标签:线性 src 讲解 line val std 多少 表达式 最优
本文将用一个例子来讲述怎么用scikit-learn和pandas来学习Ridge回归。
在我的另外一遍讲线性回归的文章中,对Ridge回归做了一些介绍,以及什么时候适合用 Ridge回归。如果对什么是Ridge回归还完全不清楚的建议阅读我这篇文章。
Ridge回归的损失函数表达形式是:
\(J(\mathbf\theta) = \frac{1}{2}(\mathbf{X\theta} - \mathbf{Y})^T(\mathbf{X\theta} - \mathbf{Y}) + \frac{1}{2}\alpha||\theta||_2^2\)
其中\(\alpha\)为常数系数,需要进行调优。\(||\theta||_2\)为L2范数。
算法需要解决的就是在找到一个合适的超参数\(\alpha\)情况下,求出使\(J(\mathbf\theta)\)最小的\(\theta\)。一般可以用梯度下降法和最小二乘法来解决这个问题。scikit-learn用的是最小二乘法。
这里我们仍然用UCI大学公开的机器学习数据来跑Ridge回归。
数据的介绍在这: http://archive.ics.uci.edu/ml/datasets/Combined+Cycle+Power+Plant
数据的下载地址在这: http://archive.ics.uci.edu/ml/machine-learning-databases/00294/
里面是一个循环发电场的数据,共有9568个样本数据,每个数据有5列,分别是:AT(温度), V(压力), AP(湿度), RH(压强), PE(输出电力)。我们不用纠结于每项具体的意思。
我们的问题是得到一个线性的关系,对应PE是样本输出,而AT/V/AP/RH这4个是样本特征, 机器学习的目的就是通过调节超参数\(\alpha\)得到一个线性回归模型,即:
\(PE = \theta_0 + \theta_1*AT + \theta_2*V + \theta_3*AP + \theta_4*RH\)
使损失函数\(J(\mathbf\theta)\)最小。而需要学习的,就是\(\theta_0, \theta_1, \theta_2, \theta_3, \theta_4\)这5个参数。
下载后的数据可以发现是一个压缩文件,解压后可以看到里面有一个xlsx文件,我们先用excel把它打开,接着“另存为“”csv格式,保存下来,后面我们就用这个csv来运行Ridge回归。
这组数据并不一定适合用Ridge回归模型,实际上这组数据是高度线性的,使用正则化的Ridge回归仅仅只是为了讲解方便。
我们先打开ipython notebook,新建一个notebook。当然也可以直接在python的交互式命令行里面输入,不过还是推荐用notebook。下面的例子和输出我都是在notebook里面跑的。
先把要导入的库声明了:
import matplotlib.pyplot as plt %matplotlib inline import numpy as np import pandas as pd from sklearn import datasets, linear_model
接着用pandas读取数据:
# read_csv里面的参数是csv在你电脑上的路径,此处csv文件放在notebook运行目录下面的CCPP目录里 data = pd.read_csv(‘.\CCPP\ccpp.csv‘)
我们用AT, V,AP和RH这4个列作为样本特征。用PE作为样本输出:
X = data[[‘AT‘, ‘V‘, ‘AP‘, ‘RH‘]] y = data[[‘PE‘]]
接着把数据集划分为训练集和测试集:
from sklearn.cross_validation import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
要运行Ridge回归,我们必须要指定超参数\(\alpha\)。你也许会问:“我也不知道超参数是多少啊?” 我也不知道,那么我们随机指定一个(比如1),后面我们会讲到用交叉验证从多个输入超参数\(\alpha\)中快速选择最优超参数的办法。
from sklearn.linear_model import Ridge ridge = Ridge(alpha=1) ridge.fit(X_train, y_train)
训练完了,可以看看模型参数是多少:
print ridge.coef_ print ridge.intercept_
输出结果如下:
也就是说我们得到的模型是:
\(PE = 447.05552892 - 1.97373209*AT - 0.2323016*V + 0.06935852*AP - 0.15806479*RH\)
但是这样还没有完?为什么呢,因为我们假设了超参数\(\alpha\)为1, 实际上我们并不知道超参数\(\alpha\)取多少最好,实际研究是需要在多组自选的\(\alpha\)中选择一个最优的。
那么我们是不是要把上面这段程序在N种\(\alpha\)的值情况下,跑N遍,然后再比较结果的优劣程度呢? 可以这么做,但是scikit-learn提供了另外一个交叉验证选择最优\(\alpha\)的API,下面我们就用这个API来选择\(\alpha\)。
这里我们假设我们想在这10个\(\alpha\)值中选择一个最优的值。代码如下:
from sklearn.linear_model import RidgeCV ridgecv = RidgeCV(alphas=[0.01, 0.1, 0.5, 1, 3, 5, 7, 10, 20, 100]) ridgecv.fit(X_train, y_train) ridgecv.alpha_
输出结果为:7.0,说明在我们给定的这组超参数中, 7是最优的\(\alpha\)值。
通过Ridge回归的损失函数表达式可以看到,\(\alpha\)越大,那么正则项惩罚的就越厉害,得到回归系数\(\alpha\)就越小,最终趋近与0。而如果\(\alpha\)越小,即正则化项越小,那么回归系数\(\alpha\)就越来越接近于普通的线性回归系数。
这里我们用scikit-learn来研究这种Ridge回归的变化,例子参考了scikit-learn的官网例子。我们单独启动一个notebook或者python shell来运行这个例子。
首先还是加载类库:
import numpy as np import matplotlib.pyplot as plt from sklearn import linear_model %matplotlib inline
接着我们自己生成一个10x10的矩阵X,表示一组有10个样本,每个样本有10个特征的数据。生成一个10x1的向量y代表样本输出。
# X is a 10x10 matrix X = 1. / (np.arange(1, 11) + np.arange(0, 10)[:, np.newaxis]) # y is a 10 x 1 vector y = np.ones(10)
这样我们的数据有了,接着就是准备超参数\(\alpha\)了。我们准备了200个超参数,来分别跑 Ridge回归。准备这么多的目的是为了后面画图看\(\alpha\)和\(\theta\)的关系
n_alphas = 200 # alphas count is 200, 都在10的-10次方和10的-2次方之间 alphas = np.logspace(-10, -2, n_alphas)
有了这200个超参数\(\alpha\),我们做200次循环,分别求出各个超参数对应的\(\theta\)(10个维度),存起来后面画图用。
clf = linear_model.Ridge(fit_intercept=False) coefs = [] # 循环200次 for a in alphas: #设置本次循环的超参数 clf.set_params(alpha=a) #针对每个alpha做ridge回归 clf.fit(X, y) # 把每一个超参数alpha对应的theta存下来 coefs.append(clf.coef_)
好了,有了200个超参数\(\alpha\),以及对应的\(\theta\),我们可以画图了。我们的图是以\(\alpha\)为x轴,\(\theta\)的10个维度为y轴画的。代码如下:
ax = plt.gca() ax.plot(alphas, coefs) #将alpha的值取对数便于画图 ax.set_xscale(‘log‘) #翻转x轴的大小方向,让alpha从大到小显示 ax.set_xlim(ax.get_xlim()[::-1]) plt.xlabel(‘alpha‘) plt.ylabel(‘weights‘) plt.title(‘Ridge coefficients as a function of the regularization‘) plt.axis(‘tight‘) plt.show()
最后得到的图如下:
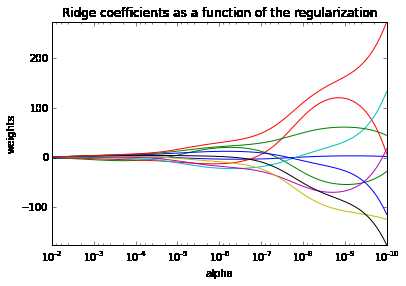
从图上也可以看出,当\(\alpha\)比较大,接近于\(10^{-2}\)的时候,\(\theta\)的10个维度都趋于0。而当\(\alpha\)比较小,接近于\(10^{-10}\)的时候,\(\theta\)的10个维度都趋于线性回归的回归系数。
(欢迎转载,转载请注明出处。欢迎沟通交流: pinard.liu@ericsson.com)
标签:线性 src 讲解 line val std 多少 表达式 最优
原文地址:http://www.cnblogs.com/pinard/p/6023000.html