标签:索引 trim store 加载 mysq har 组成 将不 指定
Durid是在2013年底开源出来的,当前最新版本0.9.2, 主要解决的是对实时数据以及较近时间的历史数据的多维查询提供高并发(多用户),低延时,高可靠性的问题。对比Druid与其他解决方案,Kylin对数据按照分区每天构建前一天的cube数据提供给用户查询,用户查询的是历史数据。而Druid不断的从ingest去拉取数据,持续构建cube,提供实时查询,主要作者下面两位, 其中一位创建了一家公司继续发展druid (Impty.io)


目录:
Durid特性
使用场景
第一:适用于清洗好的记录实时录入,但不需要更新操作
第二:支持宽表,不用join的方式(换句话说就是一张单表)
第三:可以总结出基础的统计指标,可以用一个字段表示
第四:对时区和时间维度(year、month、week、day、hour等)要求高的(甚至到分钟级别)
第五:实时性很重要
第六:对数据质量的敏感度不高
第七:用于定位效果分析和策略决策参考
Druid介绍
timestamp publisher advertiser gender country click price
2011-01-01T01:01:35Z bieberfever.com google.com Male USA 0 0.65
2011-01-01T01:03:63Z bieberfever.com google.com Male USA 0 0.62
2011-01-01T01:04:51Z bieberfever.com google.com Male USA 1 0.45
2011-01-01T01:00:00Z ultratrimfast.com google.com Female UK 0 0.87
2011-01-01T02:00:00Z ultratrimfast.com google.com Female UK 0 0.99
2011-01-01T02:00:00Z ultratrimfast.com google.com Female UK 1 1.53
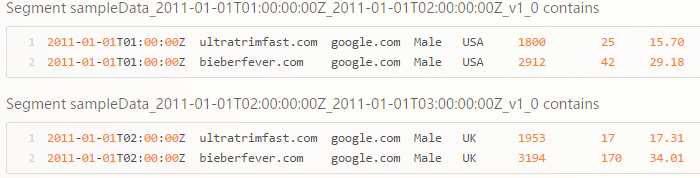
timestamp publisher advertiser gender country impressions clicks revenue
2011-01-01T01:00:00Z ultratrimfast.com google.com Male USA 1800 25 15.70
2011-01-01T01:00:00Z bieberfever.com google.com Male USA 2912 42 29.18
2011-01-01T02:00:00Z ultratrimfast.com google.com Male UK 1953 17 17.31
2011-01-01T02:00:00Z bieberfever.com google.com Male UK 3194 170 34.01
用SQL表示类似于对时间撮和所有维度列进行分组,并以原始的指标列做常用的聚合操作
GROUP BY timestamp, publisher, advertiser, gender, country
:: impressions = COUNT(1), clicks = SUM(click), revenue = SUM(price)
为什么不存原始数据? 因为原始数据量可能非常大,对于广告的场景,一秒钟的点击数是以千万计数. 如果能够在读取数据的同时就进行一点聚合运算,就可以大大减少数据量的存储.这种方式的缺点是不能查询单条事件,也就是你无法查到每条事件具体的click和price值了.由于后面的查询都将以上面的查询为基础,所以Roll-up的结果一定要能满足查询的需求.通常count和sum就足够了,因此Rollup的粒度是你能查询的数据的最小时间单位. 假设每隔1秒Rollup一次,后面的查询你最小只能以一秒为单位,不能查询一毫秒的事件.默认的粒度单位是ms.
角色功能
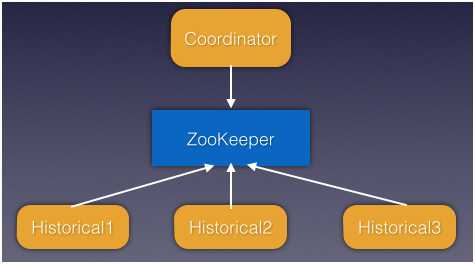
协调节点对Segment的负载均衡(如果某个节点数据量太大不应该分配任务,而把任务分配给数据量小的节点)是如何实现的?
当历史节点重启或不可用时,处理方式:
补充:
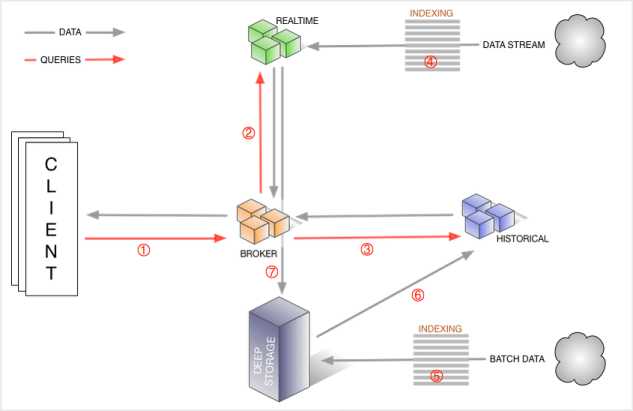
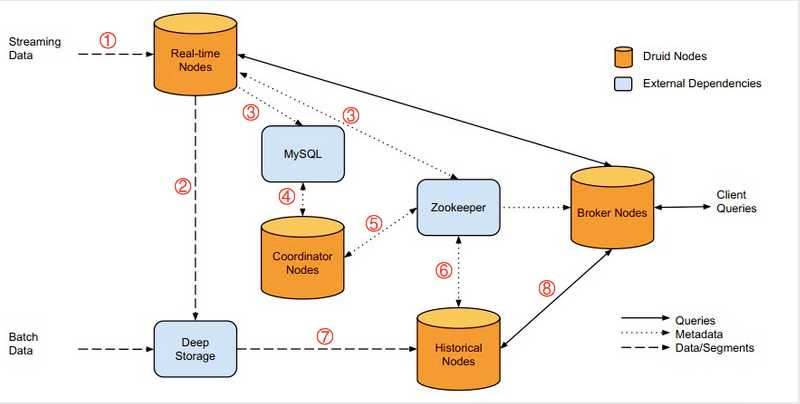
架构介绍
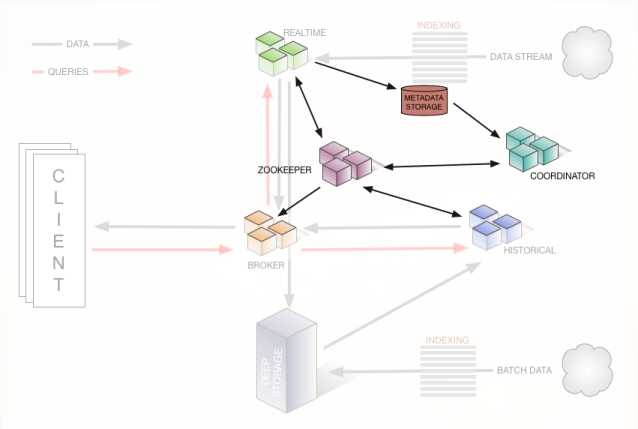
MetaData Storage 与 Zookeeper
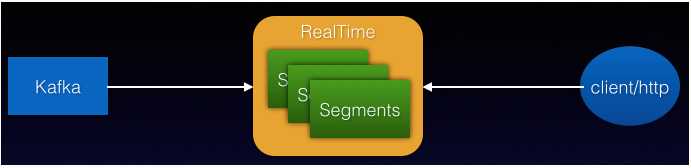
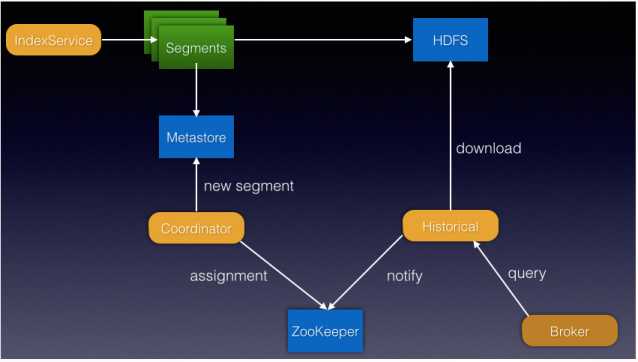
segment
分布式集群(测试)
标签:索引 trim store 加载 mysq har 组成 将不 指定
原文地址:http://www.cnblogs.com/tgzhu/p/6077846.html