标签:创建 success 基础概念 lib proc 最简 model 添加 views
前段时间在学习空间统计相关的知识,于是把ArcGIS里Spatial Statistics工具箱里的工具好好研究了一遍,同时也整理了一些笔记上传分享。这一篇先聊一些基础概念,工具介绍篇随后上传。
空间统计研究起步于上个世纪70年代,空间统计其核心就是认识与地理位置相关的数据间的空间依赖、空间关联等关系,通过空间位置建立数据间的统 计关系。空间统计学依赖于tablor地理学第一定律,即空间上越临近的事物拥有越强的相似程度;和空间异质性,即空间位置差异造成的行为不确定现象。例 如要度量犯罪率与教育程度的关系,不同地区 (文教区、贫困区)可能不一样。
利用GIS进行空间统计分析最早可追溯到1854年的伦敦大霍乱(黑死病)。当时盛行的理论是“空气传染”,而不是现在的病菌传染。John Snow 医生开始也相信空气传染学说,但证据使他不得不转向病菌学说。他通过观察霍乱病例在空间上分布的特征,找到了其空间上聚集的地方,进一步找到了致病的水 井。利用空间统计可帮助我们发现、判断并证实事物在空间上分布的规律和特征,从而对研究进行辅助决策。
Moran指数和Geary系数是两个用来度量空间自相关的全局指标。Moran指数反映的是空间邻接或空间邻近的区域单元属性值的相似程度,Geary 系数与Moran指数存在负相关关系。
Moran指数I的取值一般在[-1,1]之间,小于0表示负相关,等于0表示不相关,大于0表示正相关;
Geary系数C的取值一般在[0,2]之间,大于1表示负相关,等于1表示不相关,而小于1表示正相关;
回归分析(regression analysis)是确定两个或多个变量间相互依赖的定量关系的一种统计分析方法。按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。如果在回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
欧几里得距离即两点之间平面直线距离,如果两点的坐标分别为(x1,y1)和(x2,y2),则欧几里得距离计算公式为:
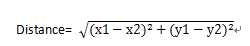
而曼哈顿距离又称为出租车距离,就是在欧几里德空间的固定直角坐标系上两点所形成的线段对轴产生的投影的距离总和,计算公式为:
Distance=|x1-x2|+|y1-y2|
通常定义一个二元对称空间权重矩阵W,来表达n个位置的空间区域的邻近关系,其形式如下:
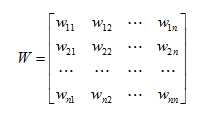
Wij表示区域i与j的临近关系,它可以根据邻接标准或距离标准来度量。
常用的最简单简单的二进制邻接矩阵

常用的基于距离的二进制空间权重矩阵

很多空间统计里的工具都会返回Z分数和P值,P值是统计学中所谓犯“第一类错误”的可能性,指零假设正确,而我们错误的拒绝了零假设的可能性。Z分数也代表拒绝零假设的可能性,也就是说,如果P值越小,Z分数的绝对值越大,就可以越放心的拒绝零假设。
_____________________________________________
ArcGIS 统计工具介绍
随着GIS在各个领域应用的不断扩展,有些特殊的行业,比如流行病学、生物学、气象、地质等行业,他们需要更深入的挖掘空间数据信息,这些信息的获得是与传统的GIS分析结果不尽相同的。比如:传统的GIS分析侧重于研究空间要素之间的关系,比如相邻、叠加、以及要素之间的距离、连通性等等。而这些特殊行业他们需要根据多种采样的数据来研究空间事物的变化信息,分布特征等信息,这些信息的获得,往往是一种统计分析的结果,而在空间上,事物的分布又是相互关联的。所以,空间统计应运而生。所谓空间统计,就是将空间信息与属性信息进行统一的考虑,研究特定属性或属性之间与空间位置的关系。
空间统计主要的工作是研究空间自相关性(Spatial
Autocorrelation),分析空间分布的模式,例如聚类(cluster)或离散(dispersed)。通过使用ArcGIS
9中的空间统计工具,用户可以以一种非常直观而简单的方式获得这些信息。
ArcGIS
9中的空间统计工具箱包括了一系列工具,用来分析地理要素的空间分布形态。传统的统计并不考虑地理要素的空间关系,而在空间统计中,要素的空间关系是分析中需要考虑的必要的,处于绝对重要地位的。
因此,对于空间数据分析的目的来说,使用ArcGIS
9中的空间统计工具比使用原来的不考虑空间信息而进行统计的工具要更为合适。通过使用这些工具,GIS用户可以采用一种更高级的方法来解决空间数据分析中的问题。表一列出了主要的空间统计工具集以及它们的功能描述:
在ArcGIS
8版本中,空间统计中的许多工具已经以开发者例子程序提供给了用户。而在9版本中,这些工具都被包括进了核心的功能模块中,成为了ArcGIS平台的组成部分。而且,ArcGIS
9的空间统计工具在ArcGIS各个License级别中均可使用。与ArcGIS
9的Geoprocessing工具一样,空间统计的工具也可以通过对话框、命令行以及模型(Model)等多种方式运行。通过与Geoprocessing框架下的其他工具进行组合,空间统计工具也可以很容易的进行扩展,用户可以创建自己的工具,也可以同第三方产品进行协同工作。
空间统计工具箱下的每个工具集都是按照功能进行分组的。下面会对每个工具集中的工具进行详细的描述:
一、分析模式工具集(Analyzing Patterns):
该工具集中的工具主要用来探讨数据的空间分布特征。包含三个工具:
1, 平均最邻近距离工具(Average Nearest Neighbor):
测量每个要素与之最邻近要素之间的距离,并计算平均值。再测量平均距离与假定为随机分布距离的相似程度。工具进行统计后返回z
score值。Z score值为负且越小,则要素分布越趋向于聚类分布,相反为离散分布。
该工具主要用于说明要素之间的接近程度以及它们之间的相互关系
提示:
􀂾
用空间统计工具均以Python脚本或Model的方式提供给用户,所以必须要安装Python编译环境(在安装ArcGIS软件时,Python默认情况下需要安装的)。
􀂾 如果工具中提供了图形化显示输出结果(Display Output
Graphically)选项,推荐进行选中,以便于观察形象的统计结果(如图一、图二)。
􀂾
对于一些optional的选项,选择与否或是否进行设置对输出结果的影响是很大的,推荐用户在对自己数据的充分认识的基础上,进行合理的设置。
􀂾 可以点击工具面板上的“show
help”按钮,显示该工具的简单描述信息。如果想获得更详细的信息,点击描述信息上的help就会自动打开并跳转到ArcGIS
Desktop Help中的该工具的详细信息。
􀂾 请将运行结果面板的Close this dialog when
completed
successfully选项取消选中,并激活Details按钮。这样,统计的结果会在工具面板中进行显示(如图三)。
2, 高/低聚类分析工具(High/Low Clustering ---Getis-Ord General G):
测量特定区域的聚合程度。返回General G Index值和Z Score值。G
Index值越高,越趋向于高聚类。相反为低聚类。Z值为正且越大,要素分布趋向高聚类分布。相反为低聚类分布。
应用案例:查找城市中不同地区的人口聚集水平,或人口随时间的聚集水平。
该工具返回某个属性在空间上是高值聚类还是低值聚类的可能性,零假设是随机分布。如果P值具有统计显著性,则可推翻零假设。可以用该工具来反映GDP产值大部分是高于平均水平(高值聚集)还是低于平均水平(低值聚集)。
Conceptualization of Spatial Relationships:度量要素间空间位置关系的方式,推荐使用Fixed Distance Band, Polygon Contiguity方法;
Standardization:行标准化一般是在数据存在可能的偏见性的时候采用,一般是由于有偏采样造成的,这里推荐使用None;
Weights Matrix File(optional):空间权重矩阵文件,可指定ASCII码格式的权重文件,如果要素的个数大于5000个,建议转换成swm格式。
该工具会给出一系列的统计值,包括Observed General G, Expected General G, 方差(Variance), Z分数和P值。如果P值具有显著性,则看Z值为正则Observed General G大于Expected General G,说明为高值聚类;如果Z值为负,则Observed General G小于Expected General G,为低至聚类。
3, 空间自相关工具(Spatial Autocorrelation --- Moran’s I):
Moran’s I 方法是进行空间自相关统计的常用统计方法。该方法在ArcGIS 9中得到了实现。通过使用该工具,会返回Moran’s
I Index值以及Z Score值。如果z score值小于-1.96获大于1.96,那么返回的统计结果就是可采信值。如果z
score为正且大于1.96,则分布为聚集的。如果z
score为负且小于-1.96,则分布为离散的。其他情况可以看作随机分布。
相关概念:
􀂾
空间相关性:检测空间上两种现象(统计量)的变化是否存在相关性。比如,水稻的产量往往与所处的土壤的肥沃程度相关。
􀂾
空间自相关:研究空间中,某个空间单元与其周围的单元之间,就某种特征,通过统计方法,进行空间相关性程度的计算,以分析这些空间单元在空间上分布现象的特性。也就是说,空间自相关研究的是不同观察对象的同一属性在空间上的相互关系。[1]
二、聚类分布制图工具集(Mapping Clusters):
1, 聚集及特例分析工具(Cluster and Outlier Analysis --- Anselin Local Moran’s
I):
使用该工具会输出一个新的要素类。该要素类在原要素类上添加了两个字段,分别为LMi<distance_method>和LMz<distance_method>,分别代表各个要素的索引值I和z
score值。如果索引值I为正,则要素值与其相邻的要素值相近,如果索引I值为负值,则与相邻要素值有很大的不同。如果z
score为正且越大,则要素越与相邻要素值相近,相反,如果z
score值为负却越小,则与相邻要素值差异越大(也就是相关性不强)。
对于线类要素和多边形要素,程序会计算要素的几何中心点,然后对几何中心点进行分析。这就会造成有些要素的几何中心点不在几何要素内部,如果想达到此目的,请先用Feature
to Points工具进行转换后再进行分析。
2, 聚集及特例分析并符号化(Cluster and Outlier Analysis with Rendering):
进行与聚集及边界分析工具相同的操作并对结果进行符号化。
3, 热点分析(Hot Spot Analysis --- Getis-Ord Gi*):
对输入要素进行Getis-Ord Gi*统计。并把统计结果作为新加字段(Gi<distance band
or threshold distance 的输入值>)写入输出要素中。关于Getis-Ord
Gi*统计的方法请查阅相关文章。
该工具主要用于进行事件发生地区的预测或获取关注地区。比如通过对以往犯罪发生频率的统计,推测可能再次发生的地点。
4, 热点分析并符号化工具(Hot Spot Analysis with Rendering):
进行热点分析工具相同的操作并对分析结果的Gi字段进行符号化,生成一个存储了符号化方案的layer文件。
三、度量空间分布工具集
1, 中心要素(Central Feature):
查找距其所有要素距离最短的要素。使用该工具查找的是已存在的要素。
2, 方向性分布分析工具(标准差椭圆)(Directional Distribution ---Standard
Deviational Ellipse):
标准差椭圆工具创建一个新的要素类。该要素类包含一个椭圆多边形要素。该要素包含以下属性:椭圆的中心坐标。X、Y方向上的标准距离,也就是椭圆长轴、短
轴的值。以及椭圆的旋转方向。使用椭圆可以概括要素的空间分布,并识别方向的趋势。长轴为空间分布最多的方向,短轴为空间分布最少的方向。
由于标准差椭圆工具会测量所有要素的x、y坐标与其坐标平均值之差的平均值,所以分析结果是基于统计结果而不是目视理解。
该工具主要用于进行空间分布特征的方向性因素判定。比如通过对污染样点数据的分析,找出污染扩散的主要方向。
3, 线性方向均值(Linear Directional Mean):
该工具要求输入要素为线要素。计算线要素的平均走向。所有的线都被看作从起点到终点两点构成的线,线内结点都被忽略。方向均值的计算结果都是从正东开始,以逆时针旋转的角度来表示的。还包括平均长度等统计信息。
该工具只要用来统计变化要素的主要发展趋势。比如统计一段时期的洋流运动方向,来确定洋流的主要运动方向或趋势。
4, 均值中心(Mean Center):
该工具计算所有输入要素的平均x,y坐标,生成一个新的要素。往往通过目视得出的结论是不准确的,比如发生事件比较频繁的地区经常发生空间上的重叠,而目
视判断会忽略这些信息,从而造成判断错误。而通过使用工具,会对每个要素进行计算,得出来的中心才是真正的均值中心,是可信的结果。
5, 标准距离(Standard Distance):
对密集分布的测量可以提供一个表示中心周围要素离散度的值。这个值就是标准距离。通过计算要素的标准距离,生成一个以标准距离为半径的圆,来概括密集分布
特征。该圆覆盖了要素的大部分。标准距离越大,说明要素的分布越分散。如果数据中存在差异较大的极值,会对结果产生比较大的影响。
四、辅助工具集:
1, 计算面积(Calculate Areas)。
计算多边形的面积。提供其他某些工具所需的面积参数。例如:平均最邻近距离工具对于统计区域的面积是敏感的。大多数情况需要指定分析区域的面积。即可从该工具获得该参数。
2, 事件收集(Collect Events)。
收集同一空间位置时间发生的次数。比如同一地区犯罪发生次数,流行病发病次数等等。通常,在进行热点分析的时候,会有选项要求指定一个权重字段,而通过事
件收集工具得到的count字段代表了时间发生的次数,可作为权重字段进行考虑。这种情况适用于对于事件发生情况的统计。比如流行病发病热点地区探索等
等。
3, 收集事件并符号化(Collect Events with Rendering)。
这是一个Model工具。进行与事件收集工具相同的工作并对其结果进行符号化,符号化字段为count字段。
4, 对count字段符号化工具(Count Rendering)。
事件收集并符号化工具中已使用到该工具,只不过在model里进行了调用而已。该工具用于对count字段进行符号化并生成Layer文件。
5, 将要素属性值输出为Ascii码(Export Feature Attribute to Ascii)。
该工具会将要素的x,y坐标及指定的属性值输出为Ascii码文件。
6, Z score值符号化工具(Z Score Rendering)。
对包含z score值字段进行符号化。以达到增强显示效果的目的。
___________________________________________________________
这一篇具体看分析模式工具集中的具体工具,整理这一篇的目的,不是要读者了解每个工具的背后使用了多么高级的算法,运用了多么庞大的公式,而是一起了解这些工具究竟可以为我们研究什么样的空间数据分布模式,当需要探索数据的空间性质时,知道应该如何去应用这些分析工具。

平均最近邻工具通过计算每个要素与其最邻近要素之间的距离来计算最近邻比率。如果最近邻比率小于 1,则表现的模式为聚类。如果指数大于 1,则表现的模式趋向于扩散。
“平均最近邻”工具将返回五个值:观测的平均距离、期望的平均距离、最近邻指数、z 得分和 p 值。
在HTML报告文件中可以更显见的了解数据的趋势:
可能的应用:
- 评估竞争或领地:量化并比较固定研究区域中的多种植物种类或动物种类的空间分布;比较城市中不同类型的企业的平均最近邻距离。
- 监视随时间变化的更改:评估固定研究区域中一种类型的企业的空间聚类中随时间变化的更改。
- 将观测分布与控制分布进行比较:在木材分析中,如果给定全部可收获木材的分布,则您最好将已收获面积图案与可收获面积图案进行比较,以确定砍伐面积是否比期望面积更为聚类。
空间自相关 (Global Moran’s I) 工具同时根据要素位置和要素的属性值来度量空间自相关。在给定一组要素及相关属性的情况下,评估所表达的模式是聚类模式、离散模式还是随机模式。
与平均最近邻工具类似,此工具将返回五个值:Moran’s I 指数、预期指数、方差、z 得分和 p 值。
在使用这个工具的时候,注意以下几点:
可能的应用
- 通过查找距离(即空间自相关最强的位置对应的距离),可为各种空间分析方法确定合适的邻近距离。
- 度量种族或民族分离随时间推移的总体趋势 - 分离程度是逐渐增强还是逐渐减弱?
- 总结某种观点、疾病或趋势随空间和时间变化的传播情况 - 观点、疾病或趋势是保持隔离和集中,还是传播开并变得更加分散?
增量自相关工具会去测量一系列的空间自相关,并且可以创建 Z 得分折线图。Z 得分反映空间聚类的程度,峰值 Z 得分表示聚类最明显的距离。
这些峰值能做什么呢?我们可以将这些峰值作为其他工具(例如热点分析,将来会说到)的必要参数,例如距离范围,距离半径等等。
以下面的数据为例:
我欲研究下面几个城市的人口分布情况:
第一个峰值位于大约 250000 处。当显示多个具有统计显著性的峰值时(例如,本示例数据中有两个峰值),聚类在这些距离处均很明显。选择与感兴趣的分析比例对应的峰值距离,我们通常选择第一个具有统计显著性的峰值。
高/低聚类 (General G) 统计的零假设规定被研究的要素值不存在空间聚类。当返回的 p 值较小且在统计学上显著,则可以拒绝零假设。如果零假设被拒绝,则 z 得分的符号将变得十分重要。如果 z 得分值为正数,则观测的 General G 指数会比期望的 General G 指数要大一些,表明属性的高值将在研究区域中聚类。如果 z 得分值为负数,则观测的 General G 指数会比期望的 General G 指数要小一些,表明属性的低值将在研究区域中聚类。
当存在完全均匀分布的值并且要查找高值的异常空间峰值时,首选高/低聚类(Getis-Ord General G)工具。遗憾的是,高值和低值同时聚类时,它们倾向于彼此相互抵消。如果在高值和低值同时聚类时测量空间聚类,则使用空间自相关工具。
“高/低聚类”工具可返回五个值:General G 观测值、General G 期望值、方差、z 得分以及 p 值。
可能的应用:
- 在访问急症室的次数中查找出现的异常峰值,可能表明在局部或区域的健康问题的爆发。
- 比较在城市中不同种类零售业的空间模式,利用比较购物的方式来了解哪类行业充满竞争性(如汽车经销商)以及哪类行业拒绝竞争(如健康中心/健身房)。
- 汇总空间现象聚类的程度以检查不同时期或不同位置的变化。例如,众所周知的城市及其人口聚类。使用高/低聚类分析时,可以随时间来比较某个城市的人口聚类的程度(城镇发展以及密集度的分析)。
基于 Ripley’s K 函数的多距离空间聚类分析工具是另外一种分析事件点数据的空间模式的方法。Ripley’s K 函数可表明要素质心的空间聚集或空间扩散在邻域大小发生变化时是如何变化的。
如果有兴趣研究要素的聚类/扩散如何相对于不同距离(不同的分析规模)进行变化,可以使用此工具。
地理信息系统 - ArcGIS - 高/低聚类分析工具(High/Low Clustering ---Getis-Ord General G)
标签:创建 success 基础概念 lib proc 最简 model 添加 views
原文地址:http://www.cnblogs.com/sddai/p/6040085.html









