标签:pre 系统 不为 需要 键值 shm code 节点 zhang
HashMap中的put方法
public V put(K key, V value) { //当key为null,调用putForNullKey方法,保存null与table第一个位置中,这是HashMap允许为null的原因 if (key == null) return putForNullKey(value); //计算key的hash值 int hash = hash(key.hashCode()); ------(1) //计算key hash 值在 table 数组中的位置 int i = indexFor(hash, table.length); ------(2) //从i出开始迭代 e,找到 key 保存的位置 for (Entry<K, V> e = table[i]; e != null; e = e.next) { Object k; //判断该条链上是否有hash值相同的(key相同) //若存在相同,则直接覆盖value,返回旧value if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; //旧值 = 新值 e.value = value; e.recordAccess(this); return oldValue; //返回旧值 } } //修改次数增加1 modCount++; //将key、value添加至i位置处 addEntry(hash, key, value, i); return null; }
key为null:
private V putForNullKey(V value) { for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(0, null, value, 0); return null; }
获取Entry的第一个元素table[0],并基于第一个元素的next属性开始遍历,直到找到key为null的Entry,将其value设置为新的value值。
如果没有找到key为null的元素,则调用如上述代码的addEntry(0, null, value, 0);增加一个新的entry
void addEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<K,V>(hash, key, value, e); if (size++ >= threshold) resize(2 * table.length); }
hash方法:
static int hash(int h) { h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); }
讲解说明:

将hash函数作为已给定的hashCode的一个补充,可以提高hash函数的质量。hash质量的好坏是非常重要的,因为HashMap用2的次幂作为表的hash长度,这就容易产生冲突,因为hashCodes在低位不是不同的(hashCodes that do not differ in lower bits)。注意:Null 的key的hash值总是0,即他在table的索引为0。 让我们通过例子来帮助我们理解一下上面的话。加入说key object的hashCode()只返回三个值:31、63和95.31、63和95都是int型,所以是32位的。 31=00000000000000000000000000011111 63=00000000000000000000000000111111 95=00000000000000000000000001011111 现在加入HashMap的table长为默认值16(2^4,HashMap的长度总是2的次幂) 假如我们不用hash函数,indexFor将返回如下值: 31=00000000000000000000000000011111 => 1111=15 63=00000000000000000000000000111111 => 1111=15 95=00000000000000000000000001011111 => 1111=15 为什么会这样?因为当我们调用indexFor函数的时候,它将执行31&15,,63&15和95&15的与操作,比如说95&15得出一下结果: 00000000000000000000000001011111 &00000000000000000000000000001111 也就是说(2^n-1)总会是一个1的序列,因此不管怎样,最后会执行0&1的于然后得出0. 上面的例子,也就解释了凡是在末尾全是1111的都返回相同的index,因此,尽管我们有不同的hashcode,Entry对象却讲都被存在table中index为15的位置。 倘若我们使用了hash函数,对于上面每一个hashcode,经过hash作用作用后如下: 31=00000000000000000000000000011111 => 00000000000000000000000000011110 63=00000000000000000000000000111111 => 00000000000000000000000000111100 95=00000000000000000000000001011111 => 00000000000000000000000001011010 现在在通过新的hash之后再使用indexFor将会返回: 00000000000000000000000000011110 =>1110=14 00000000000000000000000000111100 =>1100=12 00000000000000000000000001011010 =>1010=10 在使用了hash函数之后,上面的hashcodes就返回了不同的index,因此,hash函数对hashmap里的元素进行了再分配,也就减少了冲突同时提高了性能。 hash操作最主要的目的就是在最显著位的hashcode的差异可见,以致于hashmap的元素能够均匀的分布在整个桶里。 有两点需要注意: 如果两个key有相同的hashcode,那他们将被分配到table数组的相同index上 如果两个key不具有相同的hashcode,那么他们或许可能,或许也不可能被分配到table数组相同的index上。
indexFor方法:
static int indexFor(int h, int length) { return h & (length-1); }
讲解说明:
这个方法有点意思,主要作用是定位hashmap里的bucket。 ------------------------------------------------------- 大家知道hashmap底层就是一个数组,然后数组里每个元素装了个链表。 这个数组元素称为bucket桶 ------------------------------------------------------- 先复习一下逻辑与。 0 & 0 = 0;0 & 1 = 0;1 & 0 = 0;1 & 1 = 1; 第二个参数length始终为2的n次方,所以, 换成二进制数就是 100,1000,10000,... (length -1)就是 11, 111,1111,... 这样的话, 第一个参数h比第二个参数小的情况下,那结果就是h。 第一个参数h比第二个参数大的情况下,如下: 例: h=18 -> 10010 length-1=15 -> 01111 所以在第一个参数比第二个参数大的情况下等于第一参数%第二参数,取余数
addEntry
void addEntry(int hash, K key, V value, int bucketIndex) { //获取bucketIndex处的Entry Entry<K, V> e = table[bucketIndex]; //将新创建的 Entry 放入 bucketIndex 索引处,并让新的 Entry 指向原来的 Entry table[bucketIndex] = new Entry<K, V>(hash, key, value, e); //若HashMap中元素的个数超过极限了,则容量扩大两倍 if (size++ >= threshold) resize(2 * table.length); }
put的流程:
当我们想一个HashMap中添加一对key-value时,系统首先会计算key的hash值,然后根据hash值确认在table中存储的位置。
若该位置没有元素,则直接插入。否则迭代该处元素链表并依此比较其key的hash值。
如果两个hash值相等且key值相等(e.hash == hash && ((k = e.key) == key || key.equals(k))),则用新的Entry的value覆盖原来节点的value。
如果两个hash值相等但key值不等 ,则将该节点插入该链表的链头(最先保存的元素放在链尾),新元素设置为Entry[0],其next指针指向原有对象,即原有对象为Entry[1]
比如, 第一个键值对A进来,通过计算其key的hash得到的i=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其i也等于0,现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,i也等于0,那么C.next = B,Entry[0] = C;这样我们发现i=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起,也就是说数组中存储的是最后插入的元素。
HashMap的get操作:
public V get(Object key) { if (key == null) return getForNullKey(); int hash = hash(key.hashCode()); for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k)))//-------------------1---------------- return e.value; } return null; }
当key为null时,调用getForNullKey()
private V getForNullKey() { for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) return e.value; } return null; }
当key不为null时,先根据hash函数得到hash值,在更具indexFor()得到i的值,循环遍历链表,如果有:key值等于已存在的key值,则返回其value。
=======================================================================================================
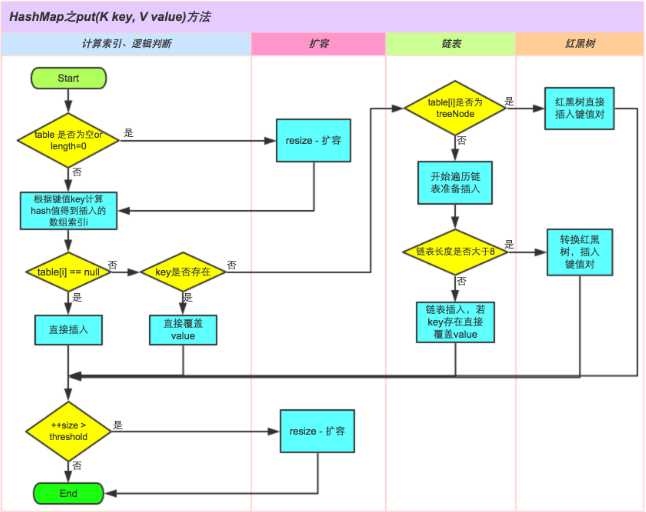
JDK8的讲解图:
HashMap的put方法
=====================================================================
JDK1.8以后对hashmap进行了大量的优化
JDK8 因为对自己改造过的哈希大量冲突时的红黑树有信心,所以简单一些,只是把高16位异或下来。
static int hash(int h) {
return h ^ (h >>> 16);
}
所以即使Key比较均匀无哈希冲突,JDK8也比JDK7略快的原因大概于此。
存在哈希冲突的情况,比如两个哈希值取模后落在同一个桶上,或者两条不同的key有相同的哈希值。
JDK7的做法是建一条链表,后插入的元素在上面,一个个地执行上面的判断。
而JDK8则在链表长度达到8,而且桶数量达到64时,建一棵红黑树,解决严重冲突时的性能问题。
http://www.cnblogs.com/chenssy/p/3521565.html
http://blog.csdn.net/zhangerqing/article/details/8193118
http://tech.meituan.com/java-hashmap.html
http://calvin1978.blogcn.com/articles/hashmap.html
http://www.importnew.com/7099.html
标签:pre 系统 不为 需要 键值 shm code 节点 zhang
原文地址:http://www.cnblogs.com/hongdada/p/6024799.html
