标签:上下文 command 依赖注入 常见 工作量 entity 应用 资源库 对象
一、前言
上一篇我们讲了DDD的核心概念(附上链接),并且设计了我们的上下文映射图,那么接下来就准备开始立项了,本篇文章的部分知识点可能对一部分人来说比较基础,可以选择性的阅读。
在这之前我们平常用的最多的应该就是3层架构了,这里也不展开描述了,大家都是在3层的陪伴下一路走来的~
DDD所使用的传统分层架构是松散分层,也就是上层可以访问任意层级的下层,而不是仅限于当前层的下一层,这是有别于3层架构的。如下面2张图的区别图:
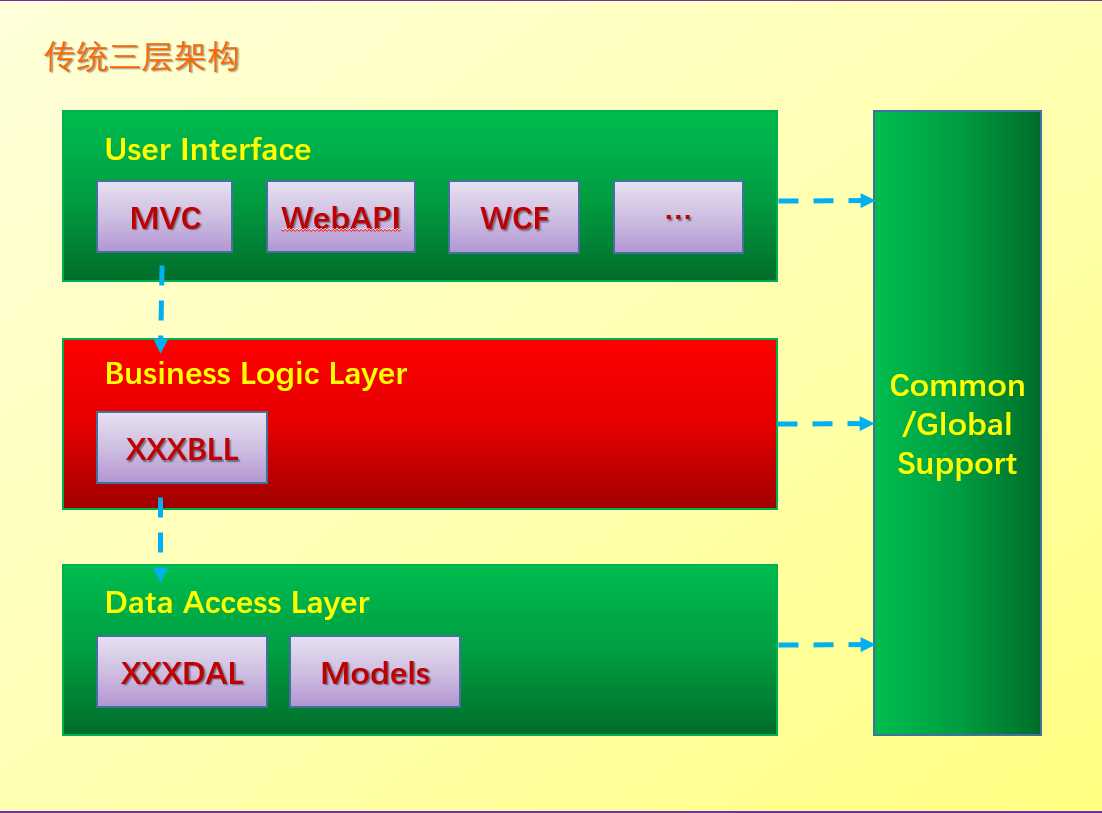
【图1】
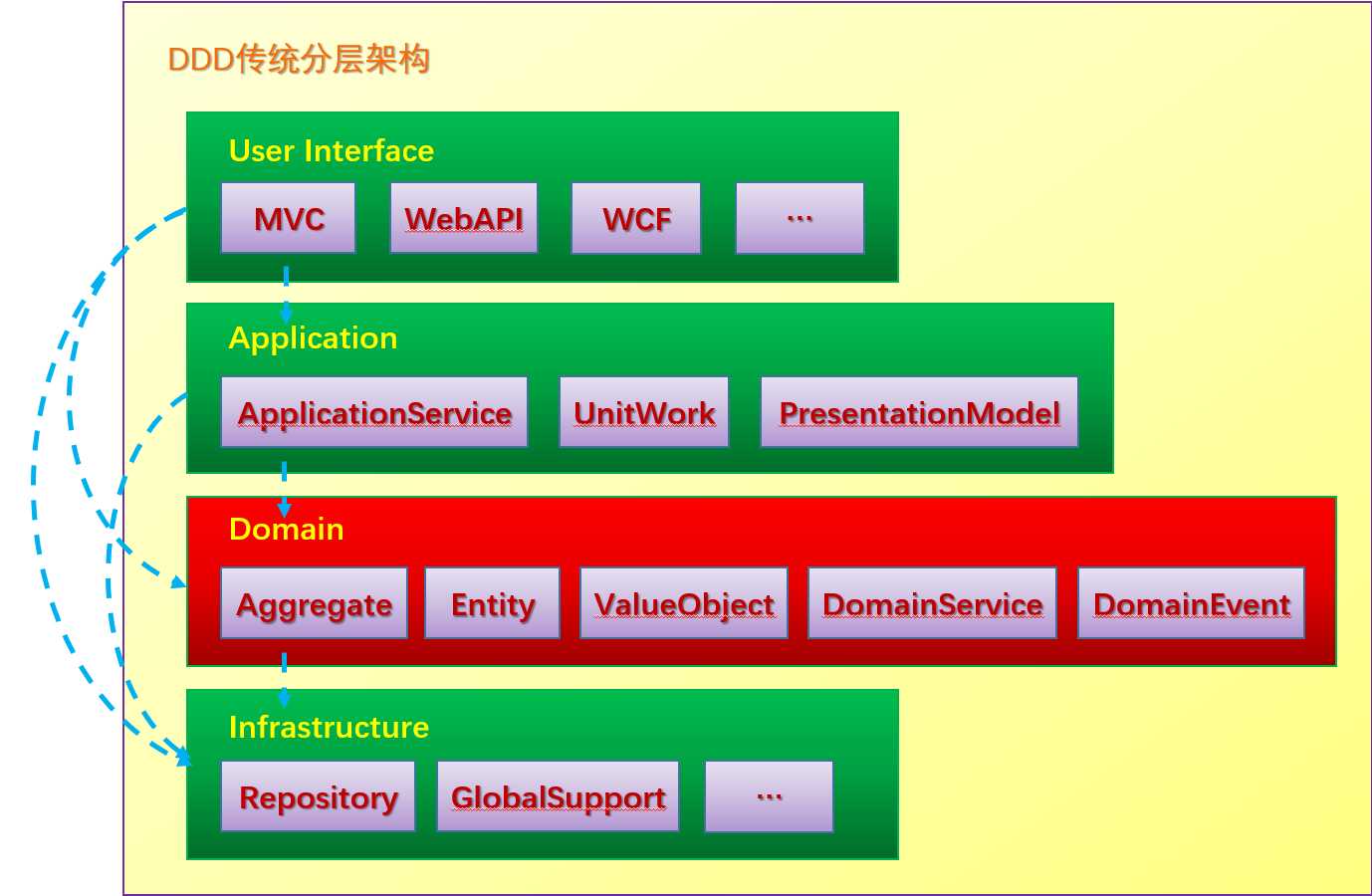
【图2】
Application:这层的职责是对接收到的数据做一些非业务性验证,事务的控制,最重要的是协调多个聚合之间的操作。这里应该可以清晰的表达出整个操作所做的事情,并且与通用语言是一致的。
Domain:这一层是DDD设计的核心,这里不但需要精确合理的表达出通用语言的每一个细节,另外如何把对象合理的定义为聚合、实体、值对象也是重中之重。这里不但关系着整个项目的复杂度,也是战术建模的体现,任何的一行代码都是对业务的准确定义,应该是恰到好处。一个清晰简洁的战术建模才可以应对后续的快速变化。
Infrastructure:这里是辅助性的一层,也是整个项目的基础。好比这里存放着一砖一瓦,最终建造什么模样的高楼在于用它的地方。主要包括,仓储的实现(我们存放数据的地方)、一些通用的支撑性类库。
二、六边形架构
在[Vaughn Vernon]《实现领域驱动设计》一书中多次提到对DDD主张六边形架构的概念,六边形架构对于保证限界上下文内的领域概念的清晰性有着重要的作用,那么什么是六边形架构,如下图3(摘自[Vaughn Vernon]《实现领域驱动设计》一书)。
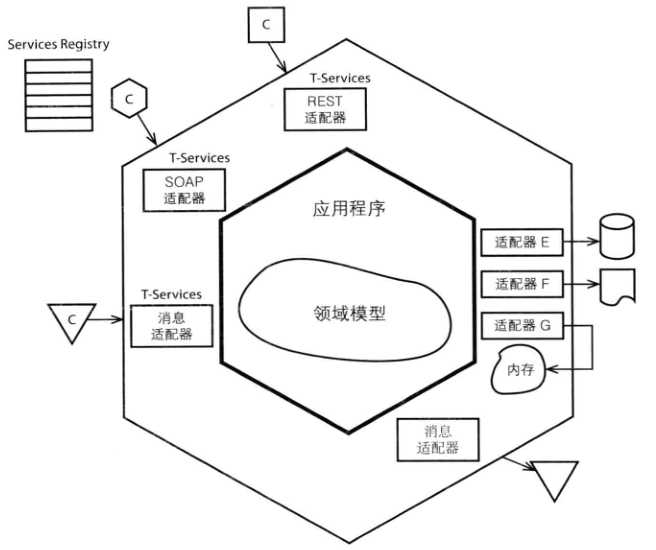
【图3】
在当今越来越提倡开放合作的大环境下,引用的多样化的Service,和在自身系统达到一定规模之后的分布式治理,越来越需要通过协作进行工作,那么如何提升协作的效率变得越来越重要。提高各个应用程序的自治性,是一种有效提升协作能力的手段。从上图中看出为了保证领域模型所在的应用程序的干净简洁和自治性,各种适配器作为"防腐层(在上篇中有提到)"在整个程序的最外层保护着当前的“界限上下文(在上篇中有提到)”不受外部入侵。
所以在我们的整个设计中需要注意对涉及到外部系统交互的地方的抽象,通过面向接口、依赖注入等方式做到外部的变化对自身系统的影响最小化。
三、终于开始建项目了
按照之前的这些描述,我们终于初步建立了我们的解决方案。如下图4:
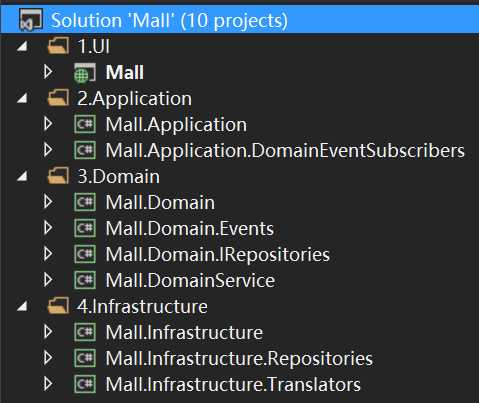
【图4】
这里把每个项目的职责大致说一下。
Mall:负责我们的电商网站的界面处理和用户的数据录入
Mall.Application:按模块分别定义不同的ApplicationService来讲述每一个操作下的“故事”。
Mall.Application.DomainEventSubscribers:所有的领域事件订阅者。
Mall.Domain:这里存放着战术建模的结晶,Entity、Aggregate、ValueObject。(下面会具体讲述下)
Mall.Domain.Events:所有的领域事件,这层也可以合并到Domain中,给它新建一个文件夹。
Mall.Domain.IRepositories:所有的仓储(资源库)接口。类似于三层中的IDAL。
Mall.DomainService:领域服务,存放着那些不适合放在聚合/值对象上的无状态的操作方法,用于实现特定某个领域的任务。
Mall.Infrastructure:存放着一些通用类库
Mall.Infrastructure.Repositories:所有仓储(资源库)的实现。
Mall.Infrastructure.Translators:翻译层,也就是与外部系统沟通的桥梁,主要的职责就是做好“反腐层”的重任。
四、DDD中的3个臭皮匠
这里的3个臭皮匠其实就是:Entity、ValueObject、Aggregate。我们要提炼出业务中的精华,合理的抽象为这3个概念,并且这种抽象是需随着领域里的概念变化而变化的。这3者的结合运用会让我们的项目活起来,这是DDD的核心。这里再把这3个概念重新梳理一下。
Entity(实体): 每个实体是唯一的,并且可以相当长的一段时间内持续地变化。我们可以对实体做多次修改,故一个实体对象可能和它先前的状态大不相同。但是,由于它们拥有相同的身份标识,他们依然是同一个实体。
ValueObject(值对象):值对象用于度量和描述事物,当你只关心某个对象的属性时,该对象便可作为一个值对象。实体与值对象的区别在于唯一的身份标识和可变性。
Aggregate(聚合):聚合类是实体的升级,是由一组与生俱来就密切相关实体和值对象组合而成的,这整个组合的最上层实体就是聚合。
五、CQRS(Command Query Responsibility Segregation)
说到DDD必然要提一下CQRS,我认为CQRS和DDD的关系就像咖啡和牛奶,给大型系统的构建提供了一剂良药,它生于读写分离,具有高吞吐量、高伸缩性等特点,值得我们为之付出一些代价。但是CQRS的使用会使整个数据持久化和查询的链路拉长,并且工作量也会比简单的读写一体化大的多,所以需要对项目做出合理的考量来决定是否使用。
当我们需要把某个复杂的聚合修改之后写入到数据库的时候,要保证N张表的数据被同时修改成功,整个事务的周期必然会加长。而且当我们需要显示来自不同聚合类型与实例的数据时,我们的SQL必然包含N多的join。领域越复杂这种情况越发常见。
CQRS需要和事件源结合使用,对数据的修改操作只是往事件源里增加一条修改后的结果记录(类似于我们的源码控制软件的log),并不会直接把修改后的对象持久化到数据库。这样能够大大提高数据修改的速度,并且对于查询操作的实现方式就比较多样化了。大致列举了以下4种方式:
1.还是使用单个数据库,每次领域对象的获取都需要根据事件源中的事件集合做重建,得到当前的最新的数据返回。这只是编码设计上的读写分离
2.拆分为读库和写库,实现方式同1
3.拆分为读库和写库,并且针对读库做专门的查询数据冗余,异步的通过事件源来修改查询数据,可以结合merge commit。
4.在3的基础上做读库的负载均衡
这4种方式复杂度各不相同,可以结合实际项目的复杂度择优选择,其中最关键的一条便是是否存在大量的列表类数据展示,如果是那么1和2便就不适合了。在以上的方式之外可以结合其他的数据存储一起使用,如缓存,NoSql,然而这只需要订阅所有的命令事件即可实现。
六、结语
本篇主要介绍了项目的分层架构、每层的职责和里面存放什么样子的类。限于非我们这个系列的核心主题,所以都没有发散出去做更加具体形象的描述,希望大家可以边结合[Vaughn Vernon]《实现领域驱动设计》一书的阅读跟着我做实际的编码来加深对DDD的理解。跳出根深蒂固的三层思想是痛苦的,但是我认为只要坚持下去,DDD会让你看见一片世外桃源,到那时会觉得我们的付出都是值得的。并且DDD思想的运用可大可小,小到类的设计,大到复杂项目之间的构架,都会给你提供帮助。
作者:Zachary_Fan
出处:http://www.cnblogs.com/Zachary-Fan/p/6012454.html
标签:上下文 command 依赖注入 常见 工作量 entity 应用 资源库 对象
原文地址:http://www.cnblogs.com/Leo_wl/p/6024816.html