标签:简单 规模 .bashrc 总结 exec 跟踪 aging www shuffle
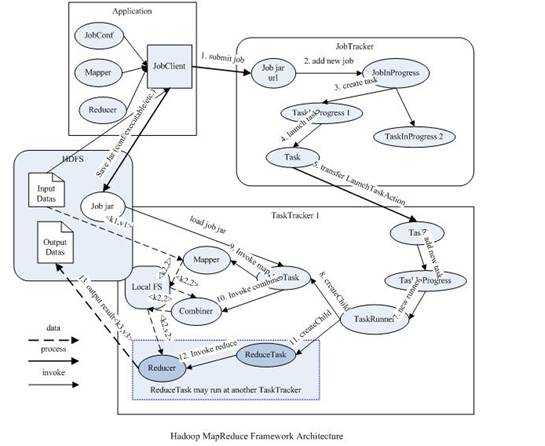
原hadoop的MapReduce框架图
从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路:
可以看得出原来的 map-reduce 架构是简单明了的,在最初推出的几年,也得到了众多的成功案例,获得业界广泛的支持和肯定,但随着分布式系统集群的规模和其工作负荷的增长,原框架的问题逐渐浮出水面,主要的问题集中如下:
从业界使用分布式系统的变化趋势和 hadoop 框架的长远发展来看,MapReduce 的 JobTracker/TaskTracker 机制需要大规模的调整来修复它在可扩展性,内存消耗,线程模型,可靠性和性能上的缺陷。在过去的几年中,hadoop 开发团队做了一些 bug 的修复,但是最近这些修复的成本越来越高,这表明对原框架做出改变的难度越来越大。
为从根本上解决旧 MapReduce 框架的性能瓶颈,促进 Hadoop 框架的更长远发展,从 0.23.0 版本开始,Hadoop 的 MapReduce 框架完全重构,发生了根本的变化。新的Hadoop MapReduce 框架命名为 MapReduceV2 或者叫 Yarn,其架构图如下图所示:
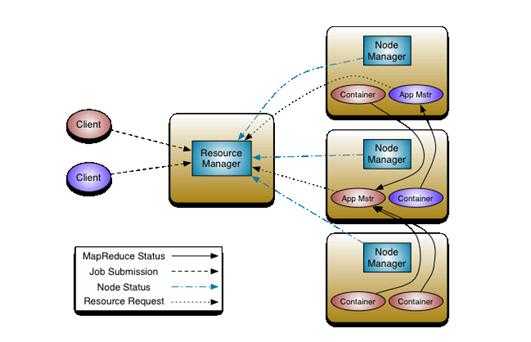
重构根本的思想是将 JobTracker 两个主要的功能分离成单独的组件,这两个功能是资源管理(ResourceManager)和任务调度 / 监控。新的资源管理器全局管理所有应用程序计算资源的分配,每一个应用的 ApplicationMaster 负责相应的调度和协调。一个应用程序无非是一个单独的传统的 MapReduce job或者是一个 DAG( 有向无环图 ) job。ResourceManager 和每一台机器的节点管理服务器(NodeManager)能够管理用户在那台机器上的进程并能对计算进行组织。
ResourceManager协调集群的资源利用,任何client或者运行着的applicatitonMaster想要运行job或者task都得向RM申请一定的资源。ApplicatonMaster是一个框架特殊的库,对于MapReduce框架而言有它自己的AM实现,用户也可以实现自己的AM,在运行的时候,AM结合从 ResourceManager 获得的资源与NM一起来启动和监视tasks。
ResourceManager作为资源的协调者有两个主要的组件:Scheduler和ApplicationsManager(AsM)。
Scheduler负责分配最少但满足application运行所需的资源量给Application。Scheduler只是基于应用程序资源的使用情况进行调度,资源包括:内存,CPU,磁盘,网络等等,可以看出,这同现 Mapreduce 固定类型的资源使用模型有显著区别,它给集群的使用带来负面的影响。从某种意义上讲它就是一个纯粹的调度器,并不负责监视/跟踪application的状态,当然也不会处理失败的task。RM使用resource container概念来管理集群的资源,每一个应用程序需要不同类型的资源因此就需要不同的容器。resource container是资源的抽象,每个container包括一定的内存、IO、网络等资源,不过目前的实现只包括内存一种资源。ResourceManager 提供一个调度策略的插件,它负责将集群资源分配给多个队列和应用程序。调度插件可以基于现有的能力调度和公平调度模型。 ResourceManager 支持分层级的应用队列,这些队列享有集群一定比例的资源。
ApplicationsManager(AsM)负责处理client提交的job以及协商第一个container以供applicationMaster运行,并且在applicationMaster失败的时候会重新启动applicationMaster。下面阐述RM具体完成的一些功能。
4. AM的生命周期:AsM负责系统中所有AM的生命周期的管理。AsM负责AM的启动,当AM启动后,AM会周期性的向AsM发送heartbeat,默认是1s,AsM据此了解AM的存活情况,并且在AM失败时负责重启AM,若是一定时间过后(默认10分钟)没有收到AM的heartbeat,AsM就认为该AM失败了。
NM是每一台机器框架的代理,主要负责启动RM分配给AM的container以及代表AM的container,并且会监视container的运行情况。在启动container的时候,NM会设置一些必要的环境变量以及将container运行所需的jar包、文件等从hdfs下载到本地,也就是所谓的资源本地化;当所有准备工作做好后,才会启动代表该container的脚本将程序启动起来。启动起来后,NM会周期性的监视该container运行占用的资源情况 (CPU,内存,硬盘,网络 ) 并且向调度器汇报,若是超过了该container所声明的资源量,则会kill掉该container所代表的进程。
另外,NM还提供了一个简单的服务以管理它所在机器的本地目录。Applications可以继续访问本地目录即使那台机器上已经没有了属于它的container在运行。例如,Map-Reduce应用程序使用这个服务存储map output并且shuffle它们给相应的reduce task。
在NM上还可以扩展自己的服务,yarn提供了一个yarn.nodemanager.aux-services的配置项,通过该配置,用户可以自定义一些服务,例如Map-Reduce的shuffle功能就是采用这种方式实现的。
NM在本地为每个运行着的application生成如下的目录结构:

Container目录下的目录结构如下:

在启动一个container的时候,NM就执行该container的default_container_executor.sh,该脚本内部会执行launch_container.sh。launch_container.sh会先设置一些环境变量,最后启动执行程序的命令。对于MapReduce而言,启动AM就执行org.apache.hadoop.mapreduce.v2.app.MRAppMaster;启动map/reduce task就执行org.apache.hadoop.mapred.YarnChild。
ApplicationMaster是一个框架特殊的库,每一个应用的 ApplicationMaster 的职责有:向调度器索要适当的资源容器,运行任务,跟踪应用程序的状态和监控它们的进程,处理任务的失败原因。
对于Map-Reduce计算模型而言有它自己的ApplicationMaster实现,对于其他的想要运行在yarn上的计算模型而言,必须得实现针对该计算模型的ApplicationMaster用以向RM申请资源运行task,比如运行在yarn上的spark框架也有对应的ApplicationMaster实现,归根结底,yarn是一个资源管理的框架,并不是一个计算框架,要想在yarn上运行应用程序,还得有特定的计算框架的实现。由于yarn是伴随着MRv2一起出现的,所以下面简要概述MRv2在yarn上的运行流程。
在yarn上写应用程序并不同于我们熟知的MapReduce应用程序,必须牢记yarn只是一个资源管理的框架,并不是一个计算框架,计算框架可以运行在yarn上。我们所能做的就是向RM申请container,然后配合NM一起来启动container。就像MRv2一样,jobclient请求用于MR AM运行的container,设置环境变量和启动命令,然后交由NM去启动MR AM,随后map/reduce task就由MR AM全权负责,当然task的启动也是由MR AM向RM申请container,然后配合NM一起来启动的。所以要想在yarn上运行非特定计算框架的程序,我们就得实现自己的client和applicationMaster。另外我们自定义的AM需要放在各个NM的classpath下,因为AM可能运行在任何NM所在的机器上。
让我们来对新旧 MapReduce 框架做详细的分析和对比,可以看到有以下几点显著变化:
首先客户端不变,其调用 API 及接口大部分保持兼容,这也是为了对开发使用者透明化,使其不必对原有代码做大的改变 ( 详见 2.3 Demo 代码开发及详解),但是原框架中核心的 JobTracker 和 TaskTracker 不见了,取而代之的是 ResourceManager, ApplicationMaster 与 NodeManager 三个部分。
我们来详细解释这三个部分,首先 ResourceManager 是一个中心的服务,它做的事情是调度、启动每一个 Job 所属的 ApplicationMaster、另外监控 ApplicationMaster 的存在情况。细心的读者会发现:Job 里面所在的 task 的监控、重启等等内容不见了。这就是 AppMst 存在的原因。ResourceManager 负责作业与资源的调度。接收 JobSubmitter 提交的作业,按照作业的上下文 (Context) 信息,以及从 NodeManager 收集来的状态信息,启动调度过程,分配一个 Container 作为 App Mstr
NodeManager 功能比较专一,就是负责 Container 状态的维护,并向 RM 保持心跳。
ApplicationMaster 负责一个 Job 生命周期内的所有工作,类似老的框架中 JobTracker。但注意每一个 Job(不是每一种)都有一个 ApplicationMaster,它可以运行在 ResourceManager 以外的机器上。
Yarn 框架相对于老的 MapReduce 框架什么优势呢?我们可以看到:
新的 Yarn 框架相对旧 MapRduce 框架而言,其配置文件 , 启停脚本及全局变量等也发生了一些变化,主要的改变如下:
表 1. 新旧 Hadoop 脚本 / 变量 / 位置变化表
| 改变项 | 原框架中 | 新框架中(Yarn) | 备注 |
|---|---|---|---|
| 配置文件位置 | ${hadoop_home_dir}/conf | ${hadoop_home_dir}/etc/hadoop/ | Yarn 框架也兼容老的 ${hadoop_home_dir}/conf 位置配置,启动时会检测是否存在老的 conf 目录,如果存在将加载 conf 目录下的配置,否则加载 etc 下配置 |
| 启停脚本 | ${hadoop_home_dir}/bin/start(stop)-all.sh | ${hadoop_home_dir}/sbin/start(stop)-dfs.sh ${hadoop_home_dir}/bin/start(stop)-all.sh |
新的 Yarn 框架中启动分布式文件系统和启动 Yarn 分离,启动 / 停止分布式文件系统的命令位于 ${hadoop_home_dir}/sbin 目录下,启动 / 停止 Yarn 框架位于 ${hadoop_home_dir}/bin/ 目录下 |
| JAVA_HOME 全局变量 | ${hadoop_home_dir}/bin/start-all.sh 中 | ${hadoop_home_dir}/etc/hadoop/hadoop-env.sh ${hadoop_home_dir}/etc/hadoop/Yarn-env.sh |
Yarn 框架中由于启动 hdfs 分布式文件系统和启动 MapReduce 框架分离,JAVA_HOME 需要在 hadoop-env.sh 和 Yarn-env.sh 中分别配置 |
| HADOOP_LOG_DIR 全局变量 | 不需要配置 | ${hadoop_home_dir}/etc/hadoop/hadoop-env.sh | 老框架在 LOG,conf,tmp 目录等均默认为脚本启动的当前目录下的 log,conf,tmp 子目录 Yarn 新框架中 Log 默认创建在 Hadoop 用户的 home 目录下的 log 子目录,因此最好在 ${hadoop_home_dir}/etc/hadoop/hadoop-env.sh 配置 HADOOP_LOG_DIR,否则有可能会因为你启动 hadoop 的用户的 .bashrc 或者 .bash_profile 中指定了其他的 PATH 变量而造成日志位置混乱,而该位置没有访问权限的话启动过程中会报错 |
由于新的 Yarn 框架与原 Hadoop MapReduce 框架相比变化较大,核心的配置文件中很多项在新框架中已经废弃,而新框架中新增了很多其他配置项,看下表所示会更加清晰:
参考:
更快、更强——解析Hadoop新一代MapReduce框架Yarn
MapReduce和YARN的关系 - Hadoop分布式数据分析平台
hadoop2提交到Yarn: Mapreduce执行过程分析1
标签:简单 规模 .bashrc 总结 exec 跟踪 aging www shuffle
原文地址:http://www.cnblogs.com/wujing-hubei/p/6009849.html