标签:varnish 性能调优
版本:4.1.3
操作系统:6.6 Centos
参考文档:
http://book.varnish-software.com/4.0/chapters/Examining_Varnish_Server_s_Output.html
https://www.varnish-cache.org/docs/4.1/reference/varnish-counters.html
【调优涉及的监控工具】
varnishstat #实时的数据 上下可以翻动查看各个指标数据
varnishstat -1 #打印统计信息到屏幕上,所有的指标信息 信息更全面
【常见varnish重要指标】
SMA.s0.g_bytes 缓存已经使用的内存 #一般varnish运行时间长 分配的内存都会被耗尽
SMA.s0.g_space 缓存总共内存还剩余多少
注:内存的分配给缓存多少,只有varnish重启才能生效,reload是不生效的,意味着重启varnish所有的缓存都要重新丢失,所以varnish分配多少内存要考虑好。运行期间就不能动态调整了。
LRU nuked objects :代表缓存可使用的内存以达上线而不得不移除的对象个数
LRU moved objects :代表LRU策略被移动的对象个数(移动 因为LRU算法原理有关,不是移除)
注意:最重要的指标是 nuked(不是move),它告诉我们有多少个对象从缓存中移除,基于LRU算法。如果这个数据增长很快,你就需要考虑增大你的内存。
MAIN.thread_queue_len 展示了当前回话等待一个线程的数量。
MAIN.sess_queued 包含的回话数量被等待在队列中的。原因是没有可用的线程此刻。考虑去增加thread_pool_min参数。 这个数目是静态的,一般是启动就生成的,所以在中途过程中发现 再去调整thread_pool_min的值,是没用的。不过不影响,只要不增加。
MAIN.sess_droppedCounts how many times sessions are dropped because varnishd hits the maximum thread queue length. You may consider to increase the thread_queue_limit Varnish parameter as a solution to drop less sessions. 这个值应该为0
注意:thread_queue_len 反应当前线程的压力,一般线程足够这个值应该为0。 sess_drop 正常情况下应该为0.
MAIN.n_object – Number of object structs made。缓存中的对象数目。
MAIN.n_expired 过期的对象数目 和设置的缓存TTL值相关,如果你设置了非200状态的TTL时间很短如30秒。而其中的302 304 比较多。这个数据就会增长比较快。
线程: 这个需要进行压测在决定设置什么值更适合。
MAIN.threads_limited: 多少个线程需要去创建,但是不可能,因为thread_pool_max被设置了。所以这个值一般为0.如果不为0 就是有线程不够,但是又不能去创建。
threads limited" is the number of times Varnish wanted to create a worker thread, but wasn‘t able to because of the thread_pool_max setting. This should also be 0
MAIN.threads 当前工作的线程数
thread_pools 2 [pools] (default
thread_pools:用来设置线程池的数量,一般认为这个值和系统CPU的数目相同最好,设置过多的pools,varnish的并发处理能力会更强,但是也会消耗更多的CPU和内存
thread_pool_min 50 [threads]
thread_pool_min:用来设置每个pool的最小threads数,当pool接收到可用的请求后,就会将请求分配给空闲的threads来处理。
thread_pool_max:表示每个pool对应的threads数总和的最大值,此值不能太大,可以设置为系统峰值的90%左右即可,设置过大,会导致进程hung住。
hread_pool_timeout:表示threads的超时过期时间,当threads数大于thread_pool_min设定值时,threads空闲超过thread_pool_timeout设定的时间时,thread就会被移除释放掉。这个参数不是很重要
The thread_pool_timeout is how long a thread is kept around when there is no work for it before it is removed. This only applies if you have more threads than the minimum, and is rarely changed.
Another less important parameter is the thread_pool_fail_delay, which defines how long to wait after the operating system denied us a new thread before we try again.
lru_interval 20 [seconds]
重新设置pool
param.set thread_pools 4
重新设置最大的线程数
param.set thread_pool_max 5000
"Backend connections recycled" is increased whenever we have a keep-alive connection that is put back into the pool of connections. It has not yet been used, but it might be, unless the backend closes it.
"Backend connections reused" is increased whenever we actually reuse a connection from the pool of backend connections.
【扩展知识】
参考: http://flychao88.iteye.com/blog/1977653
1 LRU算法
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
最常见的实现是使用一个链表保存缓存数据,详细算法实现如下:
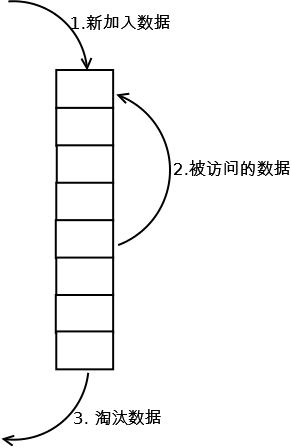
1. 新数据插入到链表头部;
2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
3. 当链表满的时候,将链表尾部的数据丢弃。
【命中率】
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
【复杂度】
实现简单。
【代价】
命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
本文出自 “燕子李三” 博客,请务必保留此出处http://cuidehua.blog.51cto.com/5449828/1871924
标签:varnish 性能调优
原文地址:http://cuidehua.blog.51cto.com/5449828/1871924