标签:不同的 抽取 32位 驱动器 编译器 通用 一半 距离 2.3
6.1存储技术
6.1.1随机访问存储器(分成两类)
静态RAM(SRAM):快,作为高速缓存存储器。(几百几千兆)
动态RAM(DRAM):作为主存,图形系统的帧缓冲区。(<=几兆)
1.静态RAM
具有双稳定状态,它可以无期限地保持在两个不同的电压配置(状态)其中的一个。也可以保持在亚稳定状态,但这个状态易被干扰。由于它具有双稳定性,所以即使有干扰,当干扰消除时,它能很快地恢复到稳定值。
2.动态RAM
DRAM将每个位存储为对一个电容充电。对干扰非常敏感,电容的电压被干扰之后就永远不会恢复了。
3.传统DRAM
DRAM芯片被分成d个超单元,每个单元w位。用I,j来表示一个超单元。芯片连接到存储控制器电路,一次可以传出(入)w位(即一个超单元的内容)。先传出I(RAS)将第I行所有超单元拷贝到内部缓冲区,再是列地址j(CAS)将(I,j)超单元发送。二维阵列的设计,减少了引脚地址位数,但是两步发送地址增加了访问时间。
4.存储器模块
DRAM芯片包装在存储器模块中,存储器模块是插到主板的拓展槽上的。常见类型:双列直插存储器模块(168引脚,64位为块),单列直插存储器模块(72引脚,32位为块)。将多个存储器模块连接到存储控制器,能够聚合主存。
5.增强的DRAM
6.非易失性存储器
(SRAM,DRAM都是易失性存储器。)
非易失性:断电后不会丢失信息。
ROM:只读存储器(read-only memory)它有的类型既能读也能写,历史原因这样称呼它。
ROM分类:(依据 能被重新编程,写的次数 和 编程所用的机制)
PROM:只能被编程一次。
可擦写可编程ROM(EPROM):被编程105次
闪存:基于EEPROM,为大量的电子设备提供快速持久的非易失性存储。
固件:存储在ROM设备中的程序。
7.访问主存
总线是一组并行的导线,能够携带地址,数据和控制信号。
CPU与主存之间的数据传送:通过总线的共享电子电路在处理器和DRAM主存来回往返。
总线事务:读事务(主存传送数据到CPU,即cpu从主存读)、写事务(CPU传送到主存)
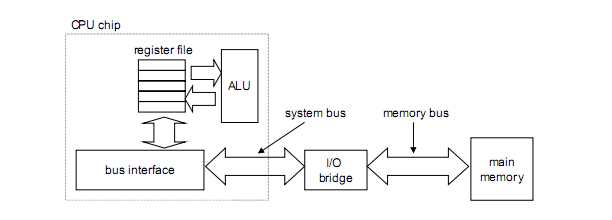
典型的连接CPU和主存的总线结构:
CPU芯片
I/O桥芯片组:存储控制器
主存的DRAM存储器模块
系统总线:连接CPU和I/O桥
存储器总线:连接主存的I/O桥
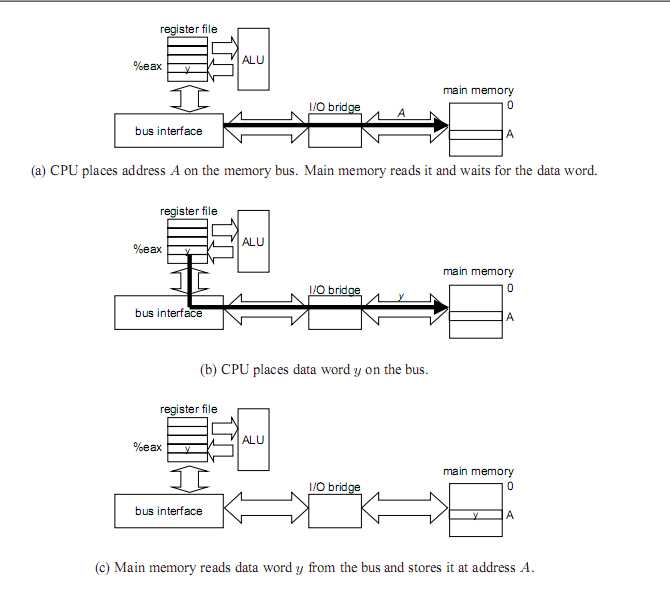
两个例子:movl A,%eax; 和movl %eax,A;
例子1
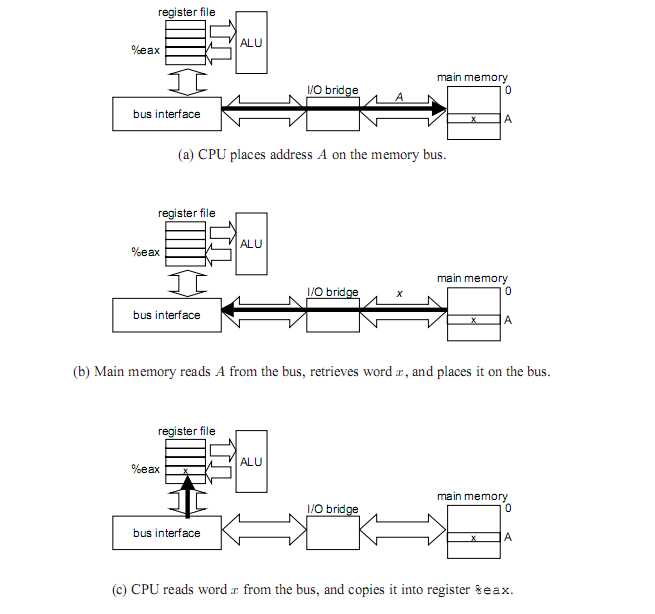
例子2
6.1.2磁盘存储
大,但是慢。DRAM快10万倍,SRAM快100万倍。
1.磁盘构造
磁盘(旋转磁盘)由一个或者多个叠放在一起的盘片组成,封装在一个固定的容器里。盘片有两个表面,盘片中央有一个可以旋转的主轴,固定速度5400~15000转每分钟。整个装置称为磁盘驱动器。
磁道:一个表面从圆心扩散,划分了一组同心圆。
扇区:存储等数量的数据位。
间隙:存储标识扇区的格式化位。
柱面:半径距离相等的磁道的集合。
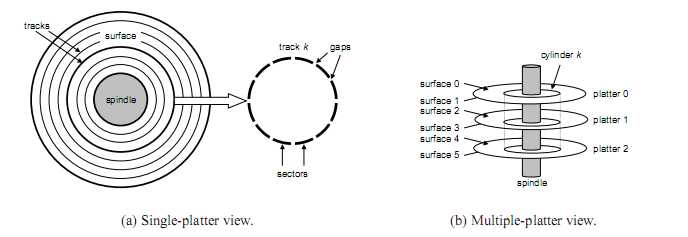
2.磁盘容量
磁盘容量:磁盘最大容量。
磁盘容量=每个扇区字节数*每个磁道平均扇区数*每个表面的磁道数*每个盘面的表面数*磁盘的总盘面数
(注意:DRAM,SRAM容量:K=210,M=220,G=230,T=240
然而磁盘,I/O设备的容量:K=103,,M=106,G=109,T=1012.但是很好一点是,两者对应的值相对差很小。)
3.磁盘操作
寻道时间:读写头定位到磁道上的时间。通常:3~9ms
旋转时间:到了磁道,等待目标扇区的时间。最大旋转延迟:
Tmax rotation=1/RPM * 60secs/1min
平均旋转时间(延迟):最大的一半。
传送时间:驱动器读写内容所花时间。
Tavg transfer=Tmax rotation * 1/每个磁道平均扇区数
计算小结:
时间主要花在寻道和旋转延迟上。
寻道时间和旋转延迟大致相等,一般直接寻道时间*2。
逻辑磁盘块:
磁盘控制器:维护逻辑块号和物理磁盘扇区的映射关系。(读磁盘扇区的数据到主存,磁盘控制器会执行一个快速查找表,将逻辑块号翻译成一个盘面,磁道,扇区的三元组。)
4.连接到i/o设备
通用串行总线(USB)
图形卡(适配器)
主机总线适配器
5.访问磁盘
CPU从磁盘读数据:
6.商用磁盘的剖析
DIXtrac能自动发现大量关于SICI磁盘构造和性能的低级信息。
6.2局部性
局部性原理:程序倾向于引用邻近最近引用过的数据项或者就是数据项本身。
时间局部性:存储器位置多次被引用。
空间局部性:存储器位置附近的位置在不远的将来被引用。
6.2.1对程序数据引用的局部性
步长为一的引用的模式为顺序引用模式。每隔K个元素进行访问,称为步长为K的引用模式。
6.2.2对指令的局部性
循环体具有良好的时间和空间局部性
6.2.3局部性规律总结
重复引用同一个变量的程序具有良好的时间局部性
对于步长为K的引用模式,K越小,空间局部性越好。
对于取指令,循环具有良好的时间和空间局部性。循环体越小,循环迭代次数越多,局部性越好。
6.3存储器层次结构
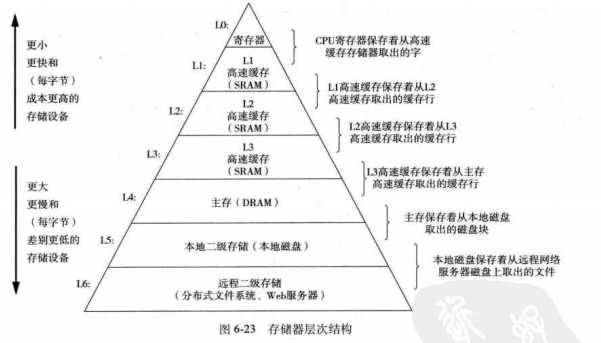
6.3.1存储器层次结构中的缓存
高速缓存:下一层(对它本身来说更大更慢的设备)的缓冲区域。使用高速缓存的过程叫做缓存。
存储器结构层次的中心思想:层次结构中的每一层都缓存来自较低一蹭的数据对象。
块:每一层都被划分成连续的数据对象片。块的大小可以是固定的,也可以是可变大小的。数据总是以块为传送单元。邻近层次的块大小是相同的,其他的可以不同。(例如:L0,L1使用1个字的块,L1,L2使用8~16个字的块)。
1.缓存命中
程序需要K+1层的数据对象d,并且d刚好在K层的一个块中。
2.缓存不命中
与缓存命中相反。
3.缓存不命中的种类
强制性不命中(冷不命中):上一层缓存是空的导致的不命中。
放置策略 :
高层的缓存(靠近CPU)使用的昂贵代价高版:
允许K+1层的任何块放在K层的任何块中
严格版:
K+1层的某个块限制放置在K层的某个块中。
冲突不命中:缓存够大,由于严格的放置策略会使K+1层不同对象映射到K层同一个块引起的不命中。
容量不命中:缓存不够大引起的不命中。
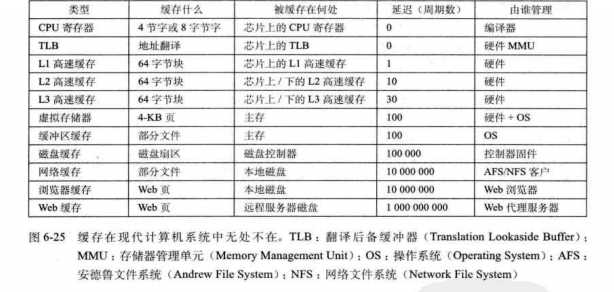
4.缓存管理
L0:编译器
L1,L2,L3:硬件逻辑
L4:操作系统+CPU上的地址翻译硬件
L5:AFS客户端进程
6.4高速缓存存储器
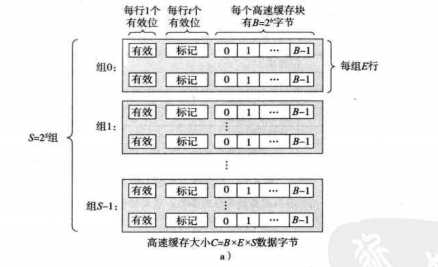
6.4.1通用的高速缓存存储器结构
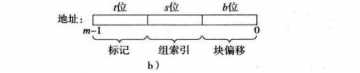
存储器地址:m位
高速缓存组:S=2S位
每组E行高速缓存行
每行1个B=2b字节的数据块
一个有效位:这个行是否有意义
标记位:t=m-(b+s):唯一标识高速缓存行的块
高速缓存大小C=S*E*B
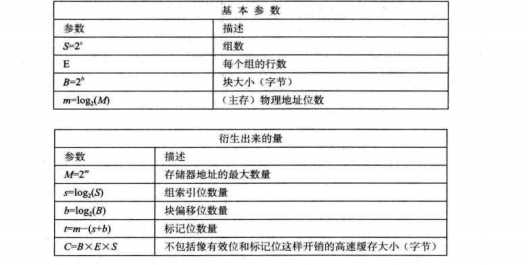
高速缓存的地址:
首先组索引,确定是哪一个组,再是标记位,确定哪一行,最后块偏移。
t位:标记
s位:组索引
b位:块偏移
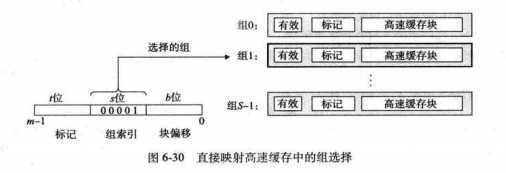
6.4.2直接映射高速缓存
高速缓存的分类依据:每个组的行数。每组一行的高速缓存,称为直接映射高速缓存。
1.直接映射高速缓存中的 组选择
抽取目标地址的对应的S位组索引位。
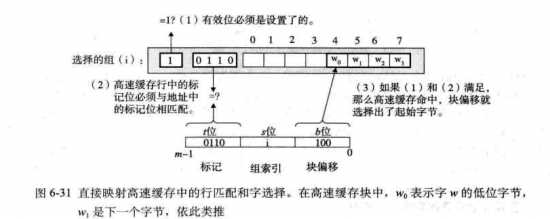
2.直接映射高速缓存中的 行匹配
有效位&&t位标记位和目标地址的标记匹配 同时为真 则命中
不命中时 处理方法:行替换
先从下一层取出被请求的块,再在块中组索引,再行匹配(同时有效的话,就可以确认是这个对象了)。由于直接映射高速缓存每组只有一行,所以只需要将新的行替换当前行就行了。
3.直接映射高速缓存中的 字选择
块偏移提供的是所需要的字的第一个字节的偏移。如例子:
4.综合
描述高速缓存结构:(S,E,B,m)
不同的块被映射到同一组,是靠标记位来区分
以一个例子来理解高速缓存的全过程
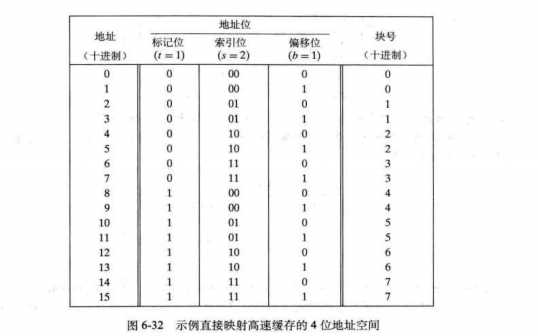
在这个例子中,块0,4映射到组0,;块1,5映射到组1;块2,6映射到组2;块3,7映射到组3。
1) 读地址0:组0还未加载任何内容进来,所以有效位是0.发生强制不命中。高速缓存从下一层取出块0.块0是由地址0和地址1两个部分组成。
2) 读地址1:命中。
3) 读地址13:属于块6,组2.强制不命中,然后读入块6,m[12],m[13].
4) 读地址8:属于块4,组0.冲突不命中,组0替换为m[8],m[9].
5) 读地址0:属于块0,组0,冲突不命中,组0替换为m[0],m[1]
5.直接映射高速缓存中的冲突不命中

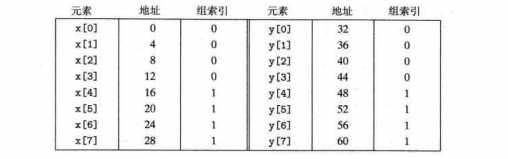
在这个例子中,假设高速缓存只有组0和组1两个组,一个块是16字节(4个数组元素)。
该程序有很好空间局部性,可是还是会引起冲突不命中。(原因是:每个组只有一行这个限制)
第一次迭代应用X[0],组接下来是Y[0].导致冲突不命中。以后的每次饮用都导致冲突不命中。
解决方案,将代码中的X[8]改成X[12],有[8]改成y[12].这样x[i],y[i] 映射在不同的组,解决了问题。这样的方法叫做在数组后放入B字节的填充。
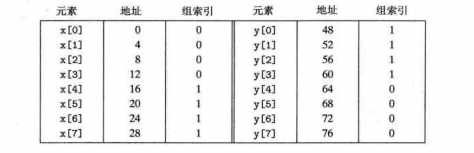
6.4.3组相联高速缓存
由于直接映射高速缓存有冲突不命中的问题,所以放宽了每组只有一行的限制。1<E<C/B的高速缓存称为 组相联高速缓存。
1.组选择(和直接映射高速缓存一样)
2.行匹配和字选择(基本一样,只是多搜索几个行)
3.组相联高速缓存不命中时的行替换
替换哪一行:1.随机替换
2.利用局部性原理,替换被引用概率最小的行(例如最不常使用,最近很少使用的行)
6.4.4全相联高速缓存
只有一个组,这个组里包含所有高速缓存行。
1.组选择。只有一个组,所以没有组索引S=0.地址只有标记和块偏移两部分
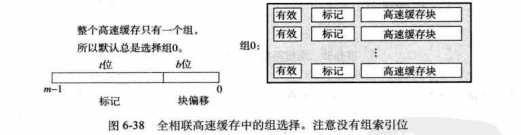
2.行匹配字选择。同组相联高速缓存一样。
本周需要动手操作的部分较少,大部分内容属于识记和理解的知识。对于计算机的存储器层次结构以前就有一些了解但没想到在阅读教材后发现竟然是这么复杂和精细的
一套体系。对于磁盘的这部分内容理解较为容易,因为比较具体,但对于高速缓存是如何工作这部分内容还不是很理解,因为有些抽象。
代码链接:https://git.oschina.net/929210354/Linux
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 0/0 | 1/2 | 10/10 | 使用虚拟机安装linux系统 |
| 第二周 | 341/341 | 1/3 | 20/30 | 掌握核心的linux命令 |
| 第三周 | 177/518 | 2/5 | 16/46 | 学会了虚拟机上的VC编程 |
| 第五周 | 161/679 | 1/6 | 15/61 | |
| 第六周 | 73/752 | 1/7 | 15/76 | 安装了Y86处理器 |
| 第七周 | 134/886 | 1/8 | 12/88 | 建立了项目结构 |
标签:不同的 抽取 32位 驱动器 编译器 通用 一半 距离 2.3
原文地址:http://www.cnblogs.com/dwc929210354/p/6014194.html