标签:配置 import one 分享 tor 完整性 schedule signal aaa
环境极其恶劣情况下:
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SQLContext}
import org.apache.spark.sql.hive.HiveContext
val sqlContext = new HiveContext(sc)
val sql = sqlContext.sql("select * from ysylbs9 ").collect
中间发生报错:
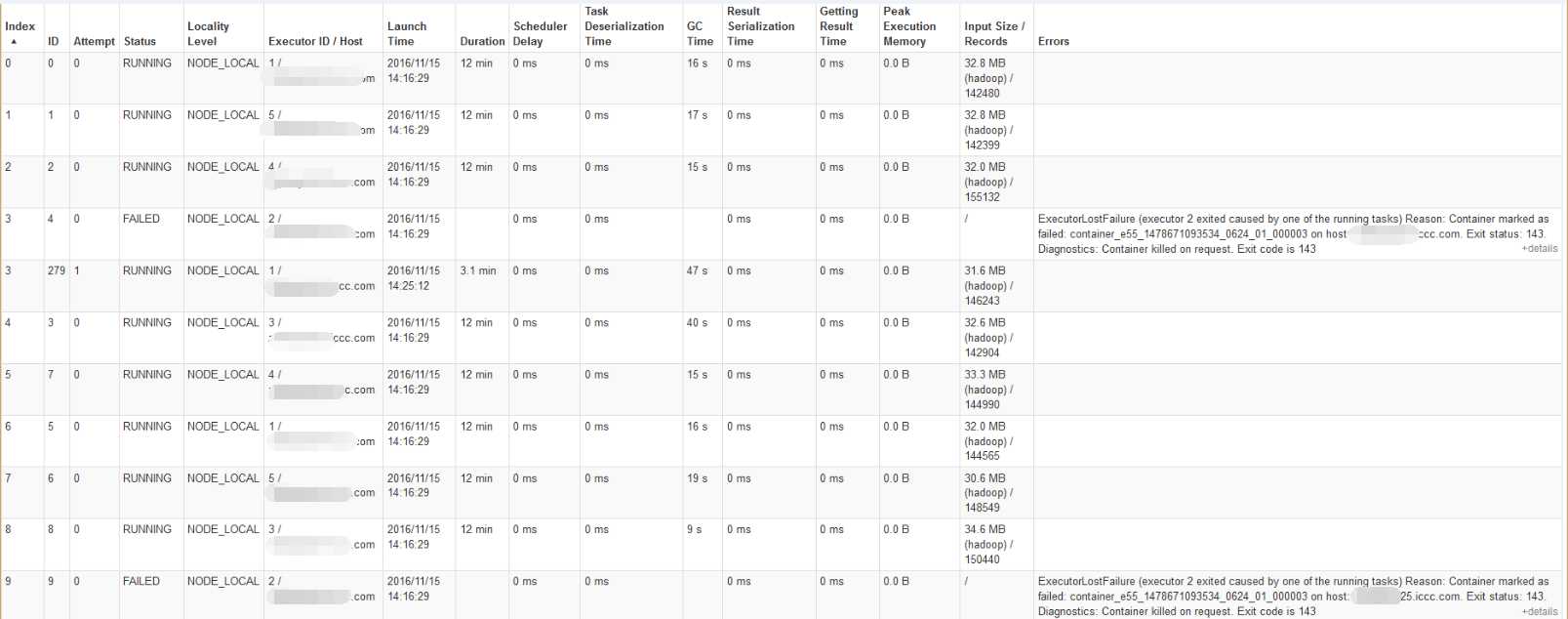
cluster.YarnScheduler: Lost executor 2 on zdbdsps025.iccc.com: Container marked as failed: container_e55_1478671093534_0624_01_000003 on host: zdbdsps025.iccc.com. Exit status: 143. Diagnostics: Container killed on request. Exit code is 143
Container exited with a non-zero exit code 143
Killed by external signal
是因为yarn管理的某个节点掉了,所以spark将任务移至其他节点执行:
16/11/15 14:24:28 WARN scheduler.TaskSetManager: Lost task 224.0 in stage 0.0 (TID 224, zdbdsps025.iccc.com): ExecutorLostFailure (executor 2 exited caused by one of the running tasks) Reason: Container marked as failed: container_e55_1478671093534_0624_01_000003 on host: zdbdsps025.iccc.com. Exit status: 143. Diagnostics: Container killed on request. Exit code is 143
Container exited with a non-zero exit code 143
Killed by external signal
16/11/15 14:24:28 INFO cluster.YarnClientSchedulerBackend: Asked to remove non-existent executor 2
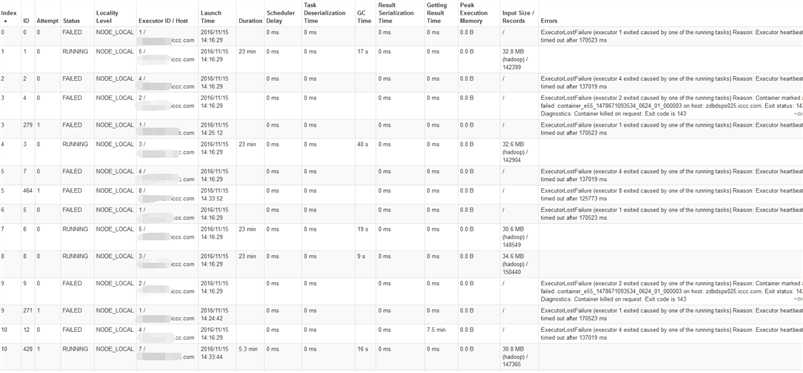
中间又报错:
16/11/15 14:30:43 WARN spark.HeartbeatReceiver: Removing executor 6 with no recent heartbeats: 133569 ms exceeds timeout 120000 ms
16/11/15 14:30:43 ERROR cluster.YarnScheduler: Lost executor 6 on zdbdsps027.iccc.com: Executor heartbeat timed out after 133569 ms
每个task 都超时了
16/11/15 14:30:43 WARN scheduler.TaskSetManager: Lost task 329.0 in stage 0.0 (TID 382, zdbdsps027.iccc.com): ExecutorLostFailure (executor 6 exited caused by one of the running tasks) Reason: Executor heartbeat timed out after 133569 ms
DAGScheduler发现Executor 6 也挂了,于是将executor移除
16/11/15 14:30:43 INFO scheduler.DAGScheduler: Executor lost: 6 (epoch 1)
16/11/15 14:30:43 INFO storage.BlockManagerMasterEndpoint: Trying to remove executor 6 from BlockManagerMaster.
16/11/15 14:30:43 INFO storage.BlockManagerMasterEndpoint: Removing block manager BlockManagerId(6, zdbdsps027.iccc.com, 38641)
16/11/15 14:30:43 INFO storage.BlockManagerMaster: Removed 6 successfully in removeExecutor
16/11/15 14:30:43 INFO cluster.YarnClientSchedulerBackend: Requesting to kill executor(s) 6
然后移至其他节点,随后又发现RPC出现问题
16/11/15 14:32:58 ERROR server.TransportRequestHandler: Error sending result RpcResponse{requestId=4735002570883429008, body=NioManagedBuffer{buf=java.nio.HeapByteBuffer[pos=0 lim=47 cap=47]}} to zdbdsps027.iccc.com/172.19.189.53:51057; closing connection
java.io.IOException: 断开的管道
at sun.nio.ch.FileDispatcherImpl.write0(Native Method)
at sun.nio.ch.SocketDispatcher.write(SocketDispatcher.java:47)
at sun.nio.ch.IOUtil.writeFromNativeBuffer(IOUtil.java:93)
Spark是移动计算而不是移动数据的,所以由于其他节点挂了,所以任务在数据不在的节点,再进行拉取,由于极端情况下,环境恶劣,通过namenode知道数据所在节点位置,spark依旧会去有问题的节点fetch数据,所以还会报错 再次kill掉,由于hadoop是备份三份数据的,spark通过会去其他节点拉取数据。随之一直发现只在一个节点完成task. 最终问题查找,yarn的节点挂了,
下面是部分代码调试:
import org.slf4j.{Logger, LoggerFactory}
import java.util.{Calendar, Date, GregorianCalendar}
import algorithm.DistanceCalculator
import org.apache.hadoop.hbase.{CellUtil, HBaseConfiguration}
import org.apache.hadoop.hbase.client.{HTable, Scan}
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.protobuf.ProtobufUtil
import org.apache.hadoop.hbase.util.{Base64, Bytes}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext}
import org.slf4j.{Logger, LoggerFactory}
import scala.collection.mutable.ArrayBuffer
case class LBS_STATIC_TABLE(LS_certifier_no: String,LS_location: String,LS_phone_no: String,time: String)
该case class 作为最终注册转换为hive表
val logger: Logger = LoggerFactory.getLogger(LbsCalculator.getClass)
//从hbase获取数据转换为RDD
def hbaseInit() = {
val tableName = "EVENT_LOG_LBS_HIS"
val conf = HBaseConfiguration.create()
// conf.addResource("hbase-site.xml ")
val HTable = new HTable(conf, tableName)
HTable
}
def tableInitByTime(sc : SparkContext,tablename:String,columns :String,fromdate: Date,todate:Date):RDD[(ImmutableBytesWritable,Result)] = {
val configuration = HBaseConfiguration.create()
//这里上生产注释掉,调试时可打开,因为提交yarn会自动加载yarn管理的hbase配置文件
configuration.addResource("hbase-site.xml")
configuration.set(TableInputFormat.INPUT_TABLE, tablename)
val scan = new Scan
//这里按timestrap进行过滤,比用scan过滤器要高效,因为用hbase的过滤器其实也是先scan全表再进行过滤的,效率很低。
scan.setTimeRange(fromdate.getTime,todate.getTime)
val column = columns.split(",")
for(columnName <- column){
scan.addColumn("f1".getBytes, columnName.getBytes)
}
val hbaseRDD = sc.newAPIHadoopRDD(configuration, classOf[TableInputFormat], classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable], classOf[org.apache.hadoop.hbase.client.Result])
System.out.println(hbaseRDD.count())
hbaseRDD
}
//这里写了一种过滤器方法,后续将所有hbase过滤器方法写成公共类
val filter: Filter = new RowFilter(CompareFilter.CompareOp.GREATER_OR_EQUAL, new SubstringComparator("20160830"))
scan.setFilter(filter)
//这里要注意,拿到的数据在1个partition中,在拿到后需要进行repartition,因为如果一个task能够承载比如1G的数据,那么将只有1个patition,所以要重新repatition加大后续计算的并行度。这里repatition的个数需要根据具体多少数据量,进行调整,后续测试完毕写成公共方法。通过Rdd map 转换为(身份证号,经纬度坐标,手机号码,时间)这里就将获取的数据repatition了
val transRDD = hbRDD.repartition(200).map{ p => {
val id =Bytes.toString(p._2.getValue("f1".getBytes, "LS_certifier_no".getBytes))
val loc = Bytes.toString(p._2.getValue("f1".getBytes, "LS_location".getBytes))
val phone = Bytes.toString(p._2.getValue("f1".getBytes, "LS_phone_no".getBytes))
val rowkey = Bytes.toString(p._2.getValue("f1".getBytes, "rowkey".getBytes))
val hour = rowkey.split("-")(2).substring(8,10)
(id,loc,phone,hour)
}
}
//这里进行了字段过滤,因为很多时候数据具有不完整性,会导致后续计算错误
val calculateRDD = transRDD.repartition(200).filter(_._1 != null).filter(_._2 != null).filter(_._3 != null).filter(_._4 !=null)
需要注意的是reduceByKey并不会在监控页面单独为其创建监控stage,所以你会发现与之前的map(filer)的stage中,同时监控中会发现已经进行了repartition

.reduceByKey(_ + _)
//进行hiveContext对象的创建,为后续进行表操作做准备。
val hiveSqlContext = HiveTableHelper.hiveTableInit(sc)
def hiveTableInit(sc:SparkContext): HiveContext ={
val sqlContext = new HiveContext(sc)
sqlContext
}
//传入之前数据分析过的结果,生成表
val hiveRDD = hRDD.map(p => LBS_STATIC_TABLE(p._1,p._2,p._3,p._4,p._5)
//创建DataFrame并以parquet格式保存为表。这里需要注意的是,尽量少的直接用hiveSqlContext.sql()直接输入sql的形式,因为这样还会走spark自己的解析器。需要调用RDD的DataFrame API会加快数据处理速度。后续整理所有算子。
val hiveRDDSchema = hiveSqlContext.createDataFrame(hiveRDD)
val aaa = hiveRDDSchema.show(10)
hiveSqlContext.sql("drop table if exists " + hivetablename)
hiveRDDSchema.registerTempTable("LBS_STATIC_TABLE")
hiveRDDSchema.write.format("parquet").saveAsTable(hivetablename)
标签:配置 import one 分享 tor 完整性 schedule signal aaa
原文地址:http://www.cnblogs.com/yangsy0915/p/6076098.html