标签:tor 参数 turn 最优 好处 函数 shu imp alt
采用1M MovieLensz数据(80%train, 20%test, UserIDs range between 1 and 6040 ,MovieIDs range between 1 and 3952, From http://files.grouplens.org/datasets/movielens/)
进行训练和测试,在k仅为10时,得到最佳RMSE为0.854743。在100k数据上k=100时最佳RMSE为0.916602。
以下公式和文字来自陈靖_的博文 http://blog.csdn.net/zhongkejingwang/article/details/43083603,包含详尽的描述和推导。
参考论文为《Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model Yehuda Koren》
通过对A矩阵进行奇异值分解:
现在可以来对A矩阵的映射过程进行分析了:如果在n维空间中找到一个(超)矩形,其边都落在A‘A的特征向量的方向上,那么经过A变换后的形状仍然为(超)矩形!
vi为A‘A的特征向量,称为A的右奇异向量,ui=Avi实际上为AA‘的特征向量,称为A的左奇异向量。下面利用SVD证明文章一开始的满秩分解:
利用矩阵分块乘法展开得:
可以看到第二项为0,有
令
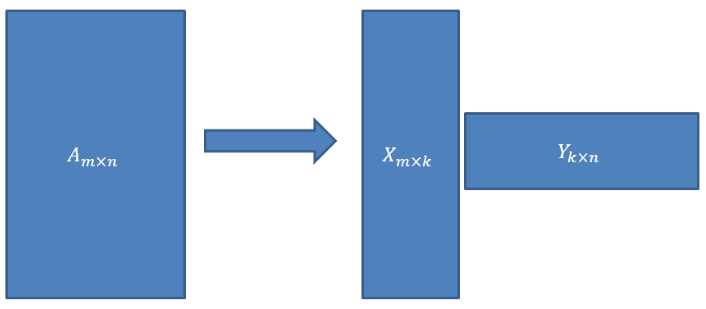
则A=XY即是A的满秩分解。
对任意一个矩阵A,都有它的满秩分解(k=Rank(A)):
那么刚才的评分矩阵R也存在这样一个分解,所以可以用两个矩阵P和Q的乘积来表示评分矩阵R:
上图中的U表示用户数,I表示商品数。然后就是利用R中的已知评分训练P和Q使得P和Q相乘的结果最好地拟合已知的评分,那么未知的评分也就可以用P的某一行乘上Q的某一列得到了:
这是预测用户u对商品i的评分,它等于P矩阵的第u行乘上Q矩阵的第i列。这个是最基本的SVD算法,那么如何通过已知评分训练得到P和Q的具体数值呢?
假设已知的评分为:
则真实值与预测值的误差为:
继而可以计算出总的误差平方和:
利用梯度下降法可以求得SSE在Puk变量(也就是P矩阵的第u行第k列的值)处的梯度:
利用求导链式法则,e^2先对e求导再乘以e对Puk的求导:
由于
所以
上式中括号里的那一坨式子如果展开来看的话,其与Puk有关的项只有PukQki,其他的无关项对Puk的求导均等于0
所以求导结果为:
所以
为了让式子更简洁,令
这样做对结果没有影响,只是为了把求导结果前的2去掉,更好看点。得到
现在得到了目标函数在Puk处的梯度了,那么按照梯度下降法,将Puk往负梯度方向变化:
令更新的步长(也就是学习速率)为
则Puk的更新式为
同样的方式可得到Qik的更新式为
得到了更新的式子,现在开始来讨论这个更新要怎么进行。有两种选择:1、计算完所有已知评分的预测误差后再对P、Q进行更新。2、每计算完一个eui后立即对Pu和qi进行更新。这两种方式都有名称,分别叫:1、批梯度下降。2、随机梯度下降。两者的区别就是批梯度下降在下一轮迭代才能使用本次迭代的更新值,随机梯度下降本次迭代中当前样本使用的值可能就是上一个样本更新的值。由于随机性可以带来很多好处,比如有利于避免局部最优解,所以现在大多倾向于使用随机梯度下降进行更新。
上面就是基本的SVD算法,但是,问题来了,上面的训练是针对已知评分数据的,过分地拟合这部分数据有可能导致模型的测试效果很差,在测试集上面表现很糟糕。这就是过拟合问题,关于过拟合与欠拟合可以看一下这张图
第一个是欠拟合,第二个刚好,第三个过拟合。那么如何避免过拟合呢?那就是在目标函数中加入正则化参数(加入惩罚项),对于目标函数来说,P矩阵和Q矩阵中的所有值都是变量,这些变量在不知道哪个变量会带来过拟合的情况下,对所有变量都进行惩罚:
这时候目标函数对Puk的导数就发生变化了,现在就来求加入惩罚项后的导数。
括号里第一项对Puk的求导前面已经求过了,第二项对Puk的求导很容易求得,第三项与Puk无关,导数为0,所以
同理可得SSE对qik的导数为
将这两个变量往负梯度方向变化,则更新式为
这就是正则化后的SVD,也叫RSVD。
加入偏置的SVD、RSVD
关于SVD算法的变种太多了,叫法也不统一,在预测式子上加点参数又会出来一个名称。由于用户对商品的打分不仅取决于用户和商品间的某种关系,还取决于用户和商品独有的性质,Koren将SVD的预测公式改成这样
第一项为总的平均分,bu为用户u的属性值,bi为商品i的属性值,加入的这两个变量在SSE式子中同样需要惩罚,那么SSE就变成了下面这样:
由上式可以看出SSE对Puk和qik的导数都没有变化,但此时多了bu和bi变量,同样要求出其更新式。首先求SSE对bu的导数,只有第一项和第四项和bu有关,第一项对bu的求导和之前的求导类似,用链式法则即可求得,第四项直接求导即可,最后可得偏导数为
同理可得对bi的导数为
所以往其负梯度方向变化得到其更新式为
这就是修改后的SVD(RSVD)。
1 #coding:utf8 2 import numpy as np 3 4 class SVD(): 5 def __init__(self,trainfile,testfile,factorNum=10): 6 self.trainfile=trainfile 7 self.testfile=testfile 8 self.factorNum=factorNum 9 self.userNum= 6041 # 根据user id范围 10 self.itemNum= 3953 # 根据movie id范围 11 self.learningRate=0.01 12 self.regularization=0.02 13 score=[float(line.split(‘::‘)[2])for line in open(self.trainfile)] 14 self.av= np.mean(score) 15 self.bu=np.zeros(self.userNum) 16 self.bi=np.zeros(self.itemNum) 17 temp=np.sqrt(self.factorNum) 18 self.pu=np.array([[(0.1*np.random.random()/temp) for i in range(self.factorNum)] for j in range(self.userNum)]) 19 self.qi=np.array([[0.1*np.random.random()/temp for i in range(self.factorNum)] for j in range(self.itemNum)]) 20 21 def train(self,iterTimes=100): 22 preRmse=10000.0 23 for iter in range(iterTimes): 24 fi=open(self.trainfile,‘r‘) 25 for line in fi: 26 content=line.split(‘::‘) 27 user=int(content[0])-1 28 item=int(content[1])-1 29 rating=float(content[2]) 30 pscore=self.predict(self.av,self.bu[user],self.bi[item],self.pu[user],self.qi[item]) 31 eui=rating-pscore 32 self.bu[user]+=self.learningRate*(eui-self.regularization*self.bu[user]) 33 self.bi[item]+=self.learningRate*(eui-self.regularization*self.bi[item]) 34 temp=self.pu[user] 35 self.pu[user]+=self.learningRate*(eui*self.qi[item]-self.regularization*self.pu[user]) 36 self.qi[item]+=self.learningRate*(temp*eui-self.regularization*self.qi[item]) 37 fi.close() 38 curRmse=self.test(self.av,self.bu,self.bi,self.pu,self.qi) 39 print "Iteration %d times,RMSE is : %f" % (iter+1,curRmse) 40 if curRmse>preRmse: 41 print "The best RMSE is : %f" % (preRmse) 42 break 43 else: 44 preRmse=curRmse 45 46 def test(self,av,bu,bi,pu,qi): 47 rmse=0.0 48 cnt=0 49 fi=open(self.testfile) 50 for line in fi: 51 cnt+=1 52 content=line.split(‘::‘) 53 user=int(content[0])-1 54 item=int(content[1])-1 55 score=float(content[2]) 56 pscore=self.predict(av,bu[user],bi[item],pu[user],qi[item]) 57 rmse+=(score-pscore)**2 58 fi.close() 59 return np.sqrt(rmse/cnt) 60 61 def predict(self,av,bu,bi,pu,qi): 62 pscore=av+bu+bi+np.dot(pu,qi) 63 if pscore<1: 64 pscore=1 65 elif pscore>5: 66 pscore=5 67 return pscore 68 69 if __name__==‘__main__‘: 70 s=SVD("train.dat","test.dat") 71 s.train() # Iteration 24 times,RMSE is : 0.854743
1 # To convert train.dat and test.dat from ratings.dat. 2 import numpy as np 3 f=open("ratings.dat",‘r‘) 4 a=[line for line in f] 5 n=len(a) 6 tn=int(n*0.8) 7 np.random.shuffle(a) 8 d=open("train.dat",‘w‘) 9 [d.write(a[i]) for i in range(tn)] 10 d.close() 11 d=open("test.dat",‘w‘) 12 [d.write(a[i]) for i in range(tn,n)] 13 d.close()
标签:tor 参数 turn 最优 好处 函数 shu imp alt
原文地址:http://www.cnblogs.com/qw12/p/6095522.html

































