标签:its graph ref depend idf oba spider sim 搜索
单词搜索
【Qword1 and Qword2】 O(x+y)
【Qword1 and Qword2】- 改进: Galloping Search O(2a*log2(b/a))
【Qword1 and not Qword2】 O(m*log2n)
【Qword1 or not Qword2】 O(m+n)
【Qword1 and Qword2 and Qword3 and ...】 O(Total_Length * log2k)
句子搜索
1. Biword Indexes
2. Positional Index --> Proximity Queries
构建过程中的Sort的探索:
Heaps’ law: M = kTb
Zipf’s law: cfi = K/i
思路:基本查询,构建,然后压缩
WILD-CARD QUERIES
(1) Error detection
(2) Error correction
查询似然模型 --> 混合模型:Jelinek-Mercer method
求Query在Md 中出现的概率,然后Ranking.
针对一个Query,某Term是否该出现在文档中呢?
一篇New doc出现,遂统计every Term与该doc的关系,得到Ci。
In degree i 正比于 1/iα , 例如: α = 2.1
1. Number of In Degree.
2. "Flow" Model
精确方式:
Consine Similarity: tf-idf
精确加速:
使用Quick Select:n + k * log(k) : "find top k" + "sort top k"
Threshold Methods - MaxScore Method
模糊加速:
Index Elimination (heuristic function)
3 of 4 query terms
Champion List
Cluster Pruning Method
无序检索结果的评价方法
有序检索结果的评价方法
大目标 --> 小目标
• Text Categorization:
– Classify an entire document
• Information Extraction (IE):
– Identify and classify small units within documents
• Named Entity Extraction (NE):
– A subset of IE
– Identify and classify proper names: "People, locations, organizations"
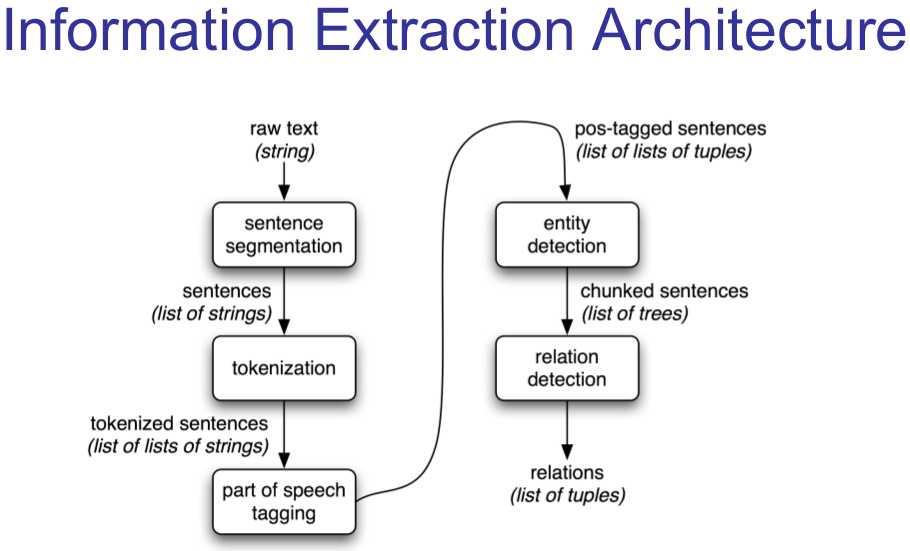
Main tasks
• Named Entity Recognition
• Relation Extraction
Pattern-based Relation Extraction
– Relation extraction and its difficulties
1.
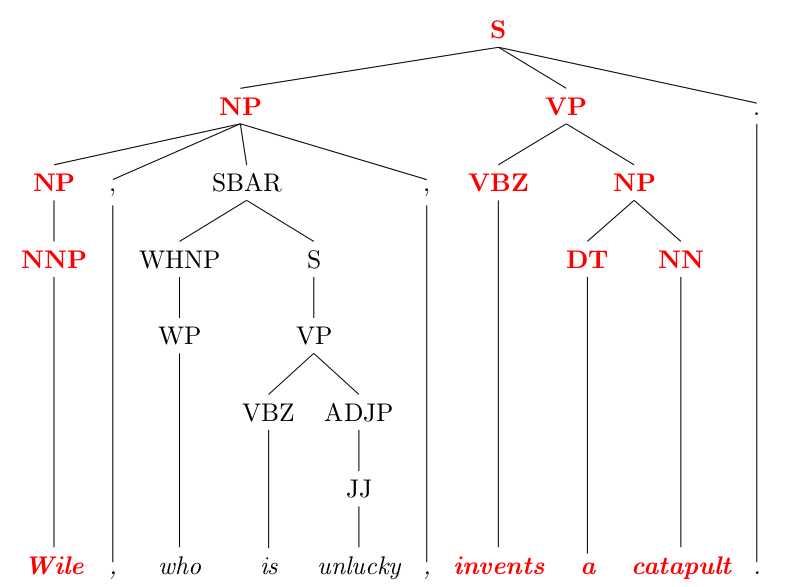
2.

3.

标签:its graph ref depend idf oba spider sim 搜索
原文地址:http://www.cnblogs.com/jesse123/p/6044106.html