标签:err 小数 高效 打印 过程 upper 提示 应该 无符号
本章问题
1.C语言缺少显示的字符串数据类型,这是一个优点还是一个缺点?
answer:

(这个问题存在争论(尽管我有一个结论))目前这个方法的优点是字符数组的效率和访问的灵活性,它的缺点是有可能引起错误,数组溢出,下标越界,不能改变任何用于保存字符串的数组的长度等。我的结论是从现代的面向对象的奇数引出的,字符串类毫无例外的包括了完整的错误检查,用于字符串的动态内存分配和其他一些防护措施,这些措施都会造成效率上的损失,但是,如果程序无法运行,效率再高也没有什么意义,况且,现在软件项目的规模比设计C语言的时代要大得多。因此,在数年前,缺少显示的字符串类型还能被看成是一个优点,但是,由于这个方法内在的危险性,所以使用现代的高级的完整的字符串类还是物有所值的,如果C程序员愿意循规蹈矩的使用字符串也可以获得这些优点。
2.strlen函数返回一个无符号量(size_t),为什么这里无符号值比有符号值更合适?但返回无符号值其实也有缺点,为什么?
answer:It is more appropriate because the length of a string simply annot be vegative,Also,using an unsigned value allows longer string lengths(which would be negative in a signed quantity)to be represented.It is less appropriate becuase arithmetic involving unsinged expressions can yield unexpected results,The "advantage" of being able to report the length of longer strings is only rarely of value:on machines with 16 bit integers,it is needed only for strings exceeding 2147483647 bytes in length(which is rare indeed).
(更合适是因为一个字符串的长度不可能是个负数,而且无符号数的值允许字符串的长度更长,不适合是因为牵涉到算术运算时无符号表达四可能产生无法预料的结果,能够允许字符串的长度更长这个“优点”其实很少使用,因为在16位机器上的整型,可以有2147483647位的长度,但实际很少使用)
3.如果strcat和strcpy返回一个指向目标字符串末尾的指针,和事实上返回一个指向目标字符串起始位置的指针相比,有没有什么优点?
answer:Yes,then subsequent concatenations could be done more efficiently because the work of finding the end of the string would not need to be repeated.
(是的,指向目标字符串末尾的指针更高效,因为找到字符串的末尾的指针不需要重复工作)
4.如果从数组x复制50个字节到数组y,最简单的方法是什么?
answer:

(使用memory库函数,重要的是不要使用任何的str--函数,因为它们会在遇见第一个NUL字节的时候停止,如果你自己写一个循环要更复杂,而且在效率上几乎不可能超过这个函数)
5.假定你有一个名叫buffer的数组,它的长度为BSIZE个字节,你用下面这条语句把一个字符串复制到这个数组:
strncpy( buffer, some_other_string,BSIZE-1);
它能不能保证buffer中的内容是个有效的字符串?
answer:Only if the last character in the array is already NUL,A string must be terminated with a NUL byte,and strncpy does not guarantee that this will occur,However,the statement does not let strncpy change the last position in the array,so if that contains a NUL byte(either through an assignment or by the default initialization of static variables),then the result will be a string.
(只有字符 数组的最后一个字符确实是NUL的时候,一个字符串必须以NUL字节结尾,strncpy不会检查有效性,然而,语句不会让strncpy改变数组的最后一个位置,所以如果 最后一个位置是NUL字节(通过一个赋值或默认静态变量的初始化),它的结果将会是个字符串
6.用下面这种方法
if(isalpha(ch))
取代下面这种显式的测试有什么优点?
answer:First,the former will work regardless of the character set in use,The latter will work with the ASCII character set but will fail with the EBCDIC character set,Second,the former will work properly whether or not the locale has been changed;the latter may not.
(首先,前者不管在什么字符集中都能工作,而后者只能工作运行在ASCII字符集中,而在EBCDIC编码中不能使用,第二,不管字母的区域是否改变前者都能正常运行,而后者不能)
7.下面的代码怎样简化?
for(p_str = message; *p_str != ‘\0‘; p_str++){ if(islower(*p_str)) *p_str = toupper(*p_str); }
answer:
register int ch; ... for(pstring = message; (ch = *pstring) != ‘\0‘;) *pstring++ = toupper(ch);
8.下面的表达式有何不同?
memchr(buffer,0,SIZE) - buffer; strlen(buffer);
answer:

(如果缓冲区包含了一个字符串,memchr将在内存中buffer的起始位置查找第一个包含0的字节并返回一个指向该字节的指针,将这个指针减去buffer获得存储在这个缓冲区中的字符串长度,strlen完成相同的任务,不过strlen的返回值是个无符号类型的值,而指针减法应该是个有符号的值。但是,如果缓冲区内的数据不是以NUL结尾,memchr函数将返回一个NULL指针,将这个值减去buffer将产生一个无意义的结果,另一方面,strlen函数将在数组的后面继续查找,知道最终发现一个NUL字节。尽管可以使用strlen函数获得相同的结果,但一般而言,使用字符串函数不可能查找到NUL字节,因为这个值用于终止字符串,如果它是你需要查找的字节,你应该使用内存操纵函数。)
本章练习
1.编写一个程序,从标准输入读取一些字符,并统计下列各类字符所占的百分比。
控制字符
空白字符
数字
小写字母
大写字母
标点符号
不可打印的字符
请使用在ctype.h头文件中定义的字符分类函数
answer:
#include <stdio.h> #include <ctype.h> int main() { int ch; float cntrl = 0; float space = 0; float digit = 0; float lower = 0; float upper = 0; float punct = 0; float unprint = 0; float total = 0; while((ch = getchar()) != EOF){ total++; if(iscntrl(ch)) cntrl++; if(isspace(ch)) space++; if(isdigit(ch)) digit++; if(islower(ch)) lower++; if(isupper(ch)) upper++; if(ispunct(ch)) punct++; if(!isprint(ch)) unprint++; } printf("control character is %% %3.0f\n",100 * (cntrl/total)); printf("space character is %% %3.0f\n",100 * (space/total)); printf("digit character is %% %3.0f\n",100 * (digit/total)); printf("lower character is %% %3.0f\n",100 * (lower/total)); printf("upper character is %% %3.0f\n",100 * (upper/total)); printf("punct character is %% %3.0f\n",100 * (punct/total)); printf("not print character is %% %3.0f\n",100 * (unprint/total)); }
2.编写一个名叫my_strlen的函数,它类似与strlen函数,但它能够处理由于使用strn--函数而创建的未以NUL字节结尾的字符串。你需要向函数传递一个参数,它的值就是保存了需要进行长度测试的字符串的数组的长度。
answer:
#include <stdio.h> #include <stddef.h> size_t my_strlen(char *string, int n) { register size_t count = 0; while(*string++ != ‘\0‘ && n-- > 0) count++; return count; }
3.编写一个名为my_strcpy的函数,它类似与strcpy函数,但它不会溢出目标数组。复制的结果必须是一个真正的字符串。
answer:
char *my_strcpy(char *dst, char *src, int size){ strncpy(dst, src, size); *(dst + size - 1) = ‘\0‘; return dst; }
4.编写一个名叫my_strcat的函数,它类似于strcat函数,但它不会溢出目标数组,它的结果必须是一个真正的字符串。
answer:
char *my_strcat(char *dst, char *src, int size){ size_t length = size - 1 - my_strlen(dst,size); if(length > 0){ strncat(dst,src,length); *(dst + size - 1) = ‘\0‘; } return dst; }
5.编写函数
void my_strncat(char *dest, char *src, int dest_len);
它用于把src中的字符串连接到dest中原有的字符串末尾,但它保证不会溢出长度为dest_len的dest数组,和strncat函数不同,这个函数也考虑原先存在于dest数组的字符串长度,因此能够保证不会超越数组边界。
void my_strncat(char *dest, char src, int dest_len) { register int len; len = strlen(dst); dest_len -= len + 1; if(dest_len > 0) strncat(dest, src, dest_len); }
6.编写一个名叫my_strcpy_end的函数取代strcpy,它返回一个指向目标字符串末尾的指针(也就是说,指向NUL字节的指针),而不是返回一个指向目标字符串起始位置的指针。
answer:
//两种方法 char *my_strcpy_end(char dst,char src) { strcpy(dst,src); int length = strlen(dst); dst += length; return dst; } char *my_strcpy_end(char dst,char src) { while(*src != ‘\0‘) *dst++ = *src++; return dst - 1; }
7.编写一个名叫my_strrchr的函数,它的原型如下:
char *my_strrchr(char const *str,int ch);
这个函数类似与strchr函数,只是它返回的是一个指向ch字符在str字符串中最后一次出现的位置的指针。
answer:
char *my_strrchr(char const *str,int ch) { char *p = strchr(str,ch); while(*p != NULL){ str = p++; p = strchr(str,ch); } return str; }
8.编写一个名叫my_strnchr的函数,它的原型如下:
char *my_strnchr(char comst *str, int ch, int which);
这个函数类似于strchr,但它的第三个参数指定ch字符在str字符串中第几次出现,例如,第三个参数为1,这个函数的功能就和strchr一样,如果参数为2,这个函数就返回一个指向ch字符在str字符串中第二次出现的位置的指针。
answer:
char *my_strnchr(char const *str, int ch, int which) { char *p = strchr(str,ch); while(*p != NULL && --which > 0){ str = p++; p = strchr(str,ch); } return p; }
9.编写一个函数,它的原型如下:
int count_chars(char const *str,char const *chars);
函数应该在第一个参数中进行查找,并返回匹配第二个参数所包含的字符的数量。
int count_chars(char const *str, char const *chars) { int count = 0; while((str = strnbrk(str,chars)) != NULL){ count++; str++; } return count; }
10.编写函数
int palindrome(char *string);
如果参数字符串是个回文,函数就返回真,否则返回假。回文就是指一个字符串从左向右和从右向左读是一样的。函数应该忽略所有的非字母字符,而且在进行字符比较时不用区分大小写。
answer:
#include <stdio.h> #include <ctype.h> int palindrome(char *string) { char *p = string; char *q = string; while(*q != ‘\0‘) q++; q--; while(p <= q){ while(!isalpha(*p)) p++; while(!isalpha(*q)) q--; *p = tolower(*p); *q = tolower(*q); if(p > q) break; if(*p != *q) return 0; p++; q--; } return 1; }
11.编写一个程序,对标准输入进行扫描,并对单词“the”出现的次数进行计数,进行比较时应该区分大小写,所以“The”和“THE”并不计算在内。你可以认为各单词由一个或多个空格字符分隔,而且输入行在长度上不超过100个字符,计数结果应该写到标准输出上。
#include <stdio.h> #include <string.h> #include <stdlib.h> int count_the(char *string) { int count = 0; char whitespace[] = " \t\f\r\v\n"; char *p; for(p = strtok(string,whitespace); p != NULL; p = strtok(NULL,whitespace)){ if(strcmp(p,"the") == 0) count++; } return count; } int main() { char string[100]; gets(string); printf("\"the\" is appeared %d times",count_the(string)); return 0; }
12.有一种技巧可以对数据进行加密,并使用一个单词作为它的密钥。下面是它的工作原理:首先,选择一个单词作为密钥,如TRAILBLAZERS。如果单词中包含有重复的字母,只保留第一个,其余几个丢弃。现在,修改过那个单词列于字母表的下面,如下所示:
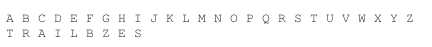
最后,底下那行字母表中剩余的字母填充完整:
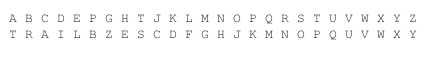
在对信息进行加密时,信息中的每个字母被固定于顶上那行,并用下面那行的对应字母一一取代原文的字母。因此,使用这个密钥,ATTACK AT DAWN(黎明时攻击)就会被加密为TPPTAD TP ITVH。这个题材共有三个程序(包括下面两个练习),在第一个程序中,你需要编写函数:
int prepare_key(char *key);
它接受一个字符串参数,它的内容就是需要使用的密钥单词,函数根据上面描述的方法把它转换成一个包含编好码的字符数组。假定key参数是个字符数组,其长度至少可以容纳27个字符。函数必须把密钥中的所有字符要么转换成大写,要么转换成小写(随你选择),并从单词中去除重复的字母,然后再用字母表中剩余的字母按照你原先所选择的大小写形式填充到key数组中去,如果处理成功,函数将返回一个真值,如果key参数为空或包含任何非字母字符,函数将返回一个假值。
answer:
#include <stdio.h> #include <string.h> #include <ctype.h> char character[27] = "abcdefghijklmnopqrstuvwxyz"; //delete the char *ch for char *string void del_ch(char *string, char *ch) { char *p = ch + 1; while(*p != ‘\0‘){ *ch++ = *p++; } *ch = *p; } int init_key(char *key) { while(*key != ‘\0‘){ if(!isalpha(*key)) return 0; *key = tolower(*key); key++; } return 1; } void delete_rech(char *key) { char ch; char *p,*q; while((ch = *key++) != ‘\0‘){ while((p = strchr(key, ch)) != NULL){ del_ch(key,p); } } } void fill_key(char *key) {
char string[27]; strncpy(string,character,27); char *p; while((p = strpbrk(string,key)) != NULL){ del_ch(string,p); } strcat(key,string);
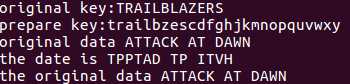
} int prepare_key(char *key) { if(*key == ‘\0‘) return 0; //is alpha? and to lower if(init_key(key) == 0) return 0; //delete the character which is repeat delete_rech(key); //fill the key fill_key(key); return 1; } int main() { char key[27] = "TRAILBLAZERS"; printf("original key:%s\n",key); if(prepare_key(key) == 0) printf("the key is error!\n"); else printf("prepare key:%s\n",key); return 0; }
运行结果:

13.编写函数
void encrypt(char *data, char const *key);
它使用前题prepare_key函数所产生的密钥对data中的字符进行加密。data中的非字母字符不作修改,但字母字符则用密钥所提供的编过码的字符一一取代源字符。字符的大小写状态应该保留。
answer:
void encrypt(char *data, char const *key) { char *p = data; while(*p != ‘\0‘){ if(islower(*p)){ *p = key[*p - ‘a‘]; }else if(isupper(*p)){ char ch = tolower(*p); ch = key[ch - ‘a‘]; *p = toupper(ch); } p++; } }
运行结果:

14.这个问题的最后部分就是编写函数
void decrypt(char *data, char const *key);
它接受一个加过密的字符串为参数,它的任务是重现原来的信息,除了它是用于解密之外,它的工作原理应该与encrypt相同。
answer:
void decrypt(char *data, char const *key) { char *p = data; while(*p != ‘\0‘){ if(islower(*p)){ char *k = strchr(key,*p); int num = k - key; *p = character[num]; }else if(isupper(*p)){ char ch = tolower(*p); char *k = strchr(key,ch); int num = k - key; ch = character[num]; *p = toupper(ch); } p++; } }
运行结果:
15.标准I/O库并没有提供一种机制,打印大整数时逗号进行分隔。在这个练习中,你需要编写一个程序,为美元数额的打印提供这个功能。函数把一个数字字符串(代表以美分为单位的金额)转换为美元形式,如下面的例子所示:

下面是函数的原型:
void dollars(char *dest, char const *src);
src将指向需要被格式化的字符(你可以假定它们都是数字)。函数应该像上面例子所示的那样对字符进行格式化,并把结果字符串保存到dest中。你应该保证你所创建的字符串以一个NUL字节结尾。src的值不应被修改。你应该使用指针而不是下标。
提示:首先找到第2个参数字符串的长度,这个值有助于判断逗号应插入到什么位置,同时,小数点和最后两位数字应该是唯一需要你进行处理的特殊情况。
answer:
void dollars(char *dest, char const *src) { int len; if(dest == NULL || src == NULL) return ; *dest++ = ‘$‘; len = strlen(src); if(len >= 3){ int i; for(i = len - 3; i > 0){ *dest++ = *src++; if(--i > 0 && i % 3 == 0) *dest++ = ‘,‘; } } else *dest++ = ‘0‘; *dest++ = ‘.‘; *dest++ = len < 2 ? ‘0‘ : *src++; *dest++ = len < 1 ? ‘0‘ : *src; *dest = 0; }
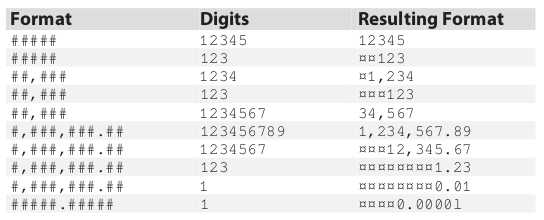
16.这个程序与前一个练习相似,但它更为通用。它按照一个指定的格式字符串对一个数字字符串进行格式化,类似许多BASIC编码器所提供的“print using”语句。函数的原型如下:
int format(char *format_string, char const *digit_string);
digit_string中的数字根据一开始在format_string中找到的字符从右到左逐个复制到format_string中。注意被修改后的format_string就是这个处理过程的结果,当你完成时,确定format_string依然是以NUL字节结尾的。根据格式化过程中是否出现错误,函数返回真或假。
格式字符串可以包括下列字符:
# 在两个字符串中都是从右向左进行操作,格式字符串中的每个#字符都被数字字符串中的下一个数字取代,如果数字字符串用完,格式字符串中所有剩余的#字符由空白代替(但存在例外,请参见下面对小数点的讨论)。
, 如果逗号左边至少有一位数字,那么它就不作修改。否则它由空白取代。
. 小数点始终作为小数点存在。如果小数点左边没有一位数字,那么小数点左边的那个位置以及右边直到有效数字为止的所有位置都由0填充。
下面的例子说明了对这个函数的一些调用的结果。符号?用于表示空白。
为了简化这个项目,你可以假定格式字符串所提供的格式总是正确的。最左边至少有一个#符号,小数点和逗号的右边也至少有一个#符号。而且逗号绝不会出现在小数点的右边,你需要进行检查的错误只有:
a 数字字符串中的数字多余格式字符串中的#符号
b 数字字符串为空
发生这两种错误时,函数返回假,否则返回真。如果数字字符串为空,格式字符串在返回时应未作修改。如果你使用指针而不是下标来解决问题,你将会学到更多的东西。
提示:开始时让两个指针分别指向格式字符串和数字字符串末尾,然后从右向左进行处理,对于作为参数传递给函数的指针,你必须保留它的值,这样你就可以判断是否到达了这些字符串的左端。
int format(char *format_string, char const *digit_string) { char *fs, *ds; fs = format_string + strlen(format_string) - 1; ds = digit_string + strlen(digit_string) - 1; if(digit_string == NULL) return 0; while(fs >= format_string){ if(ds >= digit_string){ switch(*fs){ case ‘#‘: *fs-- = *ds--; break; case ‘.‘: fs--; break; case ‘,‘: fs--; break; } }else{ char *p = strchr(format_string,‘.‘); if(p == NULL){ *fs-- = ‘ ‘; }else{ if(fs < p - 1) *fs-- = ‘ ‘; else if(fs == p) *fs-- = ‘.‘; else *fs-- = ‘0‘; } } } if(ds >= digit_string){ printf("digit_string more than format_string\n"); return 0; } return 1; }
答案给出的解法和上面我自己的解法有所不同,但是代码思路差别不大,不过不管是以上代码还是标准答案的代码都用到了两个比较:
fs >= format_string
ds >= digit_string
关于这个比较,存在一些问题,下面是标准答案给出的解释:

大意是说,这个测试是非法的,因为当它不满足while语句的时候,不管是ds(答案用的是digitp)指针还是fs(答案用的是patternp)指针都超出了数组最左边的范围,另一方面,它有可能(通常不可能)调用下面这个函数:
if(format(p_array+1,d_array+1))...
这种情况没有违反什么,有趣的部分在于指针的算术比较运算需要在合法的情况下工作,而上面显示的函数导致它在非法的情况下也能工作,事实上,只有一种情况函数的运行会失败,就是如果其中一个数组是从0这个内存位置开始的,从数组的开始实际覆盖的内存之前计算一个指针和从内存空间的末尾产生的指针,这些都会使比较失败。在大多数机器上这种情况将不会发生,因为0代表NULL指针,所以编译器不会把任何数据放到这里,然而,这仍然存在一个危险,标准允许NULL指针可以转换成任何类型的指针,即使在源代码中总是用0来代表NULL,在这种情况下,上面描述的情况可能会发生,会让调试变得困难。这个函数应该移除这个依赖性,这里给出的错误版本仅仅是引起讨论。
17.这个程序与前两个练习类似,但更加一般化了,它允许调用程序把逗号放在大数的内部,去除多余的前导0以及提供一个浮动的美元符号等。
这个函数的操作类似于IBM370机器上的Edit和Mark指令。它的原型如下:
char *edit(char *pattern, char const *digits);
它的基本思路很简单,模式(pattern)就是一个图样,处理结果看上去应该向它的样子。数字字符串中的字符根据这个图样所提供的方式从左向右复制到模式字符串。数字字符串的第一位有效数字很重要,结果字符串中所有在第一位有效数字之前的字符都由一个“填充”字符代替,函数将返回一个指针,它所指向的位置正是第一位有效数字存储在结果字符串中的位置(调用程序可以根据这个返回指针,把一个浮动美元符号放在这个值左边的毗邻位置)。这个函数的输出结果就像支票上打印的那样--这个值左边所有的空白符由星号或其他字符填充。
在描述这个函数的详细处理过程之前,看一些这个操作的例子是很有帮助的,为了清晰起见,符号?用于表示空格。结果字符串中带下划线的那个数字就是返回值指针所指想的字符(也就是第一个有效数字),如果结果字符串中不存在带下划线的字符,说明函数返回值是个NULL指针。
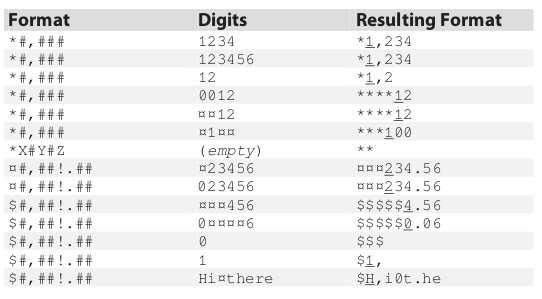
现在让我们来讨论这个函数的细节。函数的第一个参数就是模式,模式字符串的第一个字符就是“填充字符”。函数使数字字符串修改模式字符串中剩余的字符来产生结果字符串。在处理过程中,模式字符串将被修改,输出字符串不可能比原先的模式字符串更长,所以不存在溢出第一个参数的危险(因此不需要对此进行检查)。
模式是从左向右逐个字符进行处理的。每个位于填充字符串后面的字符的处理结果将是三中选一
a 保持原样不被修改
b 被一个数字字符串中的字符代替
c 被填充字符取代
数字字符串也是从左向右进行处理的,但它本身在处理过程中绝不会被修改,虽然它被称为“数字字符串”,但它也可以包含任何其他字符,如上面的例子之一所示,但是,数字字符串中的空格应该和0一样对待(它们的处理的结果相同)。函数必须保持一个“有效标识”,用于标识是否有任何有效数字从数字字符串复制到模式字符串。数字字符串中的前导空格和前导0并非有效字符,其余的字符都是有效字符。
如果模式字符串或数字字符串有一个是NULL,那就是个错误,在这种情况下,函数应该立即返回NULL。
下面这个表列出了所有需要的处理过程。列标题“signif”就是有效标识,“模式”和“数字”分别代表模式字符串和数字字符串的下一个字符。表的左边列出了所有可能出现的不同情况,表的右边描述了每种情况需要处理的过程,例如如果下一个模式字符是“#”,有效标识就设为假,数字字符串的下一个字符是‘0’,所以用一个填充字符代替模式字符串中的#字符,对有效标识不作修改。
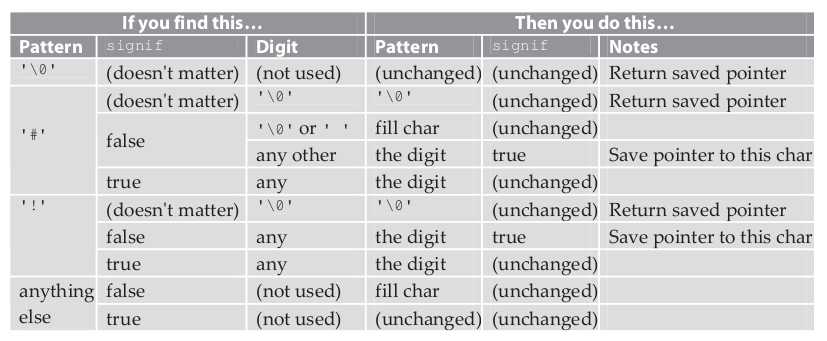
answer:
char *edit(char *pattern, char const *digits) { char fillch = *pattern++; int signif = 0; char *sign; char *ps = pattern; char *ds = digits; if(pattern == NULL || digits == NULL) return NULL; while(*ps != ‘\0‘){ switch(*ps){ case ‘\0‘: break; case ‘#‘: if(*ds == ‘\0‘) *ps = ‘\0‘; else if(signif == 0){ if(*ds == ‘0‘ || *ds == ‘ ‘){ ds++; *ps = fillch; } else{ *ps = *ds++; signif = 1; sign = ps; } }else *ps = *ds++; break; case ‘!‘: if(*ds == ‘\0‘) *ps = ‘\0‘; else if(signif == 0){ *ps = *ds++; signif = 1; sign = ps; }else *ps = *ds++; break; default: if(signif == 0) *ps = fillch; break; } ps++; } return sign; }
标签:err 小数 高效 打印 过程 upper 提示 应该 无符号
原文地址:http://www.cnblogs.com/monster-prince/p/6088861.html