标签:use 垃圾 解决方案 溢出 roo 缺点 过程 serial auto
标签(空格分隔): Java
要想深入了解Java的GC(Garbage Collection),我们应该先探寻如下三个问题:
Definition: Program itself finds and collects memory which is useless. It is a form of automatic memory management which doesn‘t need programmers release memory.
Java中为什么会有GC机制呢?
我们知道,内存运行时JVM会有一个运行时数据区来管理内存。它主要包括5大部分:程序计数器(Program Counter Register)、虚拟机栈(VM Stack)、本地方法栈(Native Method Stack)、方法区(Method Area)、堆(Heap).
而其中程序计数器、虚拟机栈、本地方法栈是每个线程私有的内存空间,随线程而生,随线程而亡。例如栈中每一个栈帧中分配多少内存基本上在类结构去诶是哪个下来时就已知了,因此这3个区域的内存分配和回收都是确定的,无需考虑内存回收的问题。
但方法区和堆就不同了,一个接口的多个实现类需要的内存可能不一样,我们只有在程序运行期间才会知道会创建哪些对象,这部分内存的分配和回收都是动态的,GC主要关注的是这部分内存。
总而言之,GC主要进行回收的内存是JVM中的方法区和堆;
涉及到多线程(指堆)、多个对该对象不同类型的引用(指方法区),才会涉及GC的回收。
在面试中经常会碰到这样一个问题(事实上笔者也碰到过):如何判断一个对象已经死去?
很容易想到的一个答案是:对一个对象添加引用计数器。每当有地方引用它时,计数器值加1;当引用失效时,计数器值减1.而当计数器的值为0时这个对象就不会再被使用,判断为已死。是不是简单又直观。然而,很遗憾。这种做法是错误的!(面试时可千万别这样回答哦,我就是不假思索这样回答,然后就。。)为什么是错的呢?事实上,用引用计数法确实在大部分情况下是一个不错的解决方案,而在实际的应用中也有不少案例,但它却无法解决对象之间的循环引用问题。比如对象A中有一个字段指向了对象B,而对象B中也有一个字段指向了对象A,而事实上他们俩都不再使用,但计数器的值永远都不可能为0,也就不会被回收,然后就发生了内存泄露。。
所以,正确的做法应该是怎样呢?
在Java,C#等语言中,比较主流的判定一个对象已死的方法是:可达性分析(Reachability Analysis).
所有生成的对象都是一个称为"GC Roots"的根的子树。从GC Roots开始向下搜索,搜索所经过的路径称为引用链(Reference Chain),当一个对象到GC Roots没有任何引用链可以到达时,就称这个对象是不可达的(不可引用的),也就是可以被GC回收了。如下图所示:
[可达性算法判定对象是否可回收][1]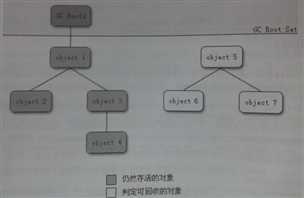
无论是引用计数器还是可达性分析,判定对象是否存活都与引用有关!那么,如何定义对象的引用呢?
我们希望给出这样一类描述:当内存空间还够时,能够保存在内存中;如果进行了垃圾回收之后内存空间仍旧非常紧张,则可以抛弃这些对象。所以根据不同的需求,给出如下四种引用,根据引用类型的不同,GC回收时也会有不同的操作:
What部分我们已经提到,GC主要回收的是堆和方法区中的内存,而上面的How主要是针对对象的回收,他们一般位于堆内。那么,方法区中的东西该怎么回收呢?
关于方法区中需要回收的是一些废弃的常量和无用的类。
总而言之,对于堆中的对象,主要用可达性分析判断一个对象是否还存在引用,如果该对象没有任何引用就应该被回收。而根据我们实际对引用的不同需求,又分成了4中引用,每种引用的回收机制也是不同的。
对于方法区中的常量和类,当一个常量没有任何对象引用它,它就可以被回收了。而对于类,如果可以判定它为无用类,就可以被回收了。
分为两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。
缺点:效率问题,标记和清除两个过程的效率都不高;空间问题,会产生很多碎片。
将可用内存按容量划分为大小相等的两块,每次只用其中一块。当这一块用完了,就将还存活的对象复制到另外一块上面,然后把原始空间全部回收。高效、简单。
缺点:将内存缩小为原来的一半。
标记过程与标记-清除算法过程一样,但后面不是简单的清除,而是让所有存活的对象都向一端移动,然后直接清除掉端边界以外的内存。
单线程收集器,表示在它进行垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束。"Stop The World".
实际就是Serial收集器的多线程版本。
该收集器比较关注吞吐量(Throughout)(CPU用于用户代码的时间与CPU总消耗时间的比值),保证吞吐量在一个可控的范围内。
CMS收集器是一种以获得最短停顿时间为目标的收集器。
从JDK1.7 Update 14之后的HotSpot虚拟机正式提供了商用的G1收集器,与其他收集器相比,它具有如下优点:并行与并发;分代收集;空间整合;可预测的停顿等。
本部分主要分析了三种不同的垃圾回收算法:Mark-Sweep, Copy, Mark-Compact. 每种算法都有不同的优缺点,也有不同的适用范围。而JVM中对垃圾回收器并没有严格的要求,不同的收集器会结合多个算法进行垃圾回收。
Java技术体系中所提倡的自动内存管理最终可以归结为自动化的解决2个问题:给对象分配内存以及回收分配给对象的内存。
大多数情况下,对象在新生代Eden区分配。当Eden区没有足够的内存时,虚拟机将发起一次Minor GC。
大对象是指需要大量连续内存空间的Java对象(例如很长的字符串以及数组)。
JVM为每个对象定义一个对象年龄计数器。
本篇博客主要根据Java的GC原理,从What,When,How三方面对如何进行垃圾回收做了分析。
简而言之:
What -- 堆和方法区;
When -- 已死的对象(引用无法可达);
How -- 标记-清除-整理-复制算法。
关于GC问题,牢牢把握住这三个问题,然后进行发散性思维,便可以很好的掌握这部分内容了。
最后对Java对对象的内存分配策略进行了介绍:新生代Eden区 -- Survivor区 -- 老年代
GC(垃圾回收)
标签:use 垃圾 解决方案 溢出 roo 缺点 过程 serial auto
原文地址:http://www.cnblogs.com/jinlinFighting/p/6062192.html