标签:大致 work nod shared bsp 理论 指定 tool 之间
本文将介绍HA机制的原理,以及Hadoop2 HA配置过程。
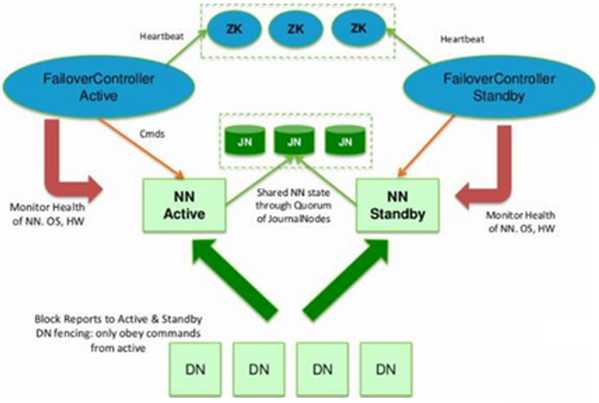
Hadoop2体系结构
Hadoop2的出现是有原因的。我们知道 NameNode是核心节点,维护着整个HDFS中的元数据信息,那么其容量是有限的,受制于服务器的内存空间。当NameNode服务器的内存装不下数据后,那么HDFS集群就装不下数据了,寿命也就到头了。因此其扩展性是受限的。HDFS联盟指的是有多个HDFS集群同时工作,那么其容量理论上就不受限了,夸张点说就是无限扩展。你可以理解成,一个总集群中,可以虚拟出两个或两个以上的单独的小集群,各个小集群之间数据是实时共享的。因为hadoop集群中已经不在单独存在namenode和datanode的概念。当一个其中一个小集群出故障,可以启动另一个小集群中的namenode节点,继续工作。因为数据是实时共享,即使namenode或datanode一起死掉,也不会影响整个集群的正常工作。
Hadoop2 HA配置
1. 文件hdfs-site.xml
1 <configuration> 2 <property> 3 <name>dfs.replication</name> 4 <value>2</value> 5 </property> // 指定DataNode存储block的副本数量 6 <property> 7 <name>dfs.permissions</name> 8 <value>false</value> 9 </property> 10 <property> 11 <name>dfs.permissions.enabled</name> 12 <value>false</value> 13 </property> 14 <property> 15 <name>dfs.nameservices</name> 16 <value>cluster1</value> 17 </property> //给hdfs集群起名字 18 <property> 19 <name>dfs.ha.namenodes.cluster1</name> 20 <value>hadoop1,hadoop2</value> 21 </property> //指定NameService是cluster1时的namenode 22 <property> 23 <name>dfs.namenode.rpc-address.cluster1.hadoop1</name> 24 <value>hadoop1:9000</value> 25 </property> //指定hadoop101的RPC地址 26 <property> 27 <name>dfs.namenode.http-address.cluster1.hadoop1</name> 28 <value>hadoop1:50070</value> 29 </property> //指定hadoop101的http地址 30 <property> 31 <name>dfs.namenode.rpc-address.cluster1.hadoop2</name> 32 <value>hadoop2:9000</value> 33 </property> 34 <property> 35 <name>dfs.namenode.http-address.cluster1.hadoop2</name> 36 <value>hadoop2:50070</value> 37 </property> 38 <property> 39 <name>dfs.namenode.servicerpc-address.cluster1.hadoop1</name> 40 <value>hadoop1:53310</value> 41 </property> 42 <property> 43 <name>dfs.namenode.servicerpc-address.cluster1.hadoop2</name> 44 <value>hadoop2:53310</value> 45 </property> 46 <property> 47 <name>dfs.ha.automatic-failover.enabled.cluster1</name> 48 <value>true</value> 49 </property> //指定cluster1是否启动自动故障恢复 50 <property> 51 <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485;hadoop4:8485;hadoop5:8485/cluster1</value> 52 </property> //指定cluster1的两个NameNode共享edits文件目录时,使用的JournalNode集群信息 53 <property> 54 <name>dfs.client.failover.proxy.provider.cluster1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> 55 </property> //指定cluster1出故障时,哪个实现类负责执行故障切换 56 <property> 57 <name>dfs.journalnode.edits.dir</name> 58 <value>/home/muzili/yarn/yarn_data/tmp/journal</value> 59 </property> //指定JournalNode集群在对NameNode的目录进行共享时,自己存储数据的磁盘路径 60 <property> 61 <name>dfs.ha.fencing.methods</name> 62 <value>sshfence</value> 63 </property> 64 <property> 65 <name>dfs.ha.fencing.ssh.private-key-files</name> 66 <value>/home/muzili/.ssh/id_rsa</value> 67 </property> 68 <property> 69 <name>dfs.ha.fencing.ssh.connect-timeout</name> 70 <value>10000</value> 71 </property> 72 <property> 73 <name>dfs.namenode.handler.count</name> 74 <value>100</value> 75 </property> 76 </configuration>
2. 文件mapred-site.xml
1 <configuration> 2 <property> 3 <name>mapreduce.framework.name</name> 4 <value>yarn</value> 5 </property> 6 </configuration> //指定运行mapreduce的环境是yarn,与hadoop1不同的地方
3. 文件yarn-site.xml
1 <configuration> 2 <property> 3 <name>yarn.resourcemanager.hostname</name> 4 <value>hadoop1</value> 5 </property> //自定义ResourceManager的地址,还是单点 6 <property> 7 <name>yarn.nodemanager.aux-services</name> 8 <value>mapreduce.shuffle</value> 9 </property> 10 </configuration>
环境变量的添加方法大致相同,以下配置仅供参考
JAVA_HOME=/usr/lib/jvm/jdk1.7.0_51
export PATH=$PATH:$JAVA_HOME/bin
export HBASE_HOME=/home/muzili/hadoop-2.2.0/app/hbase-0.94.6-cdh4.4.0
export HIVE_HOME=/home/muzili/hadoop-2.2.0/app/hive-0.12.0/
export HADOOP_HOME=/home/muzili/hadoop-2.2.0
export PATH=$PATH:$HBASE_HOME/bin:$HIVE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
export ZOOKEEPER_HOME=/home/muzili/yarn/hadoop-2.2.0/app/zookeeper-3.4.5
export PATH=$PATH:$ZOOKEEPER_HOME/bin
总结
HA通过引入Standby Namenode,解决了Hadoop1上HDFS单点故障。如果读者有兴趣的话,可以参考博客,进行HA的配置安装。
标签:大致 work nod shared bsp 理论 指定 tool 之间
原文地址:http://www.cnblogs.com/muzili-ykt/p/6009312.html