标签:protobuf 类型 合并 block 索引 wal ret 区分 pcc
主要内容:
1. HBase协处理器介绍
2. 观察者(Observer)
3. 终端(endpoint)
-------------------------------------------------------------------------------------------------------------------------------------------------------------------
1. HBase协处理器介绍
系统协处理器可以全局导入region server上的所有数据表,表协处理器即是用户可以指定一张表使用协处理器。Hbase协处理器(Coprocessor)有两种类型:Observer Coprocessors 和Endpoint Coprocessor。
前者类似触发器,在特定的事件发生时候触发,后者类似存储过程,执行数据计算。观察者协处理器在很多地方可能用到这些,比如:数据安全权限限制,数据外键参考或者一致性,二级索引,主要类型有:RegionObserver,RegionServerObserver,MasterObserver,WalObserver。
2. 观察者(Observer)
观察者的设计意图是允许用户通过插入代码来重载协处理器框架的upcall方法,而具体的事件触发的callback方法由HBase的核心代码来执行。协处理器框架处理所有的callback调用细节,协处理器自身只需要插入添加或者改变的功能。
以HBase0.92版本为例,它提供了三种观察者接口:
这些接口可以同时使用在同一个地方,按照不同优先级顺序执行.用户可以任意基于协处理器实现复杂的HBase功能层。HBase有很多种事件可以触发观察者方法,这些事件与方法从HBase0.92版本起,都会集成在HBase API中。不过这些API可能会由于各种原因有所改动,不同版本的接口改动比较大,具体参考Java Doc,RegionObserver工作原理如下图所示。
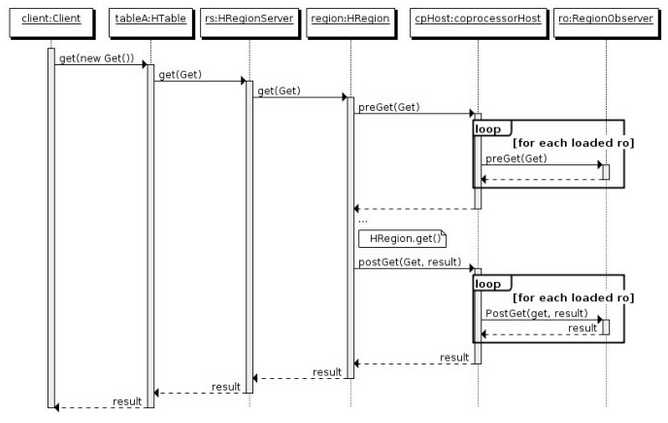
图1 RegionObserver工作原理
3. 终端(endpoint)
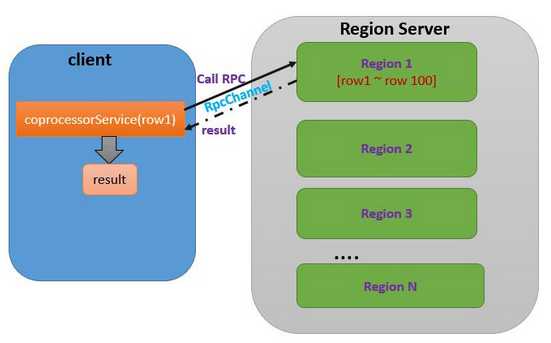
图2 调用单个Region上的协处理器
coprocessorService 方法返回类型为 CoprocessorRpcChannel 的对象,该 RPC 通道连接到由 rowkey 指定的 Region 上,通过这个通道,就可以调用该 Region 上部署的协处理器 RPC。我们已经通过 Protobuf 定义了 RPC Service。调用 Service 的 newBlockingStub() 方法,将 CoprocessorRpcChannel 作为输入参数,就可以得到 RPC 调用的 stub 对象,进而调用远端的 RPC。
代码1 获取单个Region的rowcount
1 long singleRegionCount(String tableName, String rowkey,boolean reCount) 2 { 3 long rowcount = 0; 4 try{ 5 Configuration config = new Configuration(); 6 HConnection conn = HConnectionManager.createConnection(config); 7 HTableInterface tbl = conn.getTable(tableName); 8 //获取 Channel 9 CoprocessorRpcChannel channel = tbl.coprocessorService(rowkey.getBytes()); 10 org.ibm.developerworks.getRowCount.ibmDeveloperWorksService.BlockingInterface service = 11 org.ibm.developerworks.getRowCount.ibmDeveloperWorksService.newBlockingStub(channel); 12 //设置 RPC 入口参数 13 org.ibm.developerworks.getRowCount.getRowCountRequest.Builder request = 14 org.ibm.developerworks.getRowCount.getRowCountRequest.newBuilder(); 15 request.setReCount(reCount); 16 //调用 RPC 17 org.ibm.developerworks.getRowCount.getRowCountResponse ret = 18 service.getRowCount(null, request.build()); 19 20 //解析结果 21 rowcount = ret.getRowCount(); 22 } 23 catch(Exception e) {e.printStackTrace();} 24 return rowcount; 25 }
(2)调用多个 Region 上的协处理器 RPC,不使用 callback
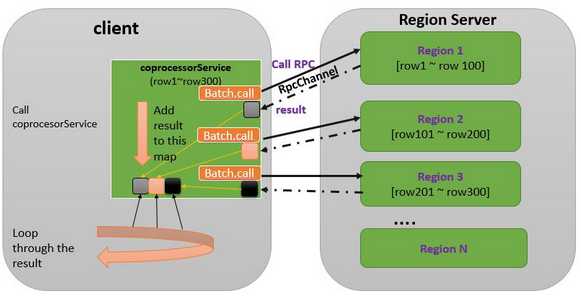
图3 调用多个Region上的协处理器——不使用callback
(3)调用多个 Region 上的协处理器 RPC,使用 callback
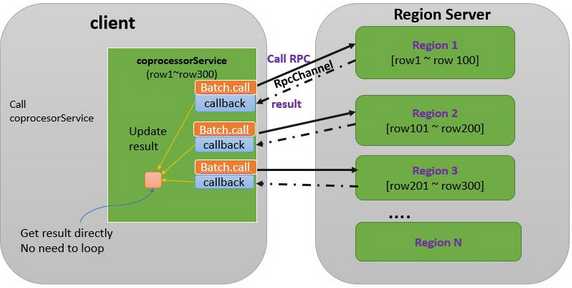
图4 调用多个Region上的协处理器——使用callback
标签:protobuf 类型 合并 block 索引 wal ret 区分 pcc
原文地址:http://www.cnblogs.com/muzili-ykt/p/6056066.html