标签:自由度 分类 block ges 分布 文章 其他 基础 isp
最近导师让做一个文本分类的东西,偶然间看到卡方检验,不懂(感觉自己实在是水到家,博客里讲的基础的东西,到我这里就是漫天找资料学),于是找了些博客文章,总结了下,有所体会。
引子
首先讲一下什么是卡方检验。卡方检验按照定义来说就是:检验实际的数据分布情况与理论的分布情况是否相同.这样讲比较抽象,这里讲个具体的例子:
拿某地区的年降水天数来说明。比如一年365天中该地区有180天降水,那么该地区的降水概率近似等于50%,那么对于每个月份来讲,是否降水的概率达到了预期的50%(也就是 15天)呢?
卡方检验就是用来解决这样的问题。
原理
同样使用一个文本分类的例子来说明卡方检验的原理(也可以稍稍说明卡方检验的用途)。
我们有一堆打好标签分好类的文本,简单起见,目前我们只有两类:科技类的和非科技类的,同时我们发现我们的文本库里频繁出现"机器学习"这个字样,那么我们想要研究,文本是否出现“机器学习”字样与文本是否是科技类的这两个命题是否有联系。
我们抽取一些文本样本,组成如下的一个四格表:
|
组别 |
科技类 |
非科技类 |
合计 |
|
不含”机器学习” |
19 |
24 |
43 |
|
含“机器学习” |
34 |
10 |
44 |
|
合计 |
53 |
34 |
87 |
从抽样的结果看来,是否含有“机器学习”字样确实对文本是否属于科技类在抽样结果上有影响(从表中结果来看,含“机器学习”字样的文本属于科技类的概率确实高于不含的情况)。但是这种结果的发生也有可能是因为抽样误差导致的,为了进一步说明两者之间的联系,我们先假设含不含“机器学习”字样与是否是科技类无关,那么,任取一个文本,属于科技类的概率就能这么计算(19+34)/(24+10)=60.9%,于是,我们通过对实际抽样结果四格表(表1),可以得到一张预期结果(即在假设条件成立下)的四格表
|
组别 |
科技类 |
非科技类 |
合计 |
|
不含”机器学习” |
43*60.9%=26.2 |
43-26.2=16.8 |
43 |
|
含“机器学习” |
53-26.2=26.8 |
44-26.8=17.2 |
44 |
|
合计 |
53 |
34 |
87
|
注:1个数据通过概率求得后,其他数据可通过合计加减得到
现在我们就得到了卡方检验要求的“预期结果”和“实际结果”了。
那么怎么来通过计算确定这两个命题是否相关呢?这里就要引出计算公式:
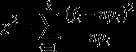
这是一般情况,简化成我们这个案例的公式,就是
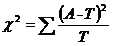
这里的A就是我们的实际情况,T就是预期结果
x2用于衡量实际值与理论值的差异程度(也就是卡方检验的核心思想),包含了以下两个信息:
实际值与理论值偏差的绝对大小(由于平方的存在,差异是被放大的)
差异程度与理论值的相对大小
对上述场景可计算x2值为10.01。
接下来是怎么用这个结果,就是说,我们怎么衡量这个10.01是大了还是小了。这里需要引入一个“自由度”的概念。
自由度等于V = (行数 - 1) * (列数 - 1),对四格表,自由度V = 1。
对V = 1,卡方分布的临界概率是:

我们根据自由度,查分布临界值表,发现10.01>7.88,那么我们之前所做的假设成立的概率<0.005,即0.5%。显然,两者相关的可能性非常大。
应用
通过上一个案例,我们获得了卡方检验的校验值,那么这个值的大小,其实是可以用来说明两个命题的相关性的。就上一个文本分类的例子来说,我们可以通过计算一个词典的所有的词出现与否与该文章是否为科技文来计算得到两者的相关性,并且倒序排列,我们就能知道某个类型的文章最能出现怎样的词了。
后记
话说卡方检验在大二的概率论与数理统计好像就学过,当时学得迷迷糊糊的,现在重新拾起来真是感觉吃力。话说回来,本科3年的学习真是只是“记”了,然而并不会“用” 。
标签:自由度 分类 block ges 分布 文章 其他 基础 isp
原文地址:http://www.cnblogs.com/HolyShine/p/6028601.html