标签:svd分解 src 改进 csdn amp box 连接 长度 details
把r-cnn系列总结下,让整个流程更清晰。
整个系列是从r-cnn至spp-net到fast r-cnn再到faster r-cnn。
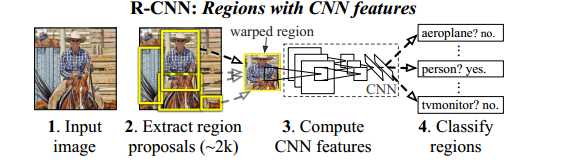
RCNN
输入图像,使用selective search来构造proposals(大小不一,需归一化),输入到CNN网络来提取特征,
并根据特征来判断是什么物体(分类器,将背景也当做一类物体),最后是对物体的区域(画的框)进行微调(回归器)。
由下面的图可看出,RCNN分为四部分,ss(proposals),CNN,分类器,回归器,这四部分是相对独立的。改进的思路就是
把分类器和回归器放在一起训练,称为joint learning(fast r-cnn),更近一步,把ss也加入其中,成为一个更大的网络(faster)。
SPP
在之后的fast和faster中,SPP都非常重要,其主要解决网络输入的尺寸固定这个问题。主要思想就是在全连接层之前,用不同尺度
的pooling来pooling出固定尺度大小的feature map,再送入全连接层。
SPP真正重要的是在检测中的应用。RCNN提取2K个proposals再去计算特征,这些proposals有大量的重复,因此计算很耗时。SPP
只提取整张图像特征一次,再在特征图对应的候选窗口上应用spatial pyramid pooling构造出固定长度的,这就大大节省了计算量。
现在的问题是,对何将某个proposals对应到相应的特征图上去呢(这部分我没看明白,下面为博友的看法)?
通过增加pad,使得卷积后得到的区域与原区域是一一对应的。如果增加stride的话,就相当与原图先进行卷积再sampling,还是
一一对应的,就这样原图的某个区域就可以通过除以网络的所有stride来映射到conv5后去区域。
FAST RCNN
提出了RoI层:SPP是将特征pooling成多个固定尺度(eg,16+4+1=21),而RoI固定到一个尺度(6*6)。网络结构中,将poolings5
替换成RoI。
将softmax换成两个分支:一个是对分类的softmax,一个是对bounding-box的regression。输入有两个,一个是整张图片,一个是proposals。
并且采用的是联合训练。
训练方式:一个batch训练两张图片,每张图片有64个RoIs。
SVD加速:检测时花在全连接上的时间很多,通过SVD分解变为两个全连接层,减少计算量。
FASTER RCNN
将selective search这样的算法整合到深度网络中,共享卷积计算,解决其速度慢的问题,因此论文的关键在RPN的设计和训练。
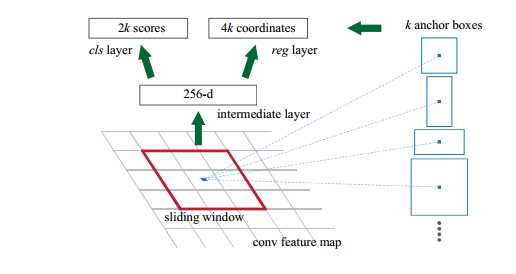
RPN的网络结构如图所示,和SPP类似,在特征图上进行滑窗。如何训练出一个网络,来替代selective search的功能呢?
先通过SPP根据一一对应的点从conv5映射回原图,根据设计不同的固定初始尺度训练一个网络,就是给它大小不同(但设计固定)的region图,
然后根据与ground truth的覆盖率给它正负标签,让它学习里面是否有object即可。这个网络大致判断是否有物体及位置,剩下的部分交给其余的
网络。在这期间,卷积特征是共享的,因此可以省时。
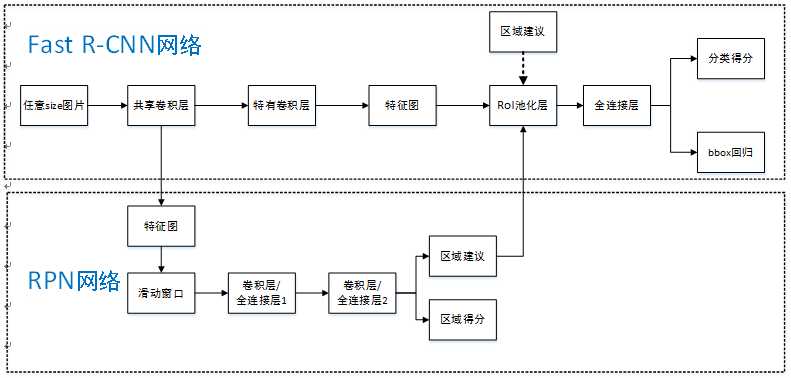
这是大致流程,实际上整个框架很复杂,有很多细节需要学习,这也在以后的代码学习中去完善。
参考:http://blog.csdn.net/xyy19920105/article/details/50817725
http://closure11.com/rcnn-fast-rcnn-faster-rcnn%E7%9A%84%E4%B8%80%E4%BA%9B%E4%BA%8B/
r-cnn学习系列(三):从r-cnn到faster r-cnn
标签:svd分解 src 改进 csdn amp box 连接 长度 details
原文地址:http://www.cnblogs.com/573177885qq/p/6072422.html