标签:mode 安全模式 将不 会话 方式 机器 rem 角色 string
参考文档:
zookeeper中文网
zookeeper 是一个高效的分布式协调服务,它暴露了一些公用服务,比如命名/配置/同步控制/群组服务等。我们可以使用ZK来实现一些功能,例如:达成共识/集群管理/leader选举等,也是一个高可用的分布式管理与协调框架,基于ZAB算法(原子消息广播协议)的实现,该框架能够很好的保证数据的顺序一致性。
强一致性和顺序一致性
强一致性:任何一次读都能读到某个数据的最近一次写的数据,系统中的所有进程,看到的操作顺序,都和全局时钟下的顺序一致。
显然这两个条件都对全局时钟有非常高的要求。强一致性,只是存在理论中的一致性模型,比它要求更弱一些的,就是顺序一致性。
顺序一致性:
其一与前面强一致性的要求一样,也是可以马上读到最近写入的数据,然而它的第二个条件就弱化了很多,它允许系统中的所有进程形成自己合理的统一的一致性,不需要与全局时钟下的顺序都一致,系统的所有进程的顺序一致,而且是合理的,就是说任何一个进程中,这个进程对同一个变量的读写顺序要保持,然后大家形成一致。不需要与全局时钟下的顺序一致,可见,顺序一致性在顺序要求上并没有那么严格,它只要求系统中的所有进程达成自己认为的一致就可以了,即错的话一起错,对的话一起对,同时不违反程序的顺序即可,并不需要个全局顺序保持一致。
Zookeeper使用的自己的ZAB协议,其作者认为和paxos算法(paxos算法不详述,可以参考http://www.tudou.com/programs/view/e8zM8dAL6hM/)并不相同,这里简要不精确的描述一下ZAB协议以帮助理解Zookeeper。
ZAB协议的全称是Zookeeper Atomic Broadcast,该协议看起来确实是Paxos协议的一种变形,该协议包含了2个阶段:lead section阶段和Atomic broadcast阶段。
集群中选举出一个leader,其他的则是follower,所有的写操作都会传送给leader,并通过broadcast将所有的更新告知给follower。
当leader崩溃时后者leader失去了大多数的follower时,需要重新选举一个新的leader,让所有的服务器都恢复到一个正确的状态。
当leader选举出来,并且大多数的服务器完成和leader的同步之后,leader election的过程就结束了,将进入Atomic broadcast的过程。
Atomic broadcast同步leader和follower之间的信息,保证leader和follower拥有相同的系统状态。
ZooKeeper 虽然是一个针对分布式系统的协调服务,但它本身也是一个分布式应用程序。ZooKeeper 遵循一个简单的客户端-服务器模型,其中客户端 是使用服务的节点(即机器),而服务器 是提供服务的节点。ZooKeeper 服务器的集合形成了一个 ZooKeeper 集合体(ensemble)。在任何给定的时间内,一个 ZooKeeper 客户端可连接到一个 ZooKeeper 服务器。每个 ZooKeeper 服务器都可以同时处理大量客户端连接。每个客户端定期发送 ping 到它所连接的 ZooKeeper 服务器,让服务器知道它处于活动和连接状态。被询问的 ZooKeeper 服务器通过 ping 确认进行响应,表示服务器也处于活动状态。如果客户端在指定时间内没有收到服务器的确认,那么客户端会连接到集合体中的另一台服务器,而且客户端会话会被透明地转移到新的 ZooKeeper 服务器。
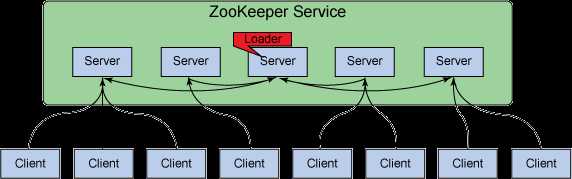
zk集群安装非常简单,一个java程序,直接从官网下载,解压即可。
cd zookeeper/conf/ mv zoo_sample.cfg zoo.cfg vi zoo.cfg 修改2处: dataDir=/usr/local/software/zookeeper/data #文件最后添加 server.0=192.168.0.201:2888:3888 server.1=192.168.0.202:2888:3888 server.2=192.168.0.203:2888:3888 到上述指定data路径下新建data文件夹和myid文件 vi myid 写入内容为服务器标识,分别为0,1,2 最后给zk设置环境变量即可
- tickTime: 基本事件单元,以毫秒为单位。这个时间是作为 Zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每隔 tickTime时间就会发送一个心跳。
- dataDir:存储内存中数据库快照的位置,顾名思义就是 Zookeeper保存数据的目录,默认情况下,Zookeeper将写数据的日志文件也保存在这个目录里。
- clientPort: 这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper会监听这个端口,接受客户端的访问请求。
- initLimit: 这个配置项是用来配置 Zookeeper接受客户端初始化连接时最长能忍受多少个心跳时间间隔数,当已经超过 10 个心跳的时间(也就是 tickTime)长度后Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是10*2000=20 秒。
- syncLimit: 这个配置项标识 Leader 与 Follower之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime的时间长度,总的时间长度就是 5*2000=10 秒
- server.A = B:C:D :
- A表示这个是第几号服务器,
- B 是这个服务器的 ip 地址;
- C 表示的是这个服务器与集群中的 Leader服务器交换信息的端口;
- D 表示的是万一集群中的 Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader
./zkServer.sh start ./zkServer.sh status
./zkCli.sh
stat path [watch] set path data [version] ls path [watch] delquota [-n|-b] path ls2 path [watch] setAcl path acl setquota -n|-b val path history redo cmdno printwatches on|off delete path [version] sync path listquota path rmr path get path [watch] create [-s] [-e] path data acl addauth scheme auth quit getAcl path close connect host:port
zookeeper的核心其实是一个精简的文件系统,提供了一些简单的操作和附加的抽象,并且集群的部署方式使其具有较高的可靠性。ZK的协作过程简化了系统之间的交互,即使参与者不知道彼此,也可以相互发现对方并且按成可靠的交互。
简单。Zookeeper允许程序通过一个共享的类似于标准文件系统的有组织的分层命名空间分布式处理协调。命名空间包括:数据寄存器 - 在Zookeeper中叫znodes, 它和文件、目录一样。和一般文件系统的不同之处是,它的设计就是为了存储,Zookeeper的数据保持在内存中,这就意味着它可以实现高吞吐量和低延迟的数据。
Zookeeper的实现提供了一个优质的高性能、高可用,严格的访问顺序。
复制。像分布式处理一样,Zookeeper自己在处理协调的时候要复制多个主机。

Zookeeper服务的组成部分必须彼此都知道彼此,它们维持了一个内存状态映像,连同事务日志和快照在一个持久化的存储中。只要大多数的服务器是可用的,Zookeeper服务就是可用的。
客户端连接到一个单独的服务。客户端保持了一个TCP连接,通过这个TCP连接发送请求、获取响应、获取watch事件、和发送心跳。如果这个连接断了,会自动连接到其他不同的服务器。
序列。Zookeeper用数字标记每一个更新,用它来反射出所有的事务顺序。随后的操作可以使用这个顺序去实现更高级的抽象,例如同步原件。
快速。它在"Read-dominant"工作负载中特别快。Zookeeper 应用运行在数以千计的机器上,并且它通常在读比写多的时候运行的最好,读写大概比例在10:1。
Zookeeper提供的命名空间非常像一个标准的文件系统。一个名字是一系列的以‘/‘隔开的一个路径元素。Zookeeper命名空间中所有的节点都是通过路径识别。

不像标准的文件系统,Zookeeper命名空间中的每个节点可以有数据也可以有子目录。它就像一个既可以是文件也可以是目录的文件系统。(Zookeeper被设计成保存协调数据:状态信息,配置,位置信息,等等,所以每个节点存储的数据通常较小,通常在1个字节到数千字节的范围之内)我们使用术语znode来表明Zookeeper的数据节点。
znode维持了一个stat结构,它包括数据变化的版本号、访问控制列表变化、和时间戳,允许缓存验证和协调更新。每当znode的数据有变化,版本号就会增加,每当客户端检索数据时同时它也获取数据的版本信息。
命名空间中每个znode存储的数据自动的读取和写入的,读取时获得znode所有关联的数据字节,写入时替换所有的数据。每个节点都有一个访问控制列表来制约谁可以做什么。
Zookeeper还有一个临时节点的概念。这些znode和session存活的一样长,session创建时存活,当session结束,也跟着删除。
临时节点是相当有用的,试想当一台服务器连接上zk时在zk上创建了一个临时节点,当服务器由于各种原因和zk失联之后,临时节点自动消失,通过监控这个临时节点的状态即可以知道服务器的状态。
很多分布式服务管理框架使用临时节点来监控服务器的状态,例如dubbo。
对节点支持条件更新和watch操作
Zookeeper支持watches的概念。客户端可以在znode上设置一个watch。当znode发生变化时触发并移除watch。当watch被触发时,客户端会接收到一个包说明znode有变化了。并且如果客户端和其中一台server中间的连接坏掉了,客户端就会收到一个本地通知。这些可以用来[tbd]。
Zookeeper是非常简单和高效的。因为它的目标就是,作为建设复杂服务的基础,比如同步。zookeeper提供了一套保证,他们包括:
Zookeeper Compnents 展示了Zookeeper服务的高级组件。除了请求处理器的异常之外,组成Zookeeper服务的服务器都会复制它们自己组件的副本。

Replicated database 是一个内存数据库,它包含全部的数据树。为了可恢复性,更新记录保存到磁盘上,并且写入操作在应用到内存数据库之前被序列化到磁盘上。
每个Zookeeper 服务端服务客户端。客户端正确的连接到一个服务器提交请求。每个服务端数据库的本地副本为读请求提供服务。服务的变化状态请求、写请求,被一个协议保护。
作为协议的一部分,所有的写操作从客户端转递到一台单独服务器,称为leader。其他的Zookeeper服务器叫做follows,它接收来自leader的消息建议并达成一致的消息建议。消息管理层负责在失败的时候更换Leader并同步Follows。
Zookeeper使用了一个自定义的原子消息协议。因为消息层是原子的,Zookeeper可以保证本地副本从不出现偏差。当leader接受到一个写请求,它计算写操作被应用时系统的状态,并将捕获到的新状态转化进入事务。
mvn依赖:
<dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.4.9</version> </dependency>
Java增删该查
import org.apache.zookeeper.*; import java.util.concurrent.CountDownLatch; /** * Created by carl.yu on 2016/11/22. */ public class ZkBase { static final String CONNECT_ADDR = "192.168.1.211:2181,192.168.1.212:2181,192.168.1.213:2181"; static final int SESSION_TIMEOUT = 2000; static final CountDownLatch connectedSemaphore = new CountDownLatch(1); public static void main(String[] args) throws Exception { ZooKeeper zk = new ZooKeeper(CONNECT_ADDR, SESSION_TIMEOUT, new Watcher() { public void process(WatchedEvent event) { //获取事件的状态 Event.KeeperState keeperState = event.getState(); Event.EventType eventType = event.getType(); //如果是建立连接 if (Event.KeeperState.SyncConnected == keeperState) { if (Event.EventType.None == eventType) { //如果建立连接成功,则发送信号量,让后续阻塞程序向下执行 connectedSemaphore.countDown(); System.out.println("zk 建立连接"); } } } }); //创建持久节点 System.out.println("创建节点/testRoot"); zk.create("/testRoot", "testRoot".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); //创建子节点 System.out.println("创建子节点/testRoot/children"); zk.create("/testRoot/children", "children data".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); //获取节点信息 byte[] data = zk.getData("/testRoot", false, null); System.out.println("获取节点信息"); System.out.println(new String(data)); System.out.println(zk.getChildren("/testRoot", false)); //修改节点的值 System.out.println("修改节点的值"); zk.setData("/testRoot", "modify data root".getBytes(), -1); data = zk.getData("/testRoot", false, null); System.out.println(new String(data)); //判断节点是否存在 System.out.println(zk.exists("/testRoot/children", false)); //删除节点 System.out.println("删除节点"); zk.delete("/testRoot/children", -1); System.out.println(zk.exists("/testRoot/children", false)); //进行阻塞 connectedSemaphore.await(); zk.close(); System.out.println("断开了连接"); } }
详情请参考:http://zookeeper.majunwei.com/document/3.4.6/DeveloperProgrammerGuide.html,其中对ACL和权限验证也有详细介绍
Zookeeper有一个分层的命名空间,非常像一个分布式的文件系统。不同的地方仅仅是命名空间里的每个节点可以有关联数据,也可以有子目录。它就像一个既可以是文件又可以是目录的文件系统。
路径节点总是表示为标准的,绝对的,以斜线为分隔符的路径;没有相对引用。任何unicode编码字符都可以用在路径上,但是有以下限制:
Zookeeper中的每个节点都被称为znode。
Znode维护了一个stat结构,这个stat包含数据变化的版本号、访问控制列表变化。stat结构还有时间戳。版本号和时间戳一起,可让Zookeeper验证缓存和协调更新。每次znode的数据发生了变化,版本号就增加。
例如,无论何时客户端检索数据,它也一起检索数据的版本号。并且当客户端执行更新或删除时,客户端必须提供他正在改变的znode的版本号。如果它提供的版本号和真实的数据版本号不一致,更新将会失败。(这种行为可以被覆盖)
在分布式应用工程中,node可以指的是一般的主机,一个服务器,全体成员的一员,一个客户端程序,等等。在Zookeeper的文档中,znode指的是数据节点。Servers指的是组成Zookeeper服务的机器;quorum peers 指的是组成全体的servers;client指的是任何使用Zookeeper服务的主机和程序。
Znode是程序员使用的主要实体。这里需要提到几个有价值的特征:
1、Watches
客户端可以在znode上设置watches。znode的变化将会触发watches后清除watches。触发watches时,Zookeeper向客户端发送一个通知。更多关于watches的信息可以在 Zookeeper watches 章节查看。
2、数据访问
- 命名空间里的每个znodes上的数据存储都是原子性的读取和写入。读取时获取所有与znode有关的数据字节,写入时替换所有的数据字节。每个节点有一个访问控制列表用来限制谁可以做什么。
- Zookeeper不是设计成通用的数据库或者大数据对象存储。而是管理协调数据。这个数据的形式是配置表单,状态信息,集合点等等。各种形式的协调数据属性都非常小:经过测量在KB之内。
- Zookeeper客户端和服务端实现检查确保znode有不到1M的数据,但是实际的数据要远小于平均值。
- 在相对较大的数据上的操作将会引起一些操作花费更多的时间并且影响一些操作的延迟,因为需要额外的时间在网络和存储设备之间移动数据。如果需要大数据存储,通常的做法是将数据存储进大存储器系统,如NFS和HDFS,然后将存储指针和地址存储进Zookeeper。
3、临时节点
Zookeeper还有一个临时节点的概念。这些znode一旦session创建就存在,session结束就被删除。因为这个特性,临时节点不允许有子节点。
4、序列节点 -- 唯一的命名
当创建znode的时候你还可以请求在路径的最后追加一个单调递增的计数器。这个计数器在父节点是唯一的。计数器有一个%010d --的格式,它是10位数用0做填充(计数器用这个方法格式化简化排序),也就是:0000000001。查看Queue Recipe使用这个特性的例子。注释:计数器的序列号由父节点通过一个int类型维护,计数器当超过2147483647的时候将会溢出(-2147483647将会导致)。
Zookeeper通过多种方式追踪计时:
Zxid
每个Zookeeper状态的变化都以zxid(事务ID)的形式接收到标记。这个暴露了Zookeeper所有变化的总排序。每个变化都会有一个zxid,并且如果zxid1早于zxid2则zxid1一定小于zxid2。
版本号
节点的每个变化都会引起那个节点的版本号的其中之一增加。这三个版本号是version(znode的数据变化版本号),cversion(子目录的变化版本号),和aversion(访问控制列表的变化版本号)。
Ticks
当使用多服务器的Zookeeper时,服务器使用ticks定义事件的时间,如状态上传,会话超时,同事之间的连接超时等等。tick次数只是通过最小的会话超时间接的暴露;如果一个客户端请求会话超时小于最小的会话超时,服务器就会告诉客户端会话超时实际上是最低会话超时时间。
Real time
Zookeeper不使用实时或时钟时间,除了将时间戳加在znode创建和更新的stat结构上。
Zookeeper中的每个znode的stat机构都由下面的字段组成:
Zookeeper客户端通过使用语言绑定在服务上创建一个handle建立一个和Zookeeper服务的会话。
一旦创建了,handle从CONNECTION状态开始并且客户端库尝试连接到Zookeeper服务的服务器在这时候切换到CONNECTED状态,在正常运行期间会在这两个状态期间。
如果发生不可恢复的错误,例如会话超时或授权失败,或应用明确的关闭处理器,handle将会移动到CLOSED状态。下面的图像展示了Zookeeper客户端可能的状态变化流程:

创建客户端会话,应用代码必须提供一个以逗号分隔开的host:port的列表,每个对应一个Zookeeper服务(如:"127.0.0.1:4545"or"127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002")。
Zookeeper客户端会选择任意一个服务并尝试连接它。如果这个连接失败,或者客户端变为disconected,客户端会自动的尝试连接列表里的下一个服务器,直到建立连接。
当建立连接之后:
sesion通过客户端发送请求保持存活。如果session空闲了一个超时时间,客户端会发送一个PING请求保持session存活。这个PING请求不仅可让Zookeeer服务器知道客户是活动的,而且可让客户端核查它的连接是活动的。PING的时间是能够确保合理检测死链的时间并重连到新服务。
一旦成功的建立的到服务器的连接基本上有两种情况客户端生产丢失连接,当执行同步或异步操作时并且下面的其中之一:
Zookeeper里的所有读取操作 - getData(),getChildren()和exists() - 都有设置watch的选项。这是Zookeeper watch的定义:watch事件是one-time触发,向客户端发送设置watch,当设置watch的数据变化时发生。在watch定义里有三个关键点:
Watches是在client连接到Zookeeper服务端的本地维护。这可让watches成为轻量的,可维护的和派发的。当一个client连接到新server,watch将会触发任何session事件。断开连接后不能接收到。当客户端重连,先前注册的watches将会被重新注册并触发如果需要。
关于watches,Zookeeper维护这些保证:
这里是上面Watcher的一个小测试
zookeeper原生自带的watch是一次性的,getData()和exists()设置data watches。getChildren()设置child watches,具体看代码:
import java.util.List; import java.util.concurrent.CountDownLatch; import java.util.concurrent.atomic.AtomicInteger; import org.apache.zookeeper.CreateMode; import org.apache.zookeeper.WatchedEvent; import org.apache.zookeeper.Watcher; import org.apache.zookeeper.Watcher.Event.EventType; import org.apache.zookeeper.Watcher.Event.KeeperState; import org.apache.zookeeper.ZooDefs.Ids; import org.apache.zookeeper.ZooKeeper; import org.apache.zookeeper.data.Stat; /** * Created by carl.yu on 2016/11/22. */ public class ZooKeeperWatcher implements Watcher { /** 定义原子变量 */ AtomicInteger seq = new AtomicInteger(); /** 定义session失效时间 */ private static final int SESSION_TIMEOUT = 10000; /** zookeeper服务器地址 */ private static final String CONNECTION_ADDR = "192.168.1.211:2181,192.168.1.212:2181,192.168.1.213:2181"; /** zk父路径设置 */ private static final String PARENT_PATH = "/p"; /** zk子路径设置 */ private static final String CHILDREN_PATH = "/p/c"; /** 进入标识 */ private static final String LOG_PREFIX_OF_MAIN = "【Main】"; /** zk实例 */ private ZooKeeper zk = null; /**用于等待zookeeper连接建立之后 通知阻塞程序继续向下执行 */ private CountDownLatch connectedSemaphore = new CountDownLatch(1); /** * 创建ZK连接 * @param connectAddr ZK服务器地址列表 * @param sessionTimeout Session超时时间 */ public void createConnection(String connectAddr, int sessionTimeout) { this.releaseConnection(); try { //this表示把当前对象进行传递到其中去(也就是在主函数里实例化的new ZooKeeperWatcher()实例对象) zk = new ZooKeeper(connectAddr, sessionTimeout, this); System.out.println(LOG_PREFIX_OF_MAIN + "开始连接ZK服务器"); connectedSemaphore.await(); } catch (Exception e) { e.printStackTrace(); } } /** * 关闭ZK连接 */ public void releaseConnection() { if (this.zk != null) { try { this.zk.close(); } catch (InterruptedException e) { e.printStackTrace(); } } } /** * 创建节点 * @param path 节点路径 * @param data 数据内容 * @return */ public boolean createPath(String path, String data, boolean needWatch) { try { //设置监控(由于zookeeper的监控都是一次性的所以 每次必须设置监控) this.zk.exists(path, needWatch); System.out.println(LOG_PREFIX_OF_MAIN + "节点创建成功, Path: " + this.zk.create( /**路径*/ path, /**数据*/ data.getBytes(), /**所有可见*/ Ids.OPEN_ACL_UNSAFE, /**永久存储*/ CreateMode.PERSISTENT ) + ", content: " + data); } catch (Exception e) { e.printStackTrace(); return false; } return true; } /** * 读取指定节点数据内容 * @param path 节点路径 * @return */ public String readData(String path, boolean needWatch) { try { System.out.println("读取数据操作..."); return new String(this.zk.getData(path, needWatch, null)); } catch (Exception e) { e.printStackTrace(); return ""; } } /** * 更新指定节点数据内容 * @param path 节点路径 * @param data 数据内容 * @return */ public boolean writeData(String path, String data) { try { System.out.println(LOG_PREFIX_OF_MAIN + "更新数据成功,path:" + path + ", stat: " + this.zk.setData(path, data.getBytes(), -1)); } catch (Exception e) { e.printStackTrace(); return false; } return true; } /** * 删除指定节点 * * @param path * 节点path */ public void deleteNode(String path) { try { this.zk.delete(path, -1); System.out.println(LOG_PREFIX_OF_MAIN + "删除节点成功,path:" + path); } catch (Exception e) { e.printStackTrace(); } } /** * 判断指定节点是否存在 * @param path 节点路径 */ public Stat exists(String path, boolean needWatch) { try { return this.zk.exists(path, needWatch); } catch (Exception e) { e.printStackTrace(); return null; } } /** * 获取子节点 * @param path 节点路径 */ private List<String> getChildren(String path, boolean needWatch) { try { System.out.println("读取子节点操作..."); return this.zk.getChildren(path, needWatch); } catch (Exception e) { e.printStackTrace(); return null; } } /** * 删除所有节点 */ public void deleteAllTestPath(boolean needWatch) { if(this.exists(CHILDREN_PATH, needWatch) != null){ this.deleteNode(CHILDREN_PATH); } if(this.exists(PARENT_PATH, needWatch) != null){ this.deleteNode(PARENT_PATH); } } /** * 收到来自Server的Watcher通知后的处理。 */ @Override public void process(WatchedEvent event) { System.out.println("进入 process 。。。。。event = " + event); try { Thread.sleep(200); } catch (InterruptedException e) { e.printStackTrace(); } if (event == null) { return; } // 连接状态 KeeperState keeperState = event.getState(); // 事件类型 EventType eventType = event.getType(); // 受影响的path String path = event.getPath(); //原子对象seq 记录进入process的次数 String logPrefix = "【Watcher-" + this.seq.incrementAndGet() + "】"; System.out.println(logPrefix + "收到Watcher通知"); System.out.println(logPrefix + "连接状态:\t" + keeperState.toString()); System.out.println(logPrefix + "事件类型:\t" + eventType.toString()); if (KeeperState.SyncConnected == keeperState) { // 成功连接上ZK服务器 if (EventType.None == eventType) { System.out.println(logPrefix + "成功连接上ZK服务器"); connectedSemaphore.countDown(); } //创建节点 else if (EventType.NodeCreated == eventType) { System.out.println(logPrefix + "节点创建"); try { Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } } //更新节点 else if (EventType.NodeDataChanged == eventType) { System.out.println(logPrefix + "节点数据更新"); try { Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } } //更新子节点 else if (EventType.NodeChildrenChanged == eventType) { System.out.println(logPrefix + "子节点变更"); try { Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } } //删除节点 else if (EventType.NodeDeleted == eventType) { System.out.println(logPrefix + "节点 " + path + " 被删除"); } else ; } else if (KeeperState.Disconnected == keeperState) { System.out.println(logPrefix + "与ZK服务器断开连接"); } else if (KeeperState.AuthFailed == keeperState) { System.out.println(logPrefix + "权限检查失败"); } else if (KeeperState.Expired == keeperState) { System.out.println(logPrefix + "会话失效"); } else ; System.out.println("--------------------------------------------"); } /** * <B>方法名称:</B>测试zookeeper监控<BR> * <B>概要说明:</B>主要测试watch功能<BR> * @param args * @throws Exception */ public static void main(String[] args) throws Exception { //建立watcher //当前客户端可以称为一个watcher 观察者角色 ZooKeeperWatcher zkWatch = new ZooKeeperWatcher(); //创建连接 zkWatch.createConnection(CONNECTION_ADDR, SESSION_TIMEOUT); //System.out.println(zkWatch.zk.toString()); Thread.sleep(1000); // 清理节点 zkWatch.deleteAllTestPath(false); //-----------------第一步: 创建父节点 /p ------------------------// if (zkWatch.createPath(PARENT_PATH, System.currentTimeMillis() + "", true)) { Thread.sleep(1000); //-----------------第二步: 读取节点 /p 和 读取/p节点下的子节点(getChildren)的区别 --------------// // 读取数据并且监控当前数据变化 zkWatch.readData(PARENT_PATH, true); // 读取子节点(监控childNodeChange事件) zkWatch.getChildren(PARENT_PATH, true); // 更新数据 zkWatch.writeData(PARENT_PATH, System.currentTimeMillis() + ""); Thread.sleep(1000); // 创建子节点 zkWatch.createPath(CHILDREN_PATH, System.currentTimeMillis() + "", true); //-----------------第三步: 建立子节点的触发 --------------// // zkWatch.createPath(CHILDREN_PATH + "/c1", System.currentTimeMillis() + "", true); // zkWatch.createPath(CHILDREN_PATH + "/c1/c2", System.currentTimeMillis() + "", true); //-----------------第四步: 更新子节点数据的触发 --------------// //在进行修改之前,我们需要watch一下这个节点: Thread.sleep(1000); zkWatch.readData(CHILDREN_PATH, true); zkWatch.writeData(CHILDREN_PATH, System.currentTimeMillis() + ""); } Thread.sleep(10000); // 清理节点 zkWatch.deleteAllTestPath(false); Thread.sleep(10000); zkWatch.releaseConnection(); } }
标签:mode 安全模式 将不 会话 方式 机器 rem 角色 string
原文地址:http://www.cnblogs.com/carl10086/p/6083799.html