标签:target alt case 硬件 oltp open 理论 save cut
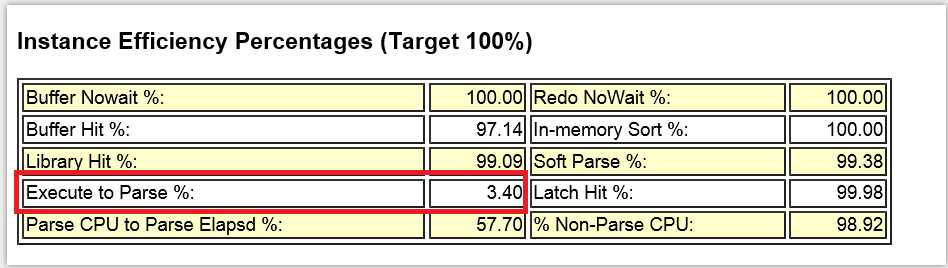
Execute to Parse
指标反映了执行解析比 其公式为 1-(parse/execute) , 目标为100% 及接近于只 执行而不解析
在oracle中解析往往是执行的先提工作,但是通过游标共享 可以解析一次 执行多次, 执行解析可能分成多种场景:
1.hard coding => 硬编码代码 硬解析一次 ,执行一次, 则理论上其执行解析比 为 1:1 ,则理论上Execute to Parse =0 极差,且soft parse比例也为0%
2.绑定变量但是仍软解析=》 软解析一次,执行一次 , 这种情况虽然比前一种好 但是执行解析比(这里的parse,包含了软解析和硬解析)仍是1:1, 理论上Execute to Parse =0 极差, 但是soft parse比例可能很高
3. 使用 静态SQL、动态绑定、session_cached_cursor、open cursors等技术实现的 解析一次,执行多次, 执行解析比为N:1, 则 Execute to Parse= 1- (1/N) 执行次数越多 Execute to Parse越接近100% ,这种是我们在OLTP环境中喜闻乐见的! 通俗地说 soft parse反映了软解析率, 而软解析在oracle中仍是较昂贵的操作, 我们希望的是解析1次执行N次,如果每次执行均需要软解析,那么虽然soft parse%=100% 但是parse time仍可能是消耗DB TIME的大头。 Execute to Parse反映了 执行解析比,Execute to Parse和soft parse% 都很低 那么说明却是没有绑定变量 , 而如果 soft parse% 接近99% 而Execute to Parse 不足90% 则说明没有执行解析比低, 需要通过 静态SQL、动态绑定、session_cached_cursor、open cursors等技术减少软解析。

————————————————————————————————————————————————————————————————
估测shared_pool大小。
SELECT ‘Shared Pool‘ component,shared_pool_size_for_estimate estd_sp_size,
estd_lc_time_saved_factor parse_time_factor,
CASE
WHEN current_parse_time_elapsed_s + adjustment_s < 0
THEN 0
ELSE
current_parse_time_elapsed_s + adjustment_s
END response_time
FROM (SELECT shared_pool_size_for_estimate,shared_pool_size_factor,
estd_lc_time_saved_factor,a.estd_lc_time_saved,
e.VALUE/100 current_parse_time_elapsed_s,
c.estd_lc_time_saved - a.estd_lc_time_saved adjustment_s FROM v$shared_pool_advice a,
(SELECT * FROM v$sysstat WHERE NAME = ‘parse time elapsed‘) e,
(SELECT estd_lc_time_saved FROM v$shared_pool_advice WHERE shared_pool_size_factor = 1) c);
因为自己搭建的环境和老师使用的环境不同,所以结果也有所差别
自己的结果如下
COMPONENT ESTD_SP_SIZE PARSE_TIME_FACTOR RESPONSE_TIME
----------- ------------ ----------------- -------------
Shared Pool 64 .9871 23.3
Shared Pool 76 .9943 18.3
Shared Pool 88 .9986 15.3
Shared Pool 100 1 14.3
Shared Pool 112 1 14.3
Shared Pool 124 1 14.3
Shared Pool 136 1 14.3
Shared Pool 148 1 14.3
Shared Pool 160 1 14.3
Shared Pool 172 1 14.3
Shared Pool 184 1 14.3
Shared Pool 196 1 14.3
Shared Pool 208 1 14.3
13 rows selected.
结果中
COMPONENT(组件)列为shared Pool
ESTD_SP_SIZE列
为假设shared Pool的大小值
RESPONSE_TIME列
为sql语句反应时间
是预测到的一个sql语句解析花费的平均时间
shared pool设的值不同,预测花费的时间可能会有改变
结果中 shared pool为64M 一个sql语句解析花费的时间为23.3
为76M 响应时间为18.3
为88M 响应时间为15.3
为100M 响应时间为14.3
总体随着预设的ESTD_SP_SIZE值的增加
相应的响应时间在减少
这是好事
但是ESTD_SP_SIZE增加到一定程度以后
上例为
Shared Pool 100 1 14.3
Shared Pool 112 1 14.3
随着空间的增加
RESPONSE_TIME的数值就不变了
这样shared pool设到
RESPONSE_TIME值稳定后的第一个值就可以了
这里是100M
在我的软硬件环境设为100M就可以了。
我的实验系统使用的虚拟机没有负载反应的不太真实
而且从实践中可以看到
从数据库刚启动开始
随着oracle数据库运行时间的增加
预测得到的最佳sharedpool的大小值会一步步增加。
因为随着运行时间增长数据库负载会增大
相同sharedpool大小造成的响应时间会变长,
而且最佳大小的值也在增大。
就是这个预测值是在变化的。
实际通过这个sql语句取出相关的值以后
一般的取
PARSE_TIME_FACTOR
的值从1开始(后面的值一般都是1)对应的ESTD_SP_SIZE数据
就是我们应该设的
这是sharedpool单独设的方法
——————————————————————————————————————————————————————
估测sga_target大小。
查询sga_target建议的大小。
SELECT (
(SELECT SUM(value) FROM V$SGA) -
(SELECT CURRENT_SIZE FROM V$SGA_DYNAMIC_FREE_MEMORY)
) "SGA_TARGET"
FROM DUAL;
AWR分析。(shared_pool,sga_size大小设置)
标签:target alt case 硬件 oltp open 理论 save cut
原文地址:http://www.cnblogs.com/andy6/p/6079149.html