标签:sleep second span 自己 代码实现 git pat 机器 find
很早前就想用 Golang 写点“实用的”东西,兴趣不是目的,学总归要致用。而《Go语言圣经》中有一些例子比较有实际意义,譬如爬虫。
刚好我对电影还比较有兴趣,且习惯性地在下或看某部电影前都会去豆瓣看看评分,所以我想,何不撸个小爬虫,来遍历豆瓣的所有电影页面以采集电影信息并按评分由高到低来排个序看看有哪些高评分电影我还没看过呢?
趁自己不瞎忙,索性撸起来。
代码实现基本上还是参考圣经里的那套。而作为爬虫,自然免不了要引入 goquery 这样的三方库,只是我还不熟 jQuery 里的那些概念等东西,以致提取譬如电影类型等信息的做法或不科学,后面再修正吧。
初版代码如下。
// Top500DouBanMovieSpider project main.go
package main
import (
"DouBanMoviePageParser"
"MovieRecHelper"
"bufio"
"fmt"
"helperutils"
"log"
"math/rand"
"os"
"runtime"
"sync"
"time"
)
var cancel = make(chan struct{})
func cancelled() bool {
select {
case <-cancel:
return true
default:
return false
}
}
func init() {
go func() {
os.Stdin.Read(make([]byte, 1))
close(cancel)
}()
}
var tokens = make(chan struct{}, 2)
func parsePage(url string) (ret DouBanMoviePageParser.MovieInfo, ok bool) {
if cancelled() {
ok = false
return
}
tokens <- struct{}{}
defer func() {
<-tokens
}()
if ok = DouBanMoviePageParser.ParseMoviePage(url, "动作", &ret); ok {
time.Sleep(time.Duration(rand.Intn(5)+7) * time.Second)
}
return
}
func main() {
timeBegin := time.Now()
worklist := make(chan []string)
pendingNum := 1
go func() {
// worklist <- os.Args[1:]
worklist <- []string{`https://movie.douban.com/subject/1304102`}
}()
ticker := time.NewTicker(time.Second * 10)
go func() {
for range ticker.C {
log.Printf("Num of Goroutines: %d\n", runtime.NumGoroutine())
}
}()
movies := make(map[string]MovieRecHelper.MovieRec)
recs := make(chan DouBanMoviePageParser.MovieInfo)
go func() {
for rec := range recs {
movies[rec.Name] = MovieRecHelper.MovieRec{rec.Url, rec.Score}
}
}()
var wg sync.WaitGroup
seen := make(map[string]bool)
for ; pendingNum > 0; pendingNum-- {
if cancelled() {
log.Println("Break for!")
break
}
list := <-worklist
for _, link := range list {
if cancelled() {
log.Println("Break range!")
break
}
if !seen[link] {
seen[link] = true
pendingNum++
wg.Add(1)
go func(url string) {
defer wg.Done()
if info, ok := parsePage(url); ok {
worklist <- info.LinkedUrls
recs <- info
} else {
// fmt.Println("FAIL!")
worklist <- []string{}
}
}(link)
}
}
}
log.Println("Wait...")
wg.Wait()
fmt.Printf("Crawl completed! Elapsed time: %f, Num of Action Movies: %d\n", time.Since(timeBegin).Hours(), len(movies))
log.Println("Stop ticker")
ticker.Stop()
log.Println("Sort")
ss := MovieRecHelper.NewScoreSorter(movies)
ss.Sort()
log.Println("Create file")
f, err := os.Create(helperutils.GetAppPath() + "Top500ActionMoviesFromDouBan.txt")
helperutils.CheckError(err)
defer f.Close()
fw := bufio.NewWriter(f)
n := len(ss.Names)
if n > 500 {
n = 500
}
log.Println("Write file")
for i := 0; i < n; i++ {
_, err = fw.WriteString(fmt.Sprintf("%-3d\t%-70s\t%s\t%s\r\n", i+1, ss.Names[i], ss.Recs[i].Score, ss.Recs[i].Url))
helperutils.CheckError(err)
}
fw.Flush()
log.Println("Exit.")
}
于是它欢快地跑了起来(喔,在调试了数次后):
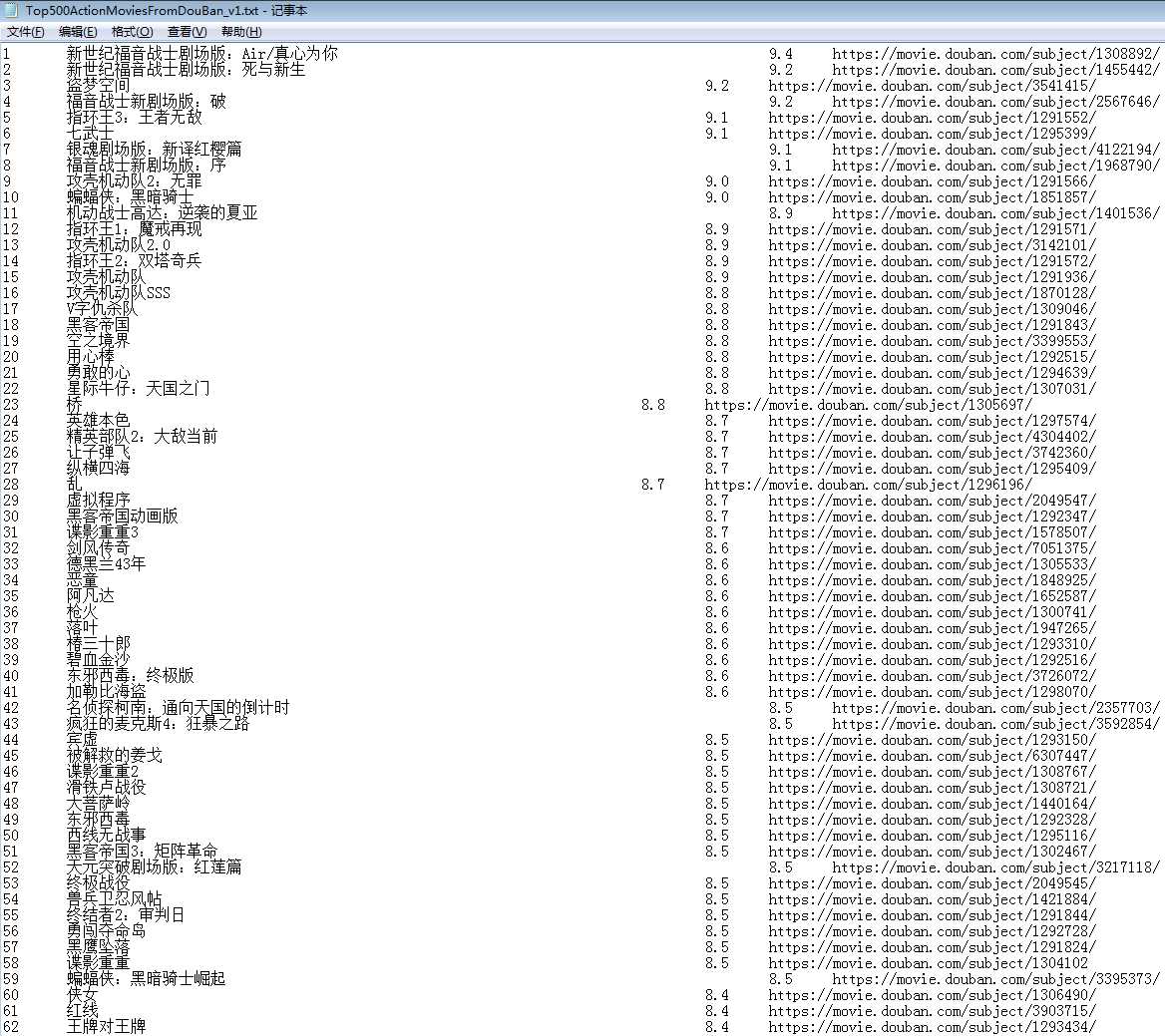
只是,这份初版代码还是有些乱,而且无法设定譬如抓取间隔、目标电影类型等选项,而刚好我已将 vs code 下载到了本地,索性就以它来写 Golang 看看吧。
代码结构如下。
完整代码如下。
package DoubanMoviePageParser
import (
"strings"
"github.com/PuerkitoBio/goquery"
)
// MovieInfo struct
type MovieInfo struct {
Name string
URL string
Score string
LinkedUrls []string
}
func isDesiredMovieType(doc *goquery.Document, movieType string) bool {
sel := doc.Find("#info").Find("span")
if sel == nil {
return false
}
l := len(sel.Nodes)
for i := 10; i < l; i++ {
s := sel.Eq(i).Text()
if s != "官方网站:" {
if s == movieType {
return true
}
} else {
break
}
}
return false
}
// ParseMoviePage parse specified movie page
func ParseMoviePage(url, movieType string, info *MovieInfo) bool {
doc, err := goquery.NewDocument(url)
if err != nil {
return false
}
movieType = strings.ToLower(movieType)
if movieType != "all" && !isDesiredMovieType(doc, movieType) {
return false
}
// Movie Name
sel := doc.Find("h1").Find("span").Eq(0)
if sel == nil {
return false
}
name := sel.Text()
n := strings.Index(name, " ")
if n > 0 {
info.Name = name[:n]
} else {
info.Name = name
}
// Movie Url
info.URL = url
// Movie Score
sel = doc.Find(".ll.rating_num")
if sel == nil {
return false
}
info.Score = sel.Text()
// Recommendations
doc.Find(".recommendations-bd dl dd").Each(func(i int, s *goquery.Selection) {
lnk, _ := s.Find("a").Attr("href")
lnk = strings.TrimRight(lnk, "?from=subject-page")
if lnk != "" {
info.LinkedUrls = append(info.LinkedUrls, lnk)
}
})
return true
}
package DoubanMoviePageParser
import (
"sort"
)
// MovieRec struct
type MovieRec struct {
URL string
Score string
}
// ScoreSorter struct
type ScoreSorter struct {
Names []string
Recs []MovieRec
}
// NewScoreSorter function generates object pointer of ScoreSorter
func NewScoreSorter(m map[string]MovieRec) *ScoreSorter {
ss := &ScoreSorter{
Names: make([]string, 0, len(m)),
Recs: make([]MovieRec, 0, len(m)),
}
for k, v := range m {
ss.Names = append(ss.Names, k)
ss.Recs = append(ss.Recs, v)
}
return ss
}
// Sort sort ScoreSorter
func (ss *ScoreSorter) Sort() {
sort.Sort(ss)
}
func (ss *ScoreSorter) Len() int {
return len(ss.Names)
}
func (ss *ScoreSorter) Less(i, j int) bool {
return ss.Recs[i].Score > ss.Recs[j].Score
}
func (ss *ScoreSorter) Swap(i, j int) {
ss.Names[i], ss.Names[j] = ss.Names[j], ss.Names[i]
ss.Recs[i], ss.Recs[j] = ss.Recs[j], ss.Recs[i]
}
// 参考命令行: DoubanMoviePageSpider -numCrawlGoroutine=2 -baseInterval=7 -randomInterval=5 -movieType=动作 -saveNum=500 -tickerInterval=10 https://movie.douban.com/subject/1304102
package main
import (
"DoubanMoviePageParser"
"bufio"
"flag"
"fmt"
"helperutils"
"log"
"math/rand"
"os"
"runtime"
"time"
)
var numCrawlGoroutine int
var baseInterval, randomInterval int
var movieType string
var saveNum int
var tickerInterval int
var cancel = make(chan struct{})
func cancelled() bool {
select {
case <-cancel:
return true
default:
return false
}
}
func init() {
go func() {
os.Stdin.Read(make([]byte, 1))
close(cancel)
}()
}
func parsePage(url string) (ret DoubanMoviePageParser.MovieInfo, ok bool) {
if cancelled() {
ok = false
return
}
if ok = DoubanMoviePageParser.ParseMoviePage(url, movieType, &ret); ok && !cancelled() {
time.Sleep(time.Duration(rand.Intn(randomInterval)+baseInterval) * time.Second)
}
return
}
func parseFlag() {
flag.IntVar(&numCrawlGoroutine, "numCrawlGoroutine", 2, "最大抓取线程数")
flag.IntVar(&baseInterval, "baseInterval", 7, "最短抓取间隔")
flag.IntVar(&randomInterval, "randomInterval", 5, "抓取随机间隔")
flag.StringVar(&movieType, "movieType", "动作", "目标电影类型(all: 不限)")
flag.IntVar(&saveNum, "saveNum", 500, "保存数目")
flag.IntVar(&tickerInterval, "tickerInterval", 10, "Goroutine数目报告间隔(单位: s)")
flag.Parse()
if numCrawlGoroutine < 1 {
panic("请设定不小于 1 的最大抓取线程数!")
}
if baseInterval < 1 {
panic("请设定不小于 1 的最短抓取间隔!")
}
if randomInterval < 2 {
panic("请设定合法的抓取随机间隔!")
}
if saveNum < 1 {
panic("不合法的保存数目设置!")
}
if tickerInterval < 5 {
panic("请设定不小于 5 的报告间隔!")
}
if len(flag.Args()) == 0 {
panic("请指定起始抓取网页地址!")
}
}
func saveToFile(ss *DoubanMoviePageParser.ScoreSorter) {
fileName := fmt.Sprintf("Top%dMoviesFromDouBan.txt", saveNum)
f, err := os.Create(fileName)
helperutils.CheckError(err)
defer f.Close()
fw := bufio.NewWriter(f)
n := len(ss.Names)
if n > saveNum {
n = saveNum
}
for i := 0; i < n; i++ {
_, err = fw.WriteString(fmt.Sprintf("%-3d\t%-70s\t%s\t%s\r\n", i+1, ss.Names[i], ss.Recs[i].Score, ss.Recs[i].URL))
helperutils.CheckError(err)
}
fw.Flush()
}
func main() {
// 解析命令行参数
parseFlag()
// 初始化待抓取地址列表
worklist := make(chan []string)
pendingNum := 1
go func() {
worklist <- flag.Args() // []string{`https://movie.douban.com/subject/1304102`}
}()
// 创建 Ticker 用以报告当前 Goroutine 数目
ticker := time.NewTicker(time.Duration(tickerInterval) * time.Second)
go func() {
for range ticker.C {
log.Printf("Num of Goroutines: %d\n", runtime.NumGoroutine())
}
}()
// 此管道用以"通信"抓取到的电影信息
recs := make(chan DoubanMoviePageParser.MovieInfo)
// 暂存抓取到的所有电影信息
movies := make(map[string]DoubanMoviePageParser.MovieRec)
go func() {
for rec := range recs {
movies[rec.Name] = DoubanMoviePageParser.MovieRec{URL: rec.URL, Score: rec.Score}
}
}()
// 最大同时抓取 Goroutine 数
tokens := make(chan struct{}, numCrawlGoroutine)
// 确保所有抓取 Goroutine 都完成
// var wg sync.WaitGroup
// 确保只抓取未爬过的 URL
seen := make(map[string]bool)
log.Println("电影页面抓取已启动...")
timeBegin := time.Now()
for ; pendingNum > 0; pendingNum-- {
if cancelled() {
break
}
list := <-worklist
for _, link := range list {
if cancelled() {
break
}
if !seen[link] {
seen[link] = true
pendingNum++
// wg.Add(1)
go func(url string) {
// defer wg.Done()
tokens <- struct{}{}
defer func() {
<-tokens
}()
if info, ok := parsePage(url); ok {
worklist <- info.LinkedUrls
recs <- info
} else {
// 确保爬虫被封时不会出现死锁
worklist <- []string{}
}
}(link)
}
}
}
log.Println("电影页面地址遍历完毕, 等待抓取结束...")
// wg.Wait()
fmt.Printf("抓取结束。耗时: %.1fmin, 共抓取电影页面数: %d\n", time.Since(timeBegin).Minutes(), len(movies))
ticker.Stop()
// 按评分由高到低排序
ss := DoubanMoviePageParser.NewScoreSorter(movies)
ss.Sort()
// 保存至本地存储
saveToFile(ss)
// Done
log.Println("The End.")
}
然后 DoubanMoviePageSpider -movieType=all https://movie.douban.com/subject/1304102:
抓取一小时后即停止,得出如下结果:
基本上,先前的小目标初步实现了,虽然要改进的地方还很多,譬如代码结构,或许后面会作改进吧。
注:
1)、不要设置较短的抓取间隔,很容易被豆瓣封
2)、在我这中下配置机器上使用 VS Code,初步感觉还不错,只是偶尔会卡顿,且其占用资源似乎多了点(见上面截图),或许我过于苛求了罢~
标签:sleep second span 自己 代码实现 git pat 机器 find
原文地址:http://www.cnblogs.com/ecofast/p/6102499.html