标签:amp use try orb nbsp 技术分享 span process cep

?start=0&type=T
def get_html(url): """ 抓取网页 """ cj = http.cookiejar.CookieJar() opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj)) opener.addheaders = [(‘User-Agent‘, ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.101 Safari/537.36‘), (‘Cookie‘, ‘4564564564564564565646540‘)] urllib.request.install_opener(opener) try: while True: page = urllib.request.urlopen(url) html = page.read().decode("utf-8") page.close() anti_spider = re.findall(r‘403 Forbidden‘, html) if anti_spider: print("反爬虫了,休息10分钟...") time.sleep(600) else: return html except Exception as e: print(e) sys.exit()
def get_books_info(html): """ 获得一页上面所有书的信息 """ books = [] one_page_books = re.findall(r‘href="(https://book\.douban\.com/subject/\d+/)" title="(.*?)"‘, html) for url, name in one_page_books: one_book_html = get_html(url) # print one_book_html author, score = get_book_info(one_book_html) # print author, score if not author and not score: break name = "《" + name + "》" print(‘{"name": %s, "author": %s, "score": %s, "url": %s}‘ % (name, author, score, url)) books.append({"name": name, "author": author, "score": score, "url": url}) # print("别爬太快,休息一下") time.sleep(3) return books
def get_book_info(html): """ 获得一本书的评分和作者 """ try: score = re.findall(r‘property="v:average"> (.*?) </strong>‘, html)[0] author = re.findall(r‘<span class="pl"> 作者</span>[\w\W]*?<a class="" href=".*?">(.*?)</a>‘, html)[0] return author, score except Exception as e: print("评分和作者出了点小问题:") print(e) return "", ""
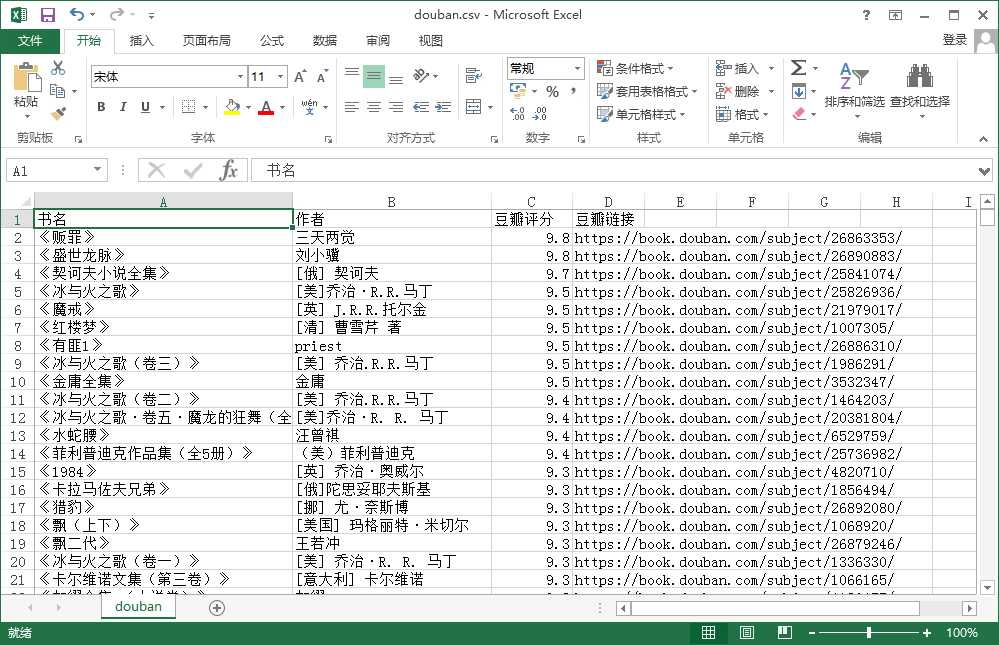
def main(): page = 0 books = [] while True: url = "https://book.douban.com/tag/%%E5%%B0%%8F%%E8%%AF%%B4?start=%s&type=T" % str(page) html = get_html(url) one_page_books = get_books_info(html) books.extend(one_page_books) if len(one_page_books) == 0: print("好啦只有这些书啦~") break page += 20 # 有的书评价人数太少,没有分数,怕信息不全,补全一下 for b in books: b["author"] = b["author"] or "(佚名)" b["score"] = b["score"] or "0.0" # 排序 books.sort(key=lambda x: float(x["score"]), reverse=True) # 保存书籍信息 with open("douban.csv", "w", encoding="gbk", errors="ignore") as f: line_template = "%(name)s,%(author)s,%(score)s,%(url)s\n" f.write(line_template % ({"name": "书名", "author": "作者", "score": "豆瓣评分", "url": "豆瓣链接"})) for book in books: f.write(line_template % book)
标签:amp use try orb nbsp 技术分享 span process cep
原文地址:http://www.cnblogs.com/anpengapple/p/6062833.html