标签:技术 资源 use 设备 net img 问题 技术分享 适应
后记转载请标明出处
报告题目:机器学习:发展与未来
报告人:周志华
演讲摘要:在过去二十年中,人类收集、存储、传输、处理数据的能力取得了飞速发展,亟需能有效地对数据进行分析利用的计算机算法。机器学习作为智能数据分析算法的源泉,顺应了大时代的这个迫切需求,因此自然地取得了巨大的发展、受到了广泛关注。
机器学习是从人工智能中产生的一个重要学科分支,是实现智能化的关键。它的经典定义是:利用经验改善系统自身的性能。将经验转化为数据。随着该领域的发展,目前主要研究智能数据分析的理论和算法,并已成为智能数据分析技术的源泉之一。
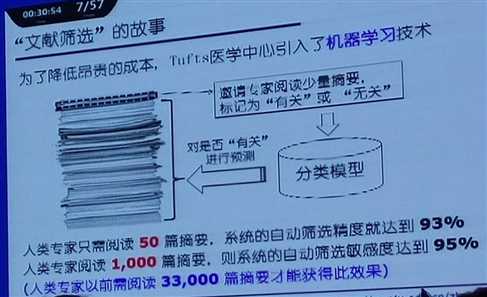
文章筛选的故事:邀请专家阅读少量的文章,专家将文章标记为“有关”或者“无关”,基于这个信息建立一个分类模型,再根据这个模型来对其他的文章进行预测。
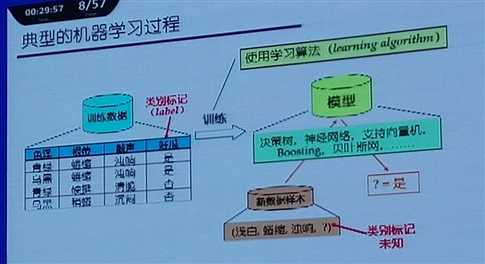
典型的机器学习的过程:先收集到数据,数据是表格的形式,每一行表示一个对象或一个实例,每一列刻画了一个对象的一个属性,其中有一列我们管它叫做类别标记。
我们对这些数据进行训练得到模型。今后,当我们拿到一个我们没有见过的数据的时候,我们知道它的输入,把输入输入到这个模型,这个模型就会给你一个结果(比如西瓜好还是不好)。所以我们在现实生活中遇到的分类、推测这类问题都可以抽象出来。比较重要的是如何对数据进行学习来得到这个模型(使用学习算法)。
深度学习
1、提升模型复杂度->提升学习能力
增加隐层神经元数目(模型宽度)增加函数个数
增加隐层数目(模型深度)增加了函数的个数同时增加了函数的层数:增加隐层数目比增加隐层神经元数目更加有效,不仅增加了拥有激活函数的神经元数,还增加了激活函数嵌套的层数。
2、提升模型复杂度->增加过拟合风险(因为模型过于复杂),增加计算开销
过拟合风险解决可以使用大量训练数据,复杂的模型使用强力计算设备来计算
深度学习还需要诀窍。
未来机器学习可能的问题:难以适应环境变化、难以了解模型、难以获取充足样本、难以获得专家级结果、难以避免数据泄漏。
此外,即便相同的数据,普通用户也很难活得机器学习专家级性能。
关于未来的浅见:开放环境学习任务,鲁棒性是关键。
提出了一个学件(learn ware)的概念
学件(learnware)=模型(model)+规约(specification)
已经由别人做了机器学习的应用了并且很乐意将自己的模型分享出来,放在一个平台。其他人可以在这个平台中查找有没有自己适用的模型。部分重用他人结果,用自己的数据去打磨这个模型。规约需要能够给出模型的合适刻画。而模型需要满足:可重用,可演进,可了解。
可重用:学件的预训练模型仅需要利用“少量数据”对其进行更新或增强即可用于新任务。
可演进:学件的预训练模型应具备感知环境变化,并针对变化进行主动自适应调整的能力。
可了解:学件的模型应在一定程度上能被用户了解(包括其目标、学得结果、资源要求、典型任务上的性能等),否则,将难以给出模型的功能规约,通过重用、演进后获得的模型的有效性和正确性也难以保障。
机器学习小结:
1、深度学习可能会有冬天,它仅是机器学习的一种技术,更潮的技术总会出现。
2、机器学习不会有冬天:除非我们不再需要分析数据。
3、关于未来:
技术:能有效利用GPU等计算设备
任务:开放环境机器学习任务(鲁棒性是关键)
形态:从“算法+数据”到“学件”(learn ware)
标签:技术 资源 use 设备 net img 问题 技术分享 适应
原文地址:http://www.cnblogs.com/winifred-tang94/p/6028487.html