标签:需要 部分 png 深度学习 multiple ons 相似度 image 图片
初次接触Captioning的问题,第一印象就是Andrej Karpathy好聪明。主要从他的两篇文章开始入门,《Deep Fragment Embeddings for Bidirectional Image Sentence Mapping》和《Deep Visual-Semantic Alignments for Generating Image Descriptions》。基本上,第一篇文章看明白了,第二篇就容易了,研究思路其实是一样的。但确实,第二个模型的功能更强大一些,因为可以生成description了。
Deep Fragment Embeddings for Bidirectional Image Sentence Mapping:
这篇论文发表在14年的NIPS上,主要解决的问题集中在retrieval的问题,没有生成description。还是先介绍一下模型吧,以下这张图其实可以完全概括了
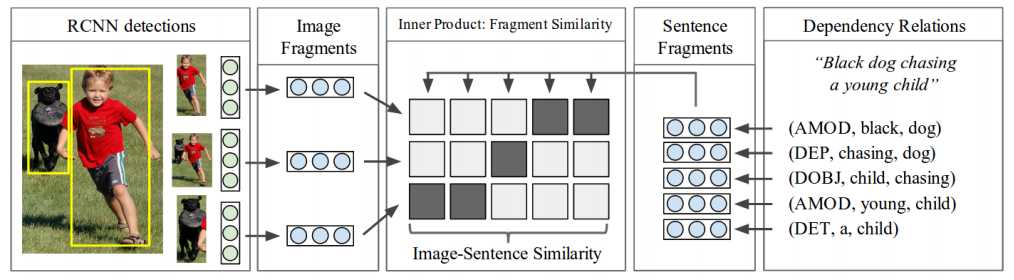
输入的数据集每一个样例由一张图片,五个manual句子描述。
对于句子的处理,主要是处理单词之间的关系。类似于上图右边,解析出单词之间的依赖关系,叫做triplet ![]() ,R就是关系,而w1,w2就是单词的representation,是1-of-k的,通过以下的关系把triplet映射到一个非线性的空间,
,R就是关系,而w1,w2就是单词的representation,是1-of-k的,通过以下的关系把triplet映射到一个非线性的空间,
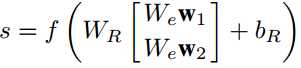
s是h维的向量特征向量,f是一个激活函数,![]() 是对应的关系的矩阵,但它是需要学习的参数。
是对应的关系的矩阵,但它是需要学习的参数。![]() 是通过训练得到的固定的参数矩阵,至于怎么得到的,我没有看过索引的论文,而源代码读入的数据直接使用了
是通过训练得到的固定的参数矩阵,至于怎么得到的,我没有看过索引的论文,而源代码读入的数据直接使用了![]() ,我就没有仔细研究。激活函数论文里使用了ReLU,而公开的源代码里提供了很多其他类型的函数,然而并没有试跑过。那为什么需要激活函数呢?我猜想大概是(未探究过正确与否)非线性的特征会有更好的拟合效果吧,联想到了深度学习里的激活函数。
,我就没有仔细研究。激活函数论文里使用了ReLU,而公开的源代码里提供了很多其他类型的函数,然而并没有试跑过。那为什么需要激活函数呢?我猜想大概是(未探究过正确与否)非线性的特征会有更好的拟合效果吧,联想到了深度学习里的激活函数。
对于图片的处理。使用RCNN,提取top 19个Region和一张全图作为特征。这里主要是提取最后一层的4096维的向量作为特征表示,经过以下式子映射到h维的特征空间中![]() 。RCNN网络结构可以进行微调,也可以不微调。在这里,需要学习的参数是
。RCNN网络结构可以进行微调,也可以不微调。在这里,需要学习的参数是![]() 。
。
计算Image Fragment 和 sentence Fragment的相似度主要对两个特征向量进行内积运算![]() 。这就很粗暴了。这样计算相似度,看起来似乎不太妥当,因为每一个图片Region的向量貌似并不能找到一个标准,至少相似度作为一种距离,这里好像并没有单位吧。但是,假如认为v和s在同一个特征空间的话,那么,一切都很顺其自然了,因为内积不就是夹角吗?还记得怎么定义希尔伯特空间的吗?
。这就很粗暴了。这样计算相似度,看起来似乎不太妥当,因为每一个图片Region的向量貌似并不能找到一个标准,至少相似度作为一种距离,这里好像并没有单位吧。但是,假如认为v和s在同一个特征空间的话,那么,一切都很顺其自然了,因为内积不就是夹角吗?还记得怎么定义希尔伯特空间的吗?
恩,对于两个模态的学习,找到一种方法把他们映射到同一特征空间非常重要。
最后一步就是定义损失函数了,这里加了一个正则化项,我看了代码对正则化怎么搞的理解又加深了,![]() 。
。
现在,怎么使得语义上使对应的fragment的变得相似很重要,这自然是通过学习参数了。AK首先用一种简单的方法,定义alignment目标函数为
![]()
当两种fragment出现在同一image-sentence pair中时,注意是image-sentence pair,就把y置为1,否则为 -1。![]() 是一个normalize项,具体可以看代码怎么实现的。通过这样简单的设置,不就使得当两种fragment出现在同一image-sentence pair中时,相似度朝着大于1的方向发展,否则朝着小于-1的方向发展了吗?因为式子前面有1减去,而且是一个max和0比较的。
是一个normalize项,具体可以看代码怎么实现的。通过这样简单的设置,不就使得当两种fragment出现在同一image-sentence pair中时,相似度朝着大于1的方向发展,否则朝着小于-1的方向发展了吗?因为式子前面有1减去,而且是一个max和0比较的。
但是,两种fragment出现在同一image-sentence pair中不代表他们就是相对应啊。注意,以下相当于提升性能吧,因为即便没有以下的multiple instance learning也是可以有结果的。因为,AK想到了一种方法,通过有约束的不等式求解,目标函数自然还是最小化了,得到
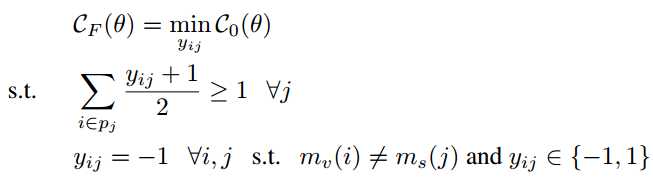
这称为mi-SVM。太厉害了,他是怎么知道有这种方法的呢?限制条件要求参数y至少有一个值为+1。论文中使用了一种启发式求解的方法,毕竟直接优化看起来还是很难的,具体的求解过程是对于y的值设置为![]() ,如果没有+1,就把内积最大的对应的y设为+1。
,如果没有+1,就把内积最大的对应的y设为+1。
另外定义了一个global目标函数。首先计算整张图片和sentence的相似度,n是一个平滑项
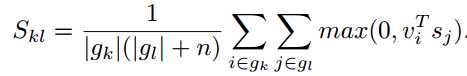
Global目标函数主要与image和sentence对应的![]() 相似度作为比较。通过与所在的行和列比较,使得目标函数朝着令匹配的
相似度作为比较。通过与所在的行和列比较,使得目标函数朝着令匹配的![]() 比不匹配的
比不匹配的![]() 大
大![]() 的方向优化。
的方向优化。
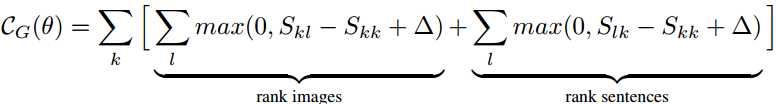
最后优化时,使用的求导的链式法则。整个优化的过程使用SGD的方法。总的来说,是参数的学习使得两种模态的信息可以对应起来。
实验评估的方法,实验数据集是随机选出句子与对应的图片。通过计算![]() ,并在每一个句子对
,并在每一个句子对![]() 进行排序,看最匹配图片的
进行排序,看最匹配图片的![]() 出现在序列的位置,定义一个R@K,K代表位置,即在位置K以前出现最匹配图片的百分比,通过对此比较评估Retrieval的性能。
出现在序列的位置,定义一个R@K,K代表位置,即在位置K以前出现最匹配图片的百分比,通过对此比较评估Retrieval的性能。
作者Andrej Karpathy的代码,我看的时候自己加了注释,放在这里共享吧,希望对你有点帮助吧。http://pan.baidu.com/s/1i5M8xk5
Deep Visual-Semantic Alignments for Generating Image Descriptions:
这篇论文相对于上一篇Deep Fragment Embeddings for Bidirectional Image Sentence Mapping,是可以生成description了,而且retrieval也得到了提升。这里,句子中提取的不再是dependency,而是首先对于每一个单词都生成一个特征向量,这是通过双向的RNN(BRNN)生成的,因为RNN它其实包含了上下文的信息,所以认为是与整个句子的语义相关。![]() 是1-of-k的向量。RNN的函数如下
是1-of-k的向量。RNN的函数如下
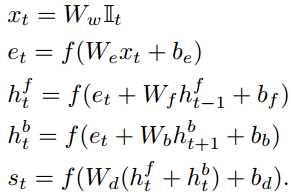
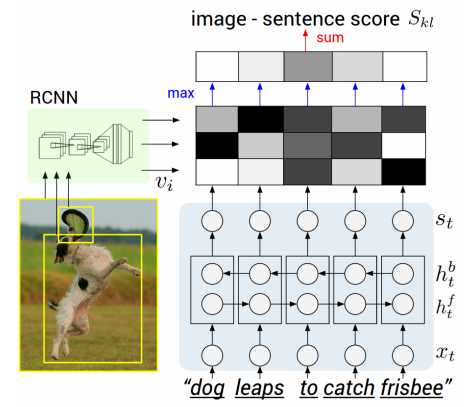
对于图片,依然使用的是RCNN的模型。而且,对于image和sentence对应的相似度计算方法也有所改变,![]() ,整个模型变成如下
,整个模型变成如下
以上模型通过训练之后,学习到的只是word与image的region的对应关系,这可能会使得邻近的单词(它们可能相关)被对应到不同的label中。这里作者通过使用马尔科夫随机场来输出最佳的每个word对应的region的序列。马尔科夫随机场对应的势函数为![]() 。而
。而![]() 是能量函数,注意前面是负值,要使得最后序列的概率最大,则能量函数应该尽量小。所以,这里定义的能量函数的条件为,使用的是链式条件随机场的形式
是能量函数,注意前面是负值,要使得最后序列的概率最大,则能量函数应该尽量小。所以,这里定义的能量函数的条件为,使用的是链式条件随机场的形式
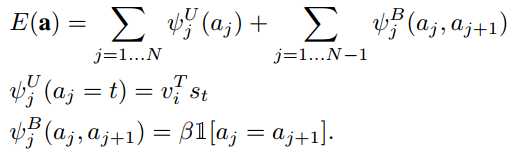
对于后面一项,当两个前后的word分配同一个标注的时候,希望能量函数为0(即尽量小),否则为![]() 。但是对于第一项……暂时还没想明白,可能认为是固有的属性,所以直接加入。当
。但是对于第一项……暂时还没想明白,可能认为是固有的属性,所以直接加入。当![]() 越大,意味着如果希望能量函数越小,分配到同一个box的连续的word会趋向于更多。
越大,意味着如果希望能量函数越小,分配到同一个box的连续的word会趋向于更多。
以上其实解决的是latent alignment的问题。
之后,通过使用generator的RNN的生成captioning,这个比较容易理解,模型为
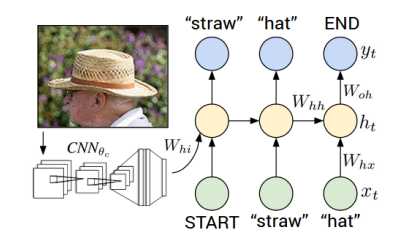
具体的计算过程为
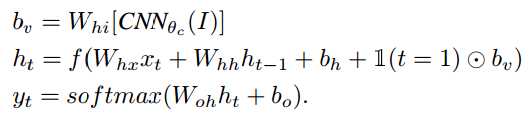
其中输入的单词是![]() ,而不是
,而不是![]() 。其实这里我的疑问是,不输入
。其实这里我的疑问是,不输入![]() 第一部分生成correspondence的意义在哪里呢?仅仅是为了alignment?感觉挺奇怪的……
第一部分生成correspondence的意义在哪里呢?仅仅是为了alignment?感觉挺奇怪的……
标签:需要 部分 png 深度学习 multiple ons 相似度 image 图片
原文地址:http://www.cnblogs.com/jie-dcai/p/6081893.html