标签:pca cti 学习 求导 a算法 处理 统一 com 公式
PCA目的:这里举个例子,如果假设我有m个点,{x(1),...,x(m)},那么我要将它们存在我的内存中,或者要对着m个点进行一次机器学习,但是这m个点的维度太大了,如果要进行机器学习的话参数太多,或者说我要存在内存中会占用我的较大内存,那么我就需要对这些个点想一个办法来降低它们的维度,或者说,如果把这些点的每一个维度看成是一个特征的话,我就要减少一些特征来减少我的内存或者是减少我的训练参数。但是要减少特征或者说是减少维度,那么肯定要损失一些信息量。这就要求我在减少特征或者维度的过程当中呢,尽可能少的损失信息量,这就是PCA算法的目的。
也就是说,对于我的每一个点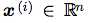 我要找到一个新的表达形式
我要找到一个新的表达形式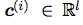 ,也相当于找到一个函数,让f(x)=c。
,也相当于找到一个函数,让f(x)=c。
对于恢复来说,我们这里选择最简单的矩阵相乘的形式让我们的新的表达c变回n维。即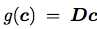 ,这里
,这里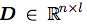 。
。
这里我们加一个约束,那就是D的列向量互相时间是正交的(注意:如果不是l=n的情况,D是不能说成是正交矩阵的)。
接下来我们就要将我们的想法转变为可以实施的算法了。
我们都知道在机器学习中,有一种函数叫做代价函数,英文是cost function, 这个函数的作用就是用来评估你模型的输入和输出之间的差距的。如果你的模型输出和输入的差距越大,这个cost function的值就越大。
我们借用这样一个思想,如果我要找到一个可以尽可能损失信息的c的表达,那我就让g(c)尽可能的和x相同,也就是构造了一个代价函数,我们的目的就是让这个代价函数的值变成最小。数学表达式如下:
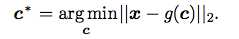
我们这里将这个欧几里得距离加上一个平方,我的理解是方便计算,反正增减性啊都是一样的。
那我们的表达式就变成了这样:
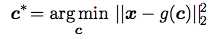
等式右边这一项等于:



这里 是因为x和g(c)都是n维向量,
是因为x和g(c)都是n维向量, 的结果是一个标量,就是一个数,转置自然等于自身啦。
的结果是一个标量,就是一个数,转置自然等于自身啦。
那么现在我们的问题变成了这样:![]()
然后我们把g(c)带入公式中:
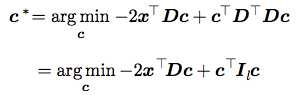
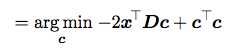
还记得D的约束吗?D的列向量相互之间是正交的,所以DTD=I。
那么到现在为止,我就可以得到我这个式子的结果了,对上面这个表达式对C求导:
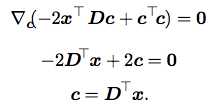
现在我们发现,要想对x进行PCA处理,我们只需要找到这个矩阵D,然后让它的转置乘以X就好了。
即PCA和解码的过程就是: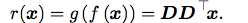
那么现在我们来算这个矩阵D。
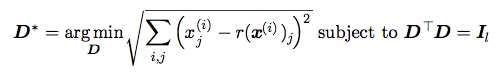
还是根据代价函数的思想,我们得到了上述公式。
为了得到这个算法,我们首先考虑最简单的l=1的情况。也就是说,D中只包含了一个向量d。
这样我们得到: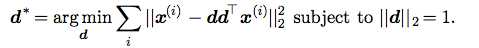
我们将这个公式美化一下: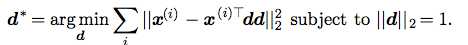
然后我们将所有的x点都带入进去,统一用X表达,X就是一个m*n的矩阵。
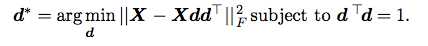
经过一个等价变化我们得到了有关于矩阵的迹的表达式:
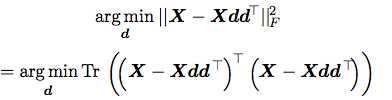
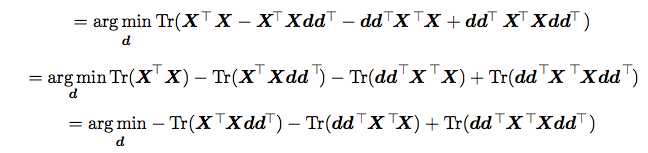
这中间我们去掉了与d无关的项。
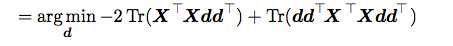
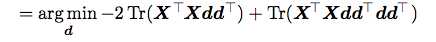
然后我们进行一下化简:
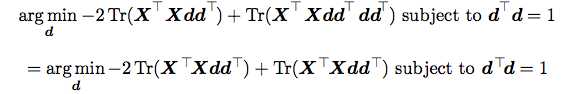
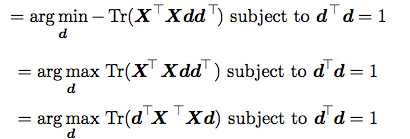
那现在这个问题就可以根据特征值来求解了。得到的d就是XTX的最大的特征值对应的特征向量。
那么对于l>1的情况,DD就是最大l个特征值对应的特征向量的组合。
参考自:Deep Learning 。作者:Yoshua Bengio, Ian Goodfellow, Aaron Courville
标签:pca cti 学习 求导 a算法 处理 统一 com 公式
原文地址:http://www.cnblogs.com/cyq041804/p/6079104.html