标签:相对 following map images 用户 display 语句 刷新 img
n-gram模型是假设文本中一个词出现的概率只与它前面的N-1个词相关。auto complete的原理就是,根据用户输入的词,将后续出现概率较大的词组显示出来。因此我们可以基于n-gram模型来对用户的输入作预测。
我们的实现方法是:首先用mapreduce在offline对语料库中的数据进行n-gram建模,存到数据库中。然后用户在输入的时候向数据库中查询,获取之后出现的概率较大的词,通过前端php脚本刷新实时显示在界面上。如下所示:
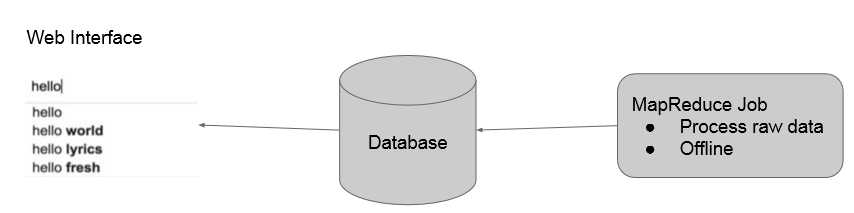
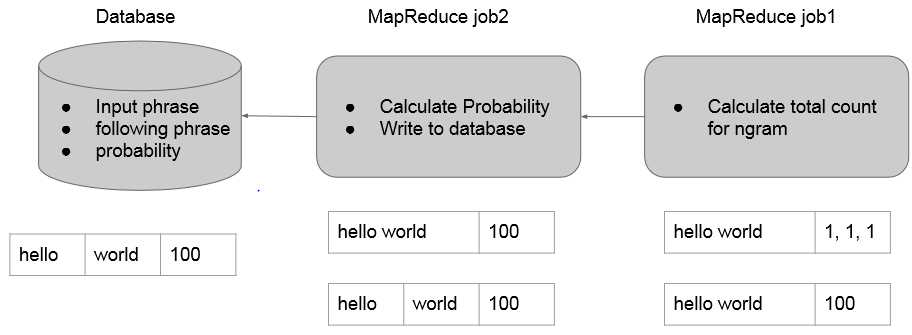
mapper负责按句读入语料库中的数据,分别作2~Ngram的切分(1-gram在这里没用),发送给reducer。
reducer则统计所有N-gram出现的次数。(这里就是一个wordcount)
mapper负责读入之前生成的N-gram及次数,将最后一个单词切分出来,以前面N-1个单词为key向reducer发送。
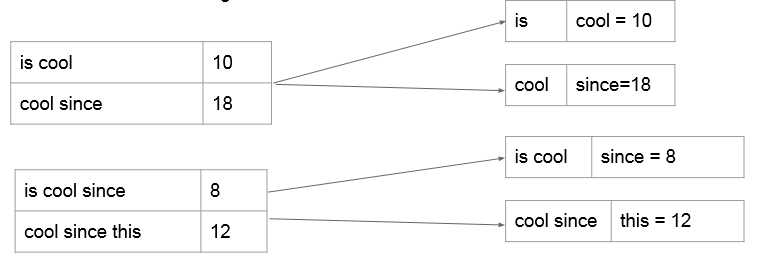
reducer里面得到的就是N-gram概率模型,即已知前N-1个词组成的phrase,最后一个词出现的所有可能及其概率。这里我们不用计算概率,仍然沿用词频能达到相同的效果,因为auto complete关注的是概率之间的相对大小而不是概率值本身。这里我们选择出现概率最大的topk个词来存入数据库,可以用treemap或者priorityQueue来做。
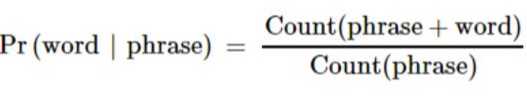
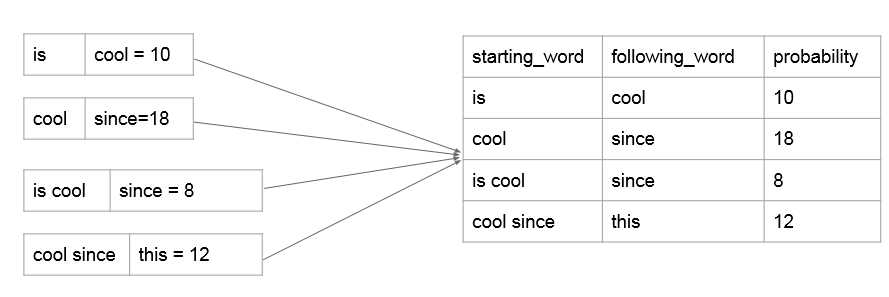
(注:这里的starting_word是1~n-1个词,following_word只能是一个词,因为这样才符合我们N-gram概率模型的意义。)
数据库中的n-gram模型:
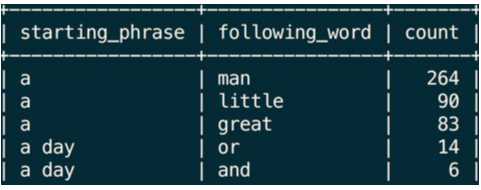
如上所述,我们看出使用n-gram模型只能与预测下一个单词。为了预测结果的多样性,如果我们要预测之后的n个单词怎么做?

使用sql语句,查询的时候查询匹配"input%"的所有starting_phrase,就可以实现。
标签:相对 following map images 用户 display 语句 刷新 img
原文地址:http://www.cnblogs.com/coldyan/p/6081978.html