.6=0.24
t=2 时刻,发生『购物』的概率,当然,这个概率可以从 t=1 时刻计算而来。如下:
如果t=2下雨,则
P(第一天散步,第二天购物, 第二天下雨)
= 【P(第一天散步,第一天下雨)X P(第二天下雨 | 第一天下雨)+P(第一天散步,第一天晴天)X P(第二天下雨 | 第一天晴天)】X P(第二天购物 | 第二天下雨)
=【0.06X0.7+0.24X0.3】X0.4
=0.0552
如果 t=2晴天,则
P(第一天散步,第二天购物,第二天晴天)
=0.0486 (同理可得,请自行推理)
如果 t=3,下雨,则
P(第一天散步,第二天购物,第三天收拾,第三天下雨)
=【P(第一天散步,第二天购物,第二天下雨)X P(第三天下雨 | 第二天下雨)+ P(第一天散步,第二天购物,第二天天晴)X P(第三天下雨 | 第二天天晴)】X P(第三天收拾 | 第三天下雨)
=【0.0552X0.7+0.0486X0.4】X0.5
= 0.02904
如果t=3,晴天,则
P(第一天散步,第二天购物,第三天收拾,第三天晴天)
= 0.004572
那么 P(第一天散步,第二天购物,第三天收拾),这一概率则是第三天,下雨和晴天两种情况的概率和。
0.02904+0.004572=0.033612.
以上例子可以看出,向前算法计算了每个时间点时,每个状态的发生观测序列的概率,看似繁杂,但在 T 变大时,复杂度会大大降低。
问题1的"Sol3":向后算法
顾名思义,向前算法是在时间 t=1的时候,一步一步往前计算。而相反的,向后算法则是倒退着,从最后一个状态开始,慢慢往后推。
初始化: (第一次使用知乎的公式编辑,还蛮靠谱的嘛)
(第一次使用知乎的公式编辑,还蛮靠谱的嘛)

递推:
=0,.7x0.5x1+0.3x0.1x1=0.38
其中第一项则是转移概率,第二天下雨转到第三天下雨的概率为0.7;第二项则是观测概率,第三天下雨的状况下,在家收拾的概率为0.5;第三项就是我们定义的向后变量(backward variable)。
同理推得
结束:P(散步,购物,收拾) = =0.6×0.1×0.1298+0.4×0.6×0.1076
=0.6×0.1×0.1298+0.4×0.6×0.1076
=0.033612
<img src="https://pic3.zhimg.com/1a89bf925b4c1af2cc17416764d1d60e_b.png" data-rawwidth="340" data-rawheight="295" class="content_image" width="340">
三种算法的答案是一致的。
问题2的解决:维特比算法
维特比算法致力于寻找一条最佳路径,以便能最好地解释观测到的序列。
初始化:
初始路径:
递推,当然是要找出概率比较大的那条路径。

那么,到达第二天下雨这一状态的最佳路径,应该是:

也就是说,第一天是晴天的可能性更大。
同样地,可以推得,
结束:比较 的大小,发现前者较大,则最后一天的状态最有可能是 下雨天。
的大小,发现前者较大,则最后一天的状态最有可能是 下雨天。
回推:根据 可知,到达第三天下雨这一状态,最有可能是第二天也下雨,再根据
可知,到达第三天下雨这一状态,最有可能是第二天也下雨,再根据 可知,到达第二天下雨这一状态,最有可能是第一天是晴天。
可知,到达第二天下雨这一状态,最有可能是第一天是晴天。
由此,我们得到了最佳路径,即,晴天,雨天,雨天。
问题3的解决:Baum-Welch 算法。
此问题的复杂度要远远高于前两种算法,不是简单解释就能说的清楚的了。若有兴趣,可以私信我。
我非常赞同霍金老头的『多一个公式,少十个读者』的说法,但是自己写起来,却发现用英文的这些公式好像比中文更简洁易懂,中文好像更罗里吧嗦一些。
依然怀着非常感恩的心,再次感谢这个问题以及回答问题的这些热心的人们给我带来的帮助。
[Math] Hidden Markov Model
标签:购物 技术 最好 img oba 递推 之间 pre viterbi
原文地址:http://www.cnblogs.com/jesse123/p/5870956.html