标签:context http 溢出 对象 返回 time 默认值 code 配置
正在学习storm的大兄弟们,我又来传道授业解惑了,是不是觉得自己会用ack了。好吧,那就让我开始啪啪打你们脸吧。
先说一下ACK机制:
为了保证数据能正确的被处理, 对于spout产生的每一个tuple, storm都会进行跟踪。
这里面涉及到ack/fail的处理,如果一个tuple处理成功是指这个Tuple以及这个Tuple产生的所有Tuple都被成功处理, 会调用spout的ack方法;
如果失败是指这个Tuple或这个Tuple产生的所有Tuple中的某一个tuple处理失败, 则会调用spout的fail方法;
在处理tuple的每一个bolt都会通过OutputCollector来告知storm, 当前bolt处理是否成功。
另外需要注意的,当spout触发fail动作时,不会自动重发失败的tuple,需要我们在spout中重新获取发送失败数据,手动重新再发送一次。
Ack原理
Storm中有个特殊的task名叫acker,他们负责跟踪spout发出的每一个Tuple的Tuple树(因为一个tuple通过spout发出了,经过每一个bolt处理后,会生成一个新的tuple发送出去)。当acker(框架自启动的task)发现一个Tuple树已经处理完成了,它会发送一个消息给产生这个Tuple的那个task。
Acker的跟踪算法是Storm的主要突破之一,对任意大的一个Tuple树,它只需要恒定的20字节就可以进行跟踪。
Acker跟踪算法的原理:acker对于每个spout-tuple保存一个ack-val的校验值,它的初始值是0,然后每发射一个Tuple或Ack一个Tuple时,这个Tuple的id就要跟这个校验值异或一下,并且把得到的值更新为ack-val的新值。那么假设每个发射出去的Tuple都被ack了,那么最后ack-val的值就一定是0。Acker就根据ack-val是否为0来判断是否完全处理,如果为0则认为已完全处理。
要实现ack机制:
1,spout发射tuple的时候指定messageId
2,spout要重写BaseRichSpout的fail和ack方法
3,spout对发射的tuple进行缓存(否则spout的fail方法收到acker发来的messsageId,spout也无法获取到发送失败的数据进行重发),看看系统提供的接口,只有msgId这个参数,这里的设计不合理,其实在系统里是有cache整个msg的,只给用户一个messageid,用户如何取得原来的msg貌似需要自己cache,然后用这个msgId去查询,太坑爹了
3,spout根据messageId对于ack的tuple则从缓存队列中删除,对于fail的tuple可以选择重发。
4,设置acker数至少大于0;Config.setNumAckers(conf, ackerParal);
题外话:
阿里自己的Jstorm会提供
public interface IFailValueSpout { void fail(Object msgId, List<object>values); }
这样更合理一些, 可以直接取得系统cache的msg values
Storm的Bolt有BsicBolt和RichBolt:
在BasicBolt中,BasicOutputCollector在emit数据的时候,会自动和输入的tuple相关联,而在execute方法结束的时候那个输入tuple会被自动ack。
使用RichBolt需要在emit数据的时候,显示指定该数据的源tuple要加上第二个参数anchor tuple,以保持tracker链路,即collector.emit(oldTuple, newTuple);并且需要在execute执行成功后调用OutputCollector.ack(tuple), 当失败处理时,执行OutputCollector.fail(tuple);
由一个tuple产生一个新的tuple称为:anchoring,你发射一个tuple的同时也就完成了一次anchoring。
ack机制即,spout发送的每一条消息,
在规定的时间内,spout收到Acker的ack响应,即认为该tuple 被后续bolt成功处理
在规定的时间内(默认是30秒),没有收到Acker的ack响应tuple,就触发fail动作,即认为该tuple处理失败,timeout时间可以通过Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS来设定。
或者收到Acker发送的fail响应tuple,也认为失败,触发fail动作
注意,我开始以为如果继承BaseBasicBolt那么程序抛出异常,也会让spout进行重发,但是我错了,程序直接异常停止了
这里我以分布式程序入门案例worldcount为例子吧。
请看下面大屏幕:没有错我就是那个你们走在路上经常听见的名字刘洋。
这里我以分布式程序入门案例worldcount为例子吧。
请看下面大屏幕:没有错我就是那个你们走在路上经常听见的名字刘洋。
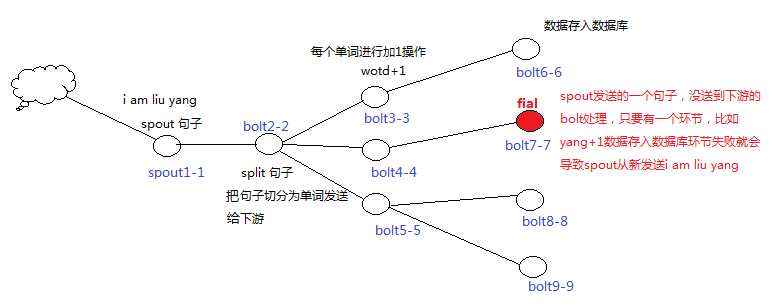
这里spout1-1task发送句子"i am liu yang"给bolt2-2task进行处理,该task把句子切分为单词,根据字段分发到下一个bolt中,bolt2-2,bolt4-4,bolt5-5对每一个单词添加一个后缀1后再发送给下一个bolt进行存储到数据库的操作,这个时候bolt7-7task在存储数据到数据库时失败,向spout发送fail响应,这个时候spout收到消息就会再次发送的该数据。
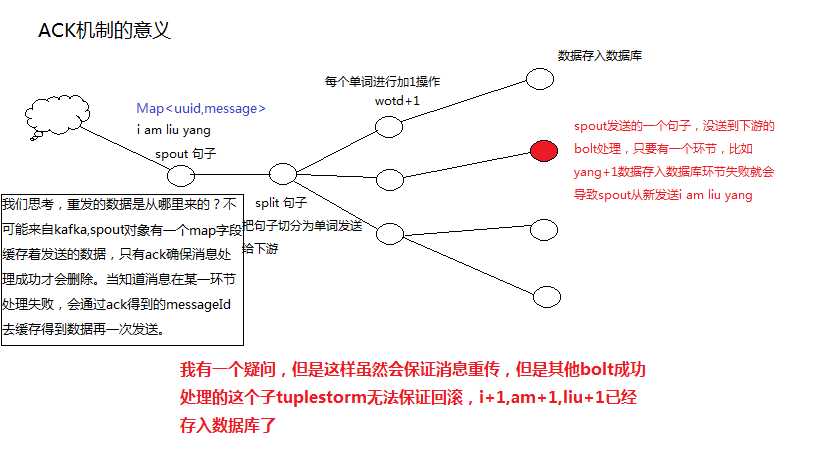
好,那么我思考一个问题:spout如何保证再次发送的数据就是之前失败的数据,所以在spout实例中,绝对要定义一个map缓存,缓存发出去的每一条数据,key当然就是messageId,当spout实例收到所有bolt的响应后如果是ack,就会调用我们重写的ack方法,在这个方法里面我们就要根据messageId删除这个key-value,如果spout实例收到所有bolt响应后,发现是faile,则会调用我们重写的fail方法,根据messageId查询到对应的数据再次发送该数据出去。
spout代码如下

public class MySpout extends BaseRichSpout {
private static final long serialVersionUID = 5028304756439810609L;
// key:messageId,Data
private HashMap<String, String> waitAck = new HashMap<String, String>();
private SpoutOutputCollector collector;
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sentence"));
}
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
public void nextTuple() {
String sentence = "i am liu yang";
String messageId = UUID.randomUUID().toString().replaceAll("-", "");
waitAck.put(messageId, sentence);
//指定messageId,开启ackfail机制
collector.emit(new Values(sentence), messageId);
}
@Override
public void ack(Object msgId) {
System.out.println("消息处理成功:" + msgId);
System.out.println("删除缓存中的数据...");
waitAck.remove(msgId);
}
@Override
public void fail(Object msgId) {
System.out.println("消息处理失败:" + msgId);
System.out.println("重新发送失败的信息...");
//重发如果不开启ackfail机制,那么spout的map对象中的该数据不会被删除的。
collector.emit(new Values(waitAck.get(msgId)),msgId);
}
}
虽然在storm项目中我们的spout源通常来源kafka,而且我们使用storm提供的工具类KafkaSpout类,其实这个类里面就维护者<messageId,Tuple>对的集合。
问题一:你们有没有想过如果某一个task节点处理的tuple一直失败,消息一直重发会怎么样?
我们都知道,spout作为消息的发送源,在没有收到该tuple来至左右bolt的返回信息前,是不会删除的,那么如果消息一直失败,就会导致spout节点存储的tuple数据越来越多,导致内存溢出。
问题二:有没有想过,如果该tuple的众多子tuple中,某一个子tuple处理failed了,但是另外的子tuple仍然会继续执行,如果子tuple都是执行数据存储操作,那么就算整个消息失败,那些生成的子tuple还是会成功执行而不会回滚的。
问题三:tuple的追踪并不一定要是从spout结点到最后一个bolt,只要是spout开始,可以在任意层次bolt停止追踪做出应答。
Acker task 组件来设置一个topology里面的acker的数量,默认值是一,如果你的topoogy里面的tuple比较多的话,那么请把acker的数量设置多一点,效率会更高一点。
有三种方法可以去掉消息的可靠性:
将参数Config.TOPOLOGY_ACKERS设置为0,通过此方法,当Spout发送一个消息的时候,它的ack方法将立刻被调用;
Spout发送一个消息时,不指定此消息的messageID。当需要关闭特定消息可靠性的时候,可以使用此方法;
最后,如果你不在意某个消息派生出来的子孙消息的可靠性,则此消息派生出来的子消息在发送时不要做锚定,即在emit方法中不指定输入消息。因为这些子孙消息没有被锚定在任何tuple tree中,因此他们的失败不会引起任何spout重新发送消息。
有2种途径
spout发送数据是不带上msgid
设置acker数等于0
值得注意的一点是Storm调用Ack或者fail的task始终是产生这个tuple的那个task,所以如果一个Spout,被分为很多个task来执行,消息执行的成功失败与否始终会通知最开始发出tuple的那个task。
作为Storm的使用者,有两件事情要做以更好的利用Storm的可靠性特征,首先你在生成一个tuple的时候要通知Storm,其次,完全处理一个tuple之后要通知Storm,这样Storm就可以检测到整个tuple树有没有完成处理,并且通知源Spout处理结果。
1 由于对应的task挂掉了,一个tuple没有被Ack:
Storm的超时机制在超时之后会把这个tuple标记为失败,从而可以重新处理。
2 Acker挂掉了: 在这种情况下,由这个Acker所跟踪的所有spout tuple都会出现超时,也会被重新的处理。
3 Spout 挂掉了:在这种情况下给Spout发送消息的消息源负责重新发送这些消息。
三个基本的机制,保证了Storm的完全分布式,可伸缩的并且高度容错的。
另外Ack机制还常用于限流作用: 为了避免spout发送数据太快,而bolt处理太慢,常常设置pending数,当spout有等于或超过pending数的tuple没有收到ack或fail响应时,跳过执行nextTuple, 从而限制spout发送数据。
通过conf.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, pending);设置spout pend数。
标签:context http 溢出 对象 返回 time 默认值 code 配置
原文地址:http://www.cnblogs.com/thinkpad/p/6008935.html