标签:net and 物理内存 文档 交互 img hugepage 计算 包头
该文档是随着对于文档的阅读进度,不断增加的阅读笔记。主要内容以大纲为主,以及记录帮助记忆的内容。
在之后的实际应用中,也不随着不断的深入理解,逐渐丰富各大纲下面的内容。
1. 前期准备:设置两个环境变量。
export RTE_SDK=/home/user/DPDK
export RTE_TARGET=x86_64-native-linuxapp-gcc
2. dpdk提供的环境抽象层:
2.1 DPDK程序运行在用户态,同时使用用户态 PCI 驱动 UIO,使用mmap将设备内存映射入用户态。
2.2 使用大页内存。
基于大页内存,可以在应用程序中,完成大页内存的申请分配与预留。
XEN dom0 不支持大页,需要使用 rte_dom0_mm 详见文档
需要进一步详细跟紧和了解的技术细节:TSC(CPU Time-Stamp Counter),HPET kernel API, mmap
2.3 初始化流程,多核心调度与处理。
初始化过程中的资源分配是线程不安全的。但是初始化完成之后,资源便可以在各线程中安全的同时使用了。
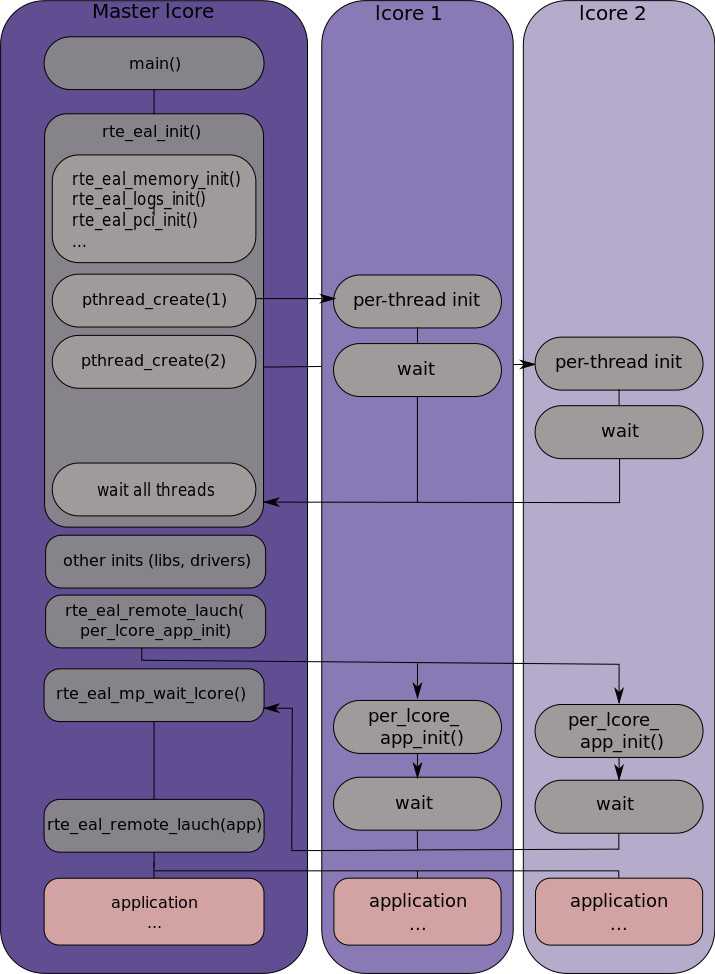
2.4 除了多线程,还支持多进程。
2.5 提供程序日志API,可以替换系统syslog和console日志,用于程序的日志输出。
rte_panic 用于调试
2.6 用户态网卡中断响应
突然莫名冒出来个缩写 DPDK PMD。 PMD是啥?
2.7 Memory Segments and Memory Zones
为每一个文件描述符分配连续的内存空间,并按照cache line size 或 hugepage 对齐。
2.8 多线程
每个core只绑定一个pthread
控制电源管理,开启最大性能。
控制单核内多线程上下文切换。
2.9 cgroup control 不懂啊,学啊
原文档例:
mkdir /sys/fs/cgroup/cpu/pkt_io mkdir /sys/fs/cgroup/cpuset/pkt_io echo $cpu > /sys/fs/cgroup/cpuset/cpuset.cpus echo $t0 > /sys/fs/cgroup/cpu/pkt_io/tasks echo $t0 > /sys/fs/cgroup/cpuset/pkt_io/tasks echo $t1 > /sys/fs/cgroup/cpu/pkt_io/tasks echo $t1 > /sys/fs/cgroup/cpuset/pkt_io/tasks cd /sys/fs/cgroup/cpu/pkt_io echo 100000 > pkt_io/cpu.cfs_period_us echo 50000 > pkt_io/cpu.cfs_quota_us
2.10 Malloc
dpdk提供类似系统调用的malloc函数 rte_malloc(), 一般在程序运行过程中,这个malloc会比基于pool的malloc慢很多,且有锁。 可以在配置相关的代码中使用,而不要的数据处理的单代码中使用。
内存大小使用2的幂将支持自动对齐,并且会基于numa优化,在对应node中分配。但是并不保证一定在这个node上?!?!?!(没看懂,请参见原文档,并欢迎联系我指导我)
2.10.1 内部数据结构 malloc_heap
很简单,一个链表指向所有未分配的内存。已使用的内存在free()时会被重新联入链表。
2.10.2 内部数据结构 malloc_elem
使用场景一:作为所有内存块(分配/未分配)的头。
使用场景二:padding header
使用场景三:end of memseg marker
3. 核心组件:
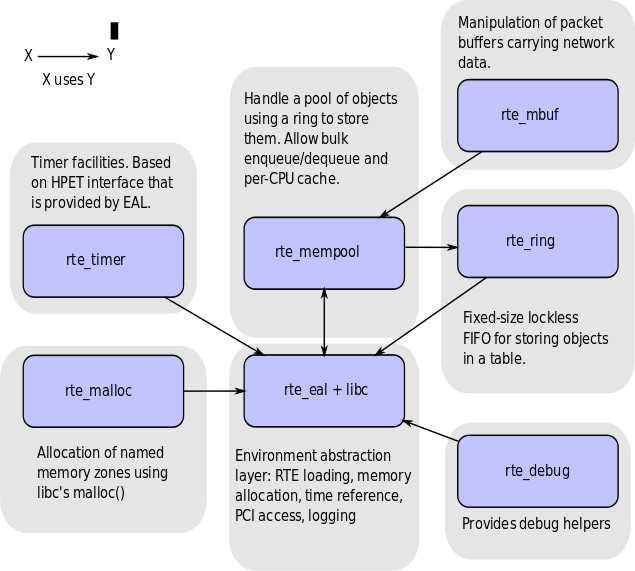
3.1 librte_ring 多读多写的无锁队列结构。可以被 librte_mempool 所使用。
无优先级概念,任何入队(出队)操作都不比其他入队(出队)操作拥有更高的优先级。
3.2 librte_mempool 内存对象池,提供cpu cache对齐,内存对齐等能力。
3.3 librte_mbuf 内存申请释放管理。
3.4 librte_timer 就是timer呗
3.5 网卡驱动,论询方式,不使用异步中断。
3.6 包转发算法,Hash LPM(Longest Profix Match)
3.7 librte_net 协议栈,包头结构等。
4. RING LIBRARY
The advantages of this data structure over a linked list queue are as follows:
The disadvantages:
其他特点:
1. 使用唯一的名字标示。
2. 水位警戒线,超过警戒线,调用者会被告知。
3. debug调试。基于单核的计数信息。
使用场景:
1. 应用程序间通信交互。
2. 由 mempool allocate。
操作原理(无锁原理):
略。有一本书<<深入浅出dpdk>>,已读过,补充了CPU等知识后,记得回来复看。
补充阅读:
http://lwn.net/Articles/340400/
5. Mempool Library
A memory pool is an allocator of a fixed-sized object。 默认使用 rte_ring, 言外之意也可以用别的。还提供其他功能:a per-core object cache and an alignment helper to ensure that objects are padded to spread them equally on all DRAM or DDR3 channels.
5.1 支持debug功能,提供基于core的计数。
5.2 内存对齐
命令行指定 channel数,rank数?
5.3 local cache
compare-and-set (CAS) operation. CPU指令?
5.4 Mempool handlers
使用外部的内存管理系统,代替dpdk。
6. Mbuf Library
提供内存的alloc和free能力。
6.1 Packet Buffers
一种已经设计好的,用于存储网络包的内存数据结构。
6.2 Meta information
内存中会存储各种包内容相关的信息。值得一提的时发包的时候,可以将一部分内容委派给网卡进行硬件计算。
6.3 Direct and Indirect buffers
简单理解indirect buffer 是对 Dierct buffer的引用。通过特定的API,进行引用的创建和传递。
6.4 Debug
Mbuf相关的操作都会开启严格的检验,严格类型,脏数据等。
(未完待续。。。)
标签:net and 物理内存 文档 交互 img hugepage 计算 包头
原文地址:http://www.cnblogs.com/hugetong/p/6007232.html